RecSys Challenge 2019

Our data scientists and engineers love the challenges that their work presents to them on a daily basis and thrive in our agile environment where they can share their knowledge, learn from others, and work together to solve any problems that arise. We are always looking for ways to share the unique problem settings we encounter and to inspire a productive exchange on algorithm development and evaluation.
That is why we have partnered with researchers from TU Wien, Politecnico di Milano, and Karlsruhe Institute of Technology to launch the RecSys Challenge 2019, the annual data science challenge of the ACM Recommender Systems conference. In this challenge, we invite participants to dig deep into our data and come up with creative ideas to detect the intent of our users and build a click-prediction model that can be used to update the recommendation of accommodations. To this end, we have released a data set of user interactions on our website.
Why are we doing it?
We strongly believe in sharing knowledge not only internally, but also with the tech community around the world. This is one of the reasons why we support Open Source software through development and sponsorship. By organizing the RecSys Challenge 2019, we want to help bridge the gap between academia and industry by giving machine-learning researchers, students, and aspiring data scientists exposure to real-world data science problems and large data sets. This will not only provide a playground for researchers to test, benchmark, and improve their novel ideas and algorithms on real data sets, but will, in turn, give us the opportunity to learn and develop our algorithms further, based on the new ideas and approaches that this challenge will inspire.
What is the context of the challenge?
trivago is a global hotel search platform focused on reshaping the way travelers search for and compare hotels on our website and app. We have established 55 localized platforms in over 190 countries and provide access to over two million hotels, including alternative accommodations, with prices and availability from over 400+ booking sites and hotel chains.
Our users can narrow down their search by selecting filters and specifying the desired characteristics of their preferred accommodation. They can interact with the different offers presented to them and consume the aggregated information for each listing to make an informed decision and find their ideal place to stay. Once a choice is made, the users get redirected to the selected booking site to complete the booking. It is in the interest of all participants (traveler, advertising booking site, and trivago) to suggest suitable accommodations that fit the needs of the traveler.

Due to the nature of our domain, we face specific challenges that make it difficult to build predictive models and recommendation systems that are tailored to the needs of our visitors. Here are a few examples of the problems that trivago data scientists have to address:
- Users search for accommodations comparatively infrequently with sometimes long time intervals between their trips. Furthermore, user intent and preferences change over time and depend on the purpose of the trip (e.g. a business traveler who books accommodation for a weekend trip with her family).
- Booking accommodation is an expensive transaction. Visitors are price sensitive and careful when they make a decision. As the availability of the accommodations, the search criteria, and the actual pricing of the deals from the advertisers vary over time, the context of each search has to be taken into consideration.
- Information about the personal preferences of travelers is sparse. The service provided to our users is free of charge ─ users do not have to provide personal data or make an account in order to use the website.
What is new about the challenge/domain?
Classical approaches to build recommendation systems are not very well suited to address the challenges mentioned above. Many well-established methods like matrix factorization and collaborative filter variants compute recommendations based on data sets with aggregated information of users and their preferences. Consequently, they have a hard time delivering accurate predictions in extreme cold-start scenarios in which the majority of users can be considered new.
On the other hand, common click prediction techniques suffer from a lack of personalization and have no straightforward way to take into account the time-dependent nature of interaction sequences of users that allows updating recommendations in case of changing preferences. The new field of sequence-aware recommender systems addresses some of these issues, but is in its infancy and can benefit from large-scale datasets for algorithm development and evaluation.
We invite participants of the challenge to think outside of the box, be creative, and find a way to make use of the trail of implicit and explicit signals that users leave behind during their visit in the form of interactions with content, search refinements, and filter usage, to predict which accommodation the users will click on at the end of their trivago journey.
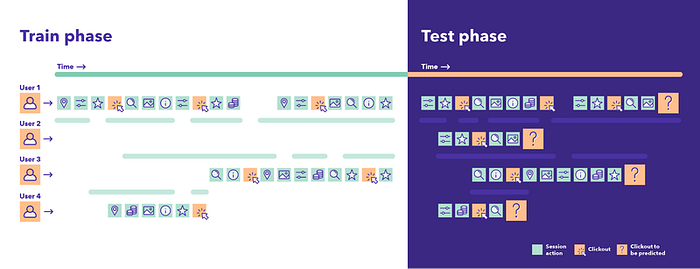
Who can do it?
Whether you’re a data scientist, developer, student or just an enthusiastic learner who’s interested in data problems, we encourage anyone to take on this challenge. To participate, you must register a team which consists of at least one person. The competition is running now and will be open until June 2019. If you’re interested in participating, feel free to register!

Can you see yourself working on challenges like this one every day? Check out our open positions!
Originally published by Jens Adamczak at tech.trivago.com on March 11, 2019.
