Teste de Hipóteses: o que significa, quais são os tipos e como realizar um teste de hipóteses
Texto escrito por Iryna Mireia e Raquel Ruiz.
Olá, seja bem-vindo a mais uma edição do Turing Talks!
Hoje, explicaremos conceitos introdutórios sobre o tema, respondendo sobre o que é um teste de hipótese e os conceitos estatísticos relacionados a ele, como hipótese nula, nível de significância e valor-p.

Hipótese estatística
Para entender o que seria um teste de hipóteses, ou teoria da decisão, primeiro precisamos saber a definição de hipótese na estatística. Ela se define como qualquer afirmação sobre uma medida numérica calculada a partir de uma amostra, como por exemplo, a média, proporção etc. Uma afirmação do tipo “a concentração sérica do colesterol difere em crianças” não é uma hipótese estatística. Para tal, a afirmação deve ser: “a diferença entre a média de concentração sérica do colesterol de crianças e adultos é nula”, pois menciona o valor do parâmetro. As hipóteses sempre serão tiradas de parâmetros populacionais, os quais os mais comuns a serem estimados são a média, o desvio padrão e a proporção.
O que é um teste de hipóteses?
Segundo Bussab & Morettin (2017), o objetivo de um teste de hipóteses é “fornecer uma metodologia que nos permita verificar se os dados amostrais trazem evidências que apoiem ou não uma hipótese (estatística) formulada”. Ele nos auxilia a tomar decisões sobre uma ou mais populações baseado na informação obtida da amostra, associado a um risco máximo de erro.
Suponhamos que temos uma determinada população e, dentro dela, retiramos uma amostra com alguns elementos. Após a análise dessa amostra, criamos hipóteses sobre a população, ou seja, fazemos um processo de inferência estatística. Por exemplo, eu quero descobrir se a média de idade da população de uma determinada cidade é 35 anos. Dependendo da cidade e do tamanho dela, seria uma tarefa muito trabalhosa e demorada saber a idade de todos os seus habitantes em um determinado período do tempo. Com isso, retiramos uma amostra x de pessoas, recolhemos a idade de todos e descobrimos que a sua média de idade é 37 anos. Faria sentido dizer que a média de idade dessa cidade é 35 anos, sendo que na amostra deu 37? É justamente nesse tipo de situação que usaremos o teste de hipótese.

Quando obtemos resultados através de uma amostra de alguma população e fazemos inferências sobre os valores obtidos, estamos sujeitos ao erro estatístico, ou seja, um erro previsto e calculado, pois nunca obteremos respostas perfeitas, com 0% de erro, afinal, não calculamos em cima do todo, mas sim da sua amostra.
Como é feito o teste de hipóteses?
A hipótese que queremos testar é chamada de hipótese nula, matematicamente representada por H0: θ = θ0. Em geral, ela é formulada a partir de dados pré-concebidos ou valores de referência historicamente aceitos. Já a hipótese alternativa, HA, é aquela que suspeitamos que seja verdadeira, e pode ser escrita de 3 formas:

A formulação da hipótese alternativa irá depender do problema em questão e do conhecimento que se tem sobre ele. A primeira alternativa é a mais geral, e é chamada de bilateral, enquanto a segunda e a terceira são hipóteses unilaterais. Uma vez definidas as hipóteses, é coletada de uma amostra aleatória o que chamaremos de evidência do parâmetro, θobs, e essa evidência irá fornecer a informação que precisamos para rejeitar ou aceitar a hipótese nula. É aí que entra o tão conhecido valor-p, que mede quão forte é a evidência contra a hipótese nula.
Formalmente, o valor-p é definido como a probabilidade de obtermos um valor tão ou mais extremo do que θobs, considerando que H0 seja verdadeira. Ou seja, ele pode ser entendido como a plausibilidade da hipótese nula frente aos dados que obtivemos: se o valor-p é “pequeno”, a evidência fornecida pelos dados é forte, e do contrário ela é fraca. Mas, afinal, o que define qual o valor limite que o valor-p deve ter para que possamos estar seguros em rejeitar a hipótese nula? Para discutir isso, precisamos definir um conceito muito importante: o nível de significância do teste, a partir da análise dos tipos de erro que podemos cometer. Existem dois tipos de erros no teste de hipóteses:
Erro de tipo I: rejeitar a hipótese nula, quando ela é verdadeira (“falso positivo”)
Erro do tipo II: não rejeitar a hipótese nula, quando ela é falsa (“falso negativo”)
Assim, podemos definir duas quantidades, a partir da probabilidade de cometermos cada um desses erros:
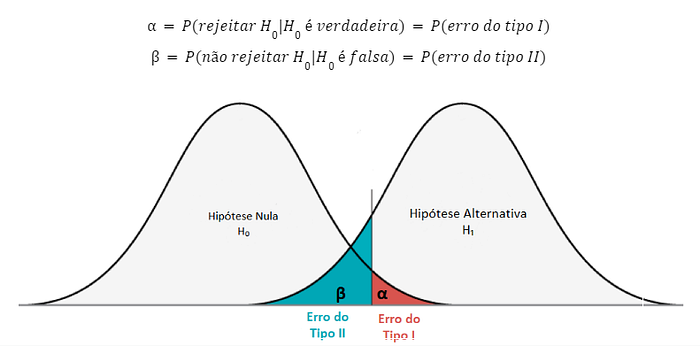
Vemos que quanto maior o valor de α, menor o valor de β, e vice-versa, então não é possível controlar essas probabilidades independentemente para que ambas sejam muito pequenas, e não cometamos erros. Por padrão, α é fixado, e este valor é o nosso nível de significância, que pode ser entendido como o risco que consideramos ser aceitável de cometer erros do tipo I. Em geral, o valor de α é adotado entre 1% e 10%, mas ele varia a depender do problema e do quão “sério” é cometer um erro do tipo I.
Por fim, calculado o valor-p e definido o nível de significância, o que queremos é o seguinte:
Se valor-p ≤ α: rejeitamos H0
Se valor-p > α: não rejeitamos H0
Vamos interpretar essas afirmações. Dizer que valor-p ≤ α é dizer que a probabilidade de cometermos um falso positivo (α) é maior ou igual à probabilidade de a nossa evidência θobs ser observada em um cenário em que a hipótese nula é verdadeira, então, devemos rejeitar H0, dado o nosso limite α para cometermos erros do tipo I. Ou seja, se a hipótese nula fosse verdadeira, a evidência que obtivemos seria extremamente rara — ou pelo menos, tão rara quanto nosso limite α permite — , então é muito difícil “acreditar” em H0. A nossa evidência é forte, e aponta para um cenário em que a hipótese alternativa HA é verdadeira.
No caso contrário, valor-p > α, a probabilidade de estarmos cometendo um falso positivo ao rejeitar a hipótese nula é menor do que a probabilidade de observarmos θobs caso a hipótese nula seja verdadeira, então é mais seguro não rejeitar H0 — a nossa evidência não se mostrou tão convincente assim! E ainda é preferível acreditar em um cenário em que a hipótese nula é verdadeira, e permitiu que a evidência fosse observada.

Nesta edição do Turing Talks, você teve uma introdução aos conceitos principais de inferência estatística e pôde aprender como funciona um teste de hipóteses. Mas este é só o começo! Se você quer saber, na prática, como aplicar um teste de hipóteses em python, fique ligado no próximo Turing Talks dessa série. Nele, falaremos sobre os testes de hipóteses mais conhecidos: o Z-test e o T-test; e como implementá-los no seu código.
Esperamos que você tenha gostado, e muito obrigado por chegar até aqui. Se quiser conhecer um pouco mais sobre o que fazemos no Turing USP, não deixe de nos seguir nas redes sociais: Facebook, Instagram, LinkedIn e, claro, acompanhar nossos posts no Medium. Para acompanhar ainda mais de perto e participar de nossas discussões e eventos, entre no nosso servidor do Discord.
Agradecimentos especiais para Felipe Azank, Lilianne e Kauã Fillipe.
Referências
“Estatística Básica” — Bussab & Morettin (2017)
https://www.inf.ufsc.br/~andre.zibetti/probabilidade/teste-de-hipoteses.html