Pierre LienhartinTowards Data ScienceThe AQLM Quantization Algorithm, ExplainedIn this blog post, we cover the AQLM quantization algorithm which sets a new state-of-the-art for compressing LLMs down to 2 bits!Mar 132Mar 132
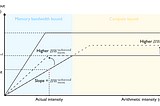
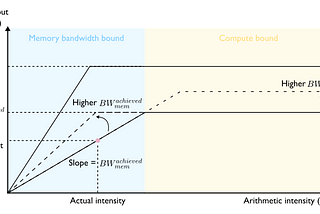
Pierre LienhartLLM Inference Series: 5. Dissecting model performanceIn this post, we look deeper into the different types of bottleneck that affect model latency and explain what arithmetic intensity is.Feb 25Feb 25
Pierre LienhartLLM Inference Series: 4. KV caching, a deeper lookIn this post, we will look at how big the KV cache, a common optimization for LLM inference, can grow and at common mitigation strategies.Jan 1511Jan 1511
Pierre LienhartLLM Inference Series: 3. KV caching unveiledIn this post we introduce the KV caching optimization for LLM inference, where does it come from and what does it change.Dec 22, 202310Dec 22, 202310
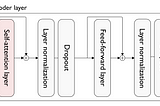
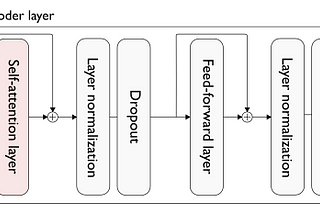
Pierre LienhartLLM Inference Series: 2. The two-phase process behind LLMs’ responsesAfter a quick reminder on the Transformer architecture, this post covers the algorithm of text generation using Transformer decoder models.Dec 22, 20231Dec 22, 20231
Pierre LienhartLLM Inference Series: 1. IntroductionIn this post, I introduce the outline of this deep dive series about the specifics and challenges of hosting LLMs for inference.Dec 22, 20231Dec 22, 20231