HANDS-ON
ML-on-Edge delivery with Snap, Microk8s and KServe on Ubuntu Core
Enable secure ML inference serving on your IoT edge device fleet with availability assurance, standardized interface protocol and auto-update capabilities

In recent years, there has been a significant surge in demand for Artificial Intelligence (AI) applications designed to operate on edge devices. This growth is attributed to the improved computing capabilities of hardware and the proliferation of high-bandwidth networks, which have led to the generation of substantial volumes of data. This data needs to be processed swiftly, ideally in real-time, as we strive for achievements like autonomous vehicles or rapid anomaly detection overseen by IoT device fleets at production facilities. Consequently, the optimal approach is to execute data processing at or in proximity to its point of origin. This strategy aligns seamlessly with the paradigm of ML-on-Edge, where AI and ML-serving solutions play a pivotal role in harnessing the potential of IoT device fleets.
Looking at Fortune Business Insights forecast: “The edge AI market size was valued at USD 11.98 billion in 2021 and is expected to reach USD 107.47 billion by 2029, exhibiting a compound annual growth rate (CAGR) of 31.7% during the forecast period”. To summarize, globally nearly every industry is expected to invest in edge artificial intelligence applications — which means there will be a massive increase in places where data will be generated and expected to be processed by a fleet of devices embedding AI solutions.
Hosting machine learning models at the edge introduces numerous challenges and risks, with security being a paramount concern. An advisable strategy involves serving your machine learning models as containerized services deployed on an orchestrator. This approach offers several benefits, including ensuring the model’s availability, facilitating model update rollouts, and, if needed, enabling controlled access to the model endpoint.
In a recent article, you can find references to mitigating security risks for Machine Learning models and an example of edge ML deployment on devices with a good network connection.
But what if there is a fleet of devices to manage? What if deploying the same model onto devices with ARM64 and AMD64 architectures is required?
No worries! In this blog post, I have got us covered.
The code is available in the repository below:
The edge OS
While container orchestration platforms like Kubernetes effectively safeguard the ML inference service, it’s imperative to acknowledge that ensuring the security of the deployment also entails running the said platform on a securely configured host operating system.
Ubuntu Core is a version of the Ubuntu operating system designed and engineered for IoT and embedded systems. It updates itself and its applications automatically. Snap packages are used exclusively to create a confined and transaction-based system. Security and robustness are its key features, along with being easy to install, maintain, and upgrade.
Information on what is inside and how to port Ubuntu Core onto edge devices can be found under:
For testing purposes, it is possible to launch Ubuntu Core in a VM using Multipass.
For this article, I used:
- Ubuntu Core22 running on a Raspberry Pi 4B 8GB
- Multipass VM on an AMD64 EC2
- Ubuntu Server on a Multipass VM on an Apple M1 MacBook
The edge ML environment setup
MicroK8s
With Ubuntu Core configured, the first step is to install strictly confined MicroK8s to match the security requirements. MicroK8s is a lightweight Kubernetes cluster with small resource requirements. It is ideal for edge deployments:
# The list of available releases can be found under:
# https://snapcraft.io/microk8s
snap install microk8s --channel=1.28-strict/stable
sudo usermod -a -G snap_microk8s $USER
mkdir -p ~/.kube
sudo chown -f -R $USER ~/.kube
newgrp snap_microk8s
# Alias kubectl and helm:
sudo snap alias microk8s.kubectl kubectl
sudo snap alias microk8s.helm helm
# Microk8s is not started by default after installation.
# To start MicroK8s run:
sudo microk8s startAfter MicroK8s is started, required extensions have to be enabled. A full list of add-ons is available here: https://microk8s.io/docs/addons.
microk8s enable metallb:10.64.140.43-10.64.140.49
microk8s enable registryBefore going to the next step, check if all expected plugins are enabled and Pods Running. Here is the expected result of MicroK8s status:
$ microk8s status
microk8s is running
high-availability: no
datastore master nodes: 127.0.0.1:19001
datastore standby nodes: none
addons:
enabled:
cert-manager # (core) Cloud native certificate management
dns # (core) CoreDNS
ha-cluster # (core) Configure high availability on the current node
helm # (core) Helm - the package manager for Kubernetes
helm3 # (core) Helm 3 - the package manager for Kubernetes
hostpath-storage # (core) Storage class; allocates storage from host directory
metallb # (core) Loadbalancer for your Kubernetes cluster
registry # (core) Private image registry exposed on localhost:32000
storage # (core) Alias to hostpath-storage add-on, deprecated
disabled:
cis-hardening # (core) Apply CIS K8s hardening
community # (core) The community addons repository
dashboard # (core) The Kubernetes dashboard
host-access # (core) Allow Pods connecting to Host services smoothly
ingress # (core) Ingress controller for external access
mayastor # (core) OpenEBS MayaStor
metrics-server # (core) K8s Metrics Server for API access to service metrics
minio # (core) MinIO object storage
observability # (core) A lightweight observability stack for logs, traces and metrics
prometheus # (core) Prometheus operator for monitoring and logging
rbac # (core) Role-Based Access Control for authorisation
rook-ceph # (core) Distributed Ceph storage using RookKServe
With MicroK8s installed and extensions configured, KServe will be the model inference platform on which ML models will be served.
KServe has some similarities to Seldon Core. Seldon Core and it’s usage was described in a separate article.
Charmed KServe can be deployed using the Juju operator on AMD64 or serverless or raw from the source for a lightweight feel and other supported architectures.
In this case, a quick-install deployment will be performed:
# Download the quick_install shell script
curl -s "https://raw.githubusercontent.com/kserve/kserve/release-0.11/hack/quick_install.sh"Because MicroK8s works in strict confinement, the quick-install script has to be called with sudo so we have to “inject” the snapped MicroK8s config into kubectl run inside the script by opening the quick-install.sh file and paste the given variable:
# Edit the file:
$ nano quick_install.sh
...
export ISTIO_VERSION=1.17.2
export KNATIVE_SERVING_VERSION=knative-v1.10.1
export KNATIVE_ISTIO_VERSION=knative-v1.10.0
export KSERVE_VERSION=v0.11.0
export CERT_MANAGER_VERSION=v1.3.0
# Add pointer to the snapped MicroK8s config file"
export KUBECONFIG=/var/snap/microk8s/current/credentials/client.configWith the file updated, KServe can be installed:
$ cat quick_install.sh | sudo bash
...
...
...
😀 Successfully installed KServeCheck the deployment status:
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-node-cxnms 1/1 Running 0 7m16s
kube-system coredns-864597b5fd-kfgq5 1/1 Running 0 7m15s
kube-system calico-kube-controllers-77bd7c5b-btfk4 1/1 Running 0 7m15s
kube-system hostpath-provisioner-7df77bc496-7wdgq 1/1 Running 0 7m4s
metallb-system controller-5c6b6c8447-jvjfg 1/1 Running 0 7m2s
container-registry registry-6c9fcc695f-5d6wp 1/1 Running 0 7m4s
istio-system istiod-57b55446f6-4vq54 1/1 Running 0 6m25s
metallb-system speaker-rq6wk 1/1 Running 0 7m2s
istio-system istio-ingressgateway-5b6899ddcc-w46xv 1/1 Running 0 6m15s
knative-serving domain-mapping-5ffd4df948-mbw5b 1/1 Running 0 6m1s
cert-manager cert-manager-cainjector-7c8bcfdd69-kmdkw 1/1 Running 0 5m57s
knative-serving autoscaler-657cb48c96-sgxbt 1/1 Running 0 6m2s
knative-serving net-istio-webhook-55c8775bfd-xdttn 1/1 Running 0 6m
knative-serving domainmapping-webhook-859df874cb-r6ml6 1/1 Running 0 6m1s
knative-serving net-istio-controller-79dc5cdb78-hxxp5 1/1 Running 0 6m
knative-serving controller-5649857ccc-q5ptg 1/1 Running 0 6m1s
knative-serving webhook-74b6f5cf75-mkj2h 1/1 Running 0 6m1s
knative-serving activator-7f86fb77f8-fjh8v 1/1 Running 0 6m2s
cert-manager cert-manager-5799666d46-9dvsz 1/1 Running 0 5m57s
cert-manager cert-manager-webhook-6dd97d9768-szqgq 1/1 Running 0 5m57s
kserve kserve-controller-manager-d754ccd4c-qllmw 2/2 Running 0 5m39s(Optional) To test KServe deployment, follow the linked instructions:
KServe with its built-in ClusterServingRuntimes allows pulling saved models from hosted servers like MLflow model registry or mounted directories and running on supported runtimes. By managing a device fleet, this approach introduces some issues:
- Deployment to devices with unstable network connections will cause timeouts and deployment fails
- Deployment has to be triggered manually or requires an on-model-release hook implementation onto the cluster
- Risk of model incompatibility
A better approach would be to leverage KServe’s custom serving-runtime deployment capabilities and deploy pre-built and tested KServe serving container images with locally injected models.
This way, due to testing model incompatibility risk will be mitigated and for auto-deployment on image change tools similar to Keel can be used:
Pre-building InferenceService container images
Building InferenceService container images
A trained model file (SKlearn ElasticNet wine-rater example) can be serialized using Python Joblib package and built into a Docker image using the following Dockerfile definition:
FROM kserve/sklearnserver
COPY model /tmp/model
CMD ["--model_dir", "/tmp/model", "--model_name", "wine-rater"]The base image and CMD arguments were populated according to the given ClusterServingRuntime specifications available in the official KServe repo:
To cross-build the image for the required architectures and save them as tarballs docker buildx build on the build machine can be used:
# For amd64 target device
docker buildx build --output type=docker -t kserve-wine-rater-amd64 ml --platform linux/amd64
docker save kserve-wine-rater-amd64 -o images/kserve-wine-rater-amd64.tar
# For arm64 target device
docker buildx build --output type=docker -t kserve-wine-rater-arm64 ml --platform linux/arm64
docker save kserve-wine-rater-arm64 -o images/kserve-wine-rater-arm64.tarThe images can be run locally by running
# Load the exported image tarball
docker load --input images/kserve-wine-rater-<your-arch>.tar
# Run the docker container
docker run --rm -it -p 8080:8080 kserve-wine-rater-<your-arch>And tested in a separate terminal with example requests
$ curl -H "Content-Type: application/json" \
-d '{"inputs": [{"name": "input1","shape": [1,11],"datatype": "FP32","data": [[5.6,0.31,0.37,1.4,0.074,12.0,96.0,0.9954,3.32,0.58,9.2]]}]}' \
http://localhost:8080/v2/models/wine-rater/infer
{"model_name":"wine-rater","model_version":null,"id":"6e3a9120-8dba-4916-8bf6-cc8d3e85c0e5","parameters":null,"outputs":[{"name":"output-0","shape":[1],"datatype":"FP64","parameters":null,"data":[5.288068083678879]}]}%Delivering ML InferenceService containers to the edge device
To deploy the InferenceService images on the edge devices, the image tarballs must be uploaded onto the devices and pushed to the previously enabled MicroK8s built-in registry.
This process can be done manually by uploading the image tarballs to the device and using docker pushing the images to the registry
# Install strict confined docker snap
sudo snap install docker
# Load the image tarball
sudo docker load --input kserve-wine-rater-<the device arch>.tar
# Tag the docker image
docker tag kserve-wine-rater-<the device arch> localhost:32000/kserve-wine-rater:<chosen version>
# Push image to MicroK8s built-in registry
docker push localhost:32000/kserve-wine-rater:<chosen version>This is not right for dealing with a device fleet with different device architectures and network stability. Imagine a case where a model update has to be deployed to 10,000 devices!
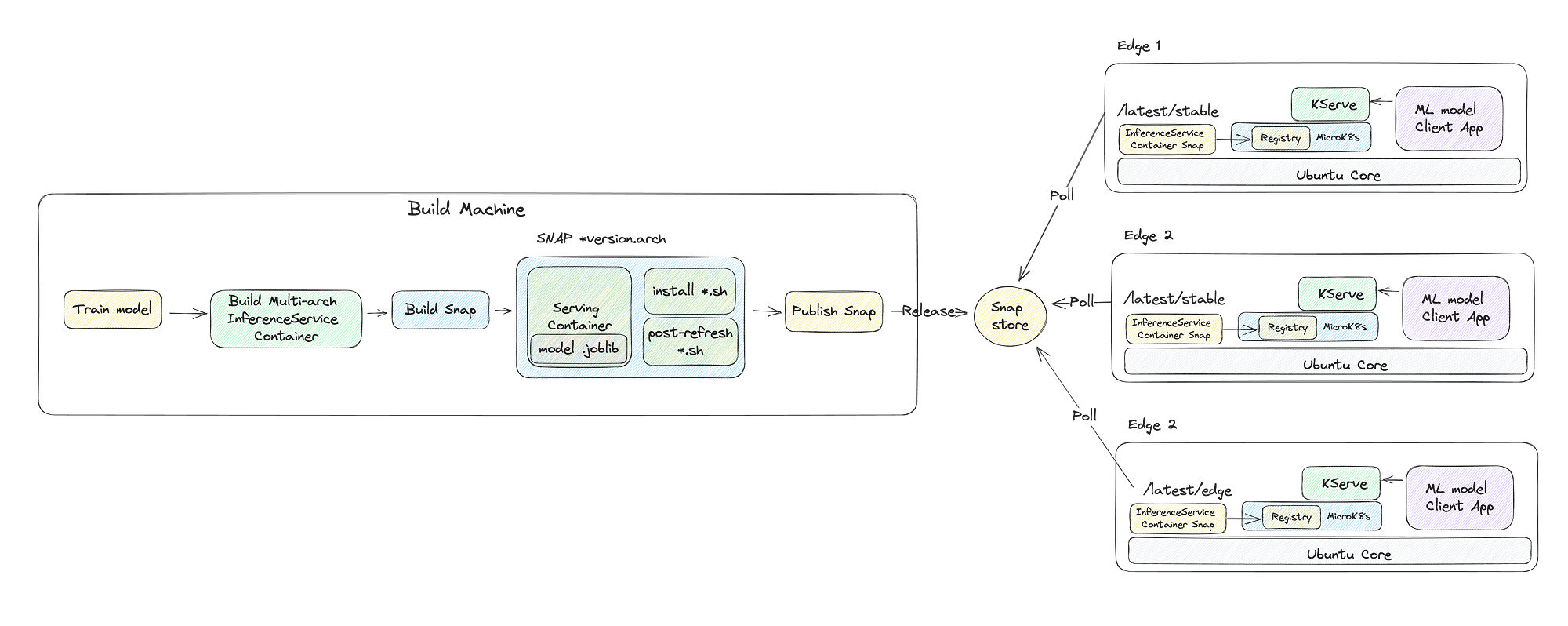
Fortunately, the nature of Ubuntu Core and Snaps comes to the rescue.
Using Snap
Snaps are a secure, confined, dependency-free, cross-platform Linux packaging format.
Snaps are self-contained, which means they include everything needed to run or use components from other snaps in a limited and controlled manner. They’re used by Ubuntu Core to both compose the image that’s run on a device and to deliver consistent and reliable software updates, often to low-powered, inaccessible, and remotely administered embedded and IoT systems.
More about managing Snaps and building them with Snapcraft can be found in Ubuntu Core and Snapcraft documentation.
The nature of Snaps allows them to deliver strictly confined content over a Snap Store, which can be private, proxied or even air-tight. The Snap daemon (Snapd) manages the updates safely in the background and allows downloading snaps even with a slow network connection. It takes some time, though.
The InferenceService container delivery Snap can be defined with a snapcraft.yaml file:
name: wine-rater
base: core22
version: "0.0.1"
summary: Inference carrier of sklearn container
description: |
This snap deliveres a KServe-compatible sklearn model inference container.
Once installed or refreshed it pushes the inference container into a configured image registry avalable on localhost:32000
confinement: strict
architectures:
- build-on: arm64
build-for: amd64
- build-on: arm64
build-for: arm64
environment:
# Define registry host variable, used to push images to by crane
REGISTRY_HOST: localhost:32000
parts:
copy-script:
plugin: dump
source: ./images
stage:
- kserve-wine-rater-${SNAPCRAFT_TARGET_ARCH}.tgz
crane:
plugin: dump
source:
- to arm64: "https://github.com/google/go-containerregistry/releases/download/v0.16.1/go-containerregistry_Linux_arm64.tar.gz"
- to amd64: "https://github.com/google/go-containerregistry/releases/download/v0.16.1/go-containerregistry_Linux_x86_64.tar.gz"
organize:
crane: usr/bin/
plugs:
network:With the copy-script part image tarball for the given build architecture is loaded into the Snap. To avoid setting up a super-privileged docker interface for uploading the images to the registry crane will be used to interact with the MicroK8S built-in registry NodePort endpoint available under localhost:32000 . As this Snap will only need to access the network, this interface has to be defined.
By leveraging Snapcraft hooks, the InferenceService containers with model updates can be delivered automatically and pushed to the registry upon snap installation or refresh. To enable that, install and post-refresh scripts have to be created in the hooks/ directory with the given content:
#!/bin/sh -e
crane push $SNAP/kserve-wine-rater-$SNAP_ARCH.tgz $REGISTRY_HOST/kserve-wine-rater:$SNAP_VERSION --insecureThe project layout will, in effect look like this:
.
├── README.md
├── images
│ ├── kserve-wine-rater-amd64.tar
│ └── kserve-wine-rater-arm64.tar
└── snap
├── hooks
│ ├── install
│ └── post-refresh
└── snapcraft.yamlTo build the Snaps, Snapcraft has to be installed on the build host and only what is left is to run the snapcraft command:
$ snapcraft
Launching instance...
Executed: skip pull copy-script (already ran)
Executed: skip pull crane (already ran)
Executed: skip build copy-script (already ran)
Executed: skip build crane (already ran)
Executed: skip stage copy-script (already ran)
Executed: skip stage crane (already ran)
Executed: skip prime copy-script (already ran)
Executed: skip prime crane (already ran)
Executed parts lifecycle
Generated snap metadata
Created snap package wine-rater_0.0.1_amd64.snap
Launching instance...
Executed: skip pull copy-script (already ran)
Executed: skip pull crane (already ran)
Executed: skip build copy-script (already ran)
Executed: skip build crane (already ran)
Executed: skip stage copy-script (already ran)
Executed: skip stage crane (already ran)
Executed: skip prime copy-script (already ran)
Executed: skip prime crane (already ran)
Executed parts lifecycle
Generated snap metadata
Created snap package wine-rater_0.0.1_arm64.snapWith the architectures configuration metadata and use of LXD as the build provider, .snap files were delivered for each architecture.
To upload the snaps to the store Snapcraft has to be authenticated and the snap name has to be registered:
# Login to Snap Store
snapcraft login
# Register the Snap name as private
snapcraft register --private wine-rater
# Release the snaps
snapcraft upload --release=<your release> wine-rater_0.0.1_arm64.snap
snapcraft upload --release=<your release> wine-rater_0.0.1_amd64.snapWhen finished, the https://snapcraft.io/wine-rater/releases should be populated with new revisions available to be promoted:

Deploy ML InferenceService containers on the edge device
To deploy the InferenceService images on the edge devices, the image tarballs must be uploaded onto the devices and pushed to the previously enabled MicroK8s built-in registry.
The registry service details can be found by running:
$ kubectl get svc -n container-registry
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
registry NodePort 10.152.183.90 <none> 5000:32000/TCP 7h29m
$ kubectl describe svc registry -n container-registry
Name: registry
Namespace: container-registry
Labels: app=registry
Annotations: <none>
Selector: app=registry
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.152.183.90
IPs: 10.152.183.90
Port: registry 5000/TCP
TargetPort: 5000/TCP
NodePort: registry 32000/TCP
Endpoints: 10.1.11.6:5000
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>Depending on the MicroK8s cluster configuration, container deployments with registry source marked as localhost:32000 might result in ImagePullBack errors. This occurs when the pod is not able to resolve localhost due to strict confinement or as a result of a https call to the insecure repository, which responds with a server gave HTTP response to HTTPS client error upon call.
To avoid those errors, the deployment can point to ClusterIP of the registry service. An adjustment was proposed in the MicroK8s private registry documentation:
sudo mkdir -p /var/snap/microk8s/current/args/certs.d/<registry svc ClusterIP>:5000
sudo touch /var/snap/microk8s/current/args/certs.d/<registry svc ClusterIP>:5000/hosts.tomlEdif the /var/snap/microk8s/current/args/certs.d/<registry svc ClusterIP>:5000/hosts.toml file:
# /var/snap/microk8s/current/args/certs.d/<registry svc ClusterIP>:5000/hosts.toml
server = "http://<registry svc ClusterIP>:5000"
[host."<registry svc ClusterIP>:5000"]
capabilities = ["pull", "resolve"]Restart MicroK8s
sudo microk8s start
sudo microk8s stopTo download the ML InferenceService container Snap snapd has to be authenticated to the Snap Store with the published model:
# Login to Snap Store
sudo snap login
# Install the wine-rater InferenceService container Snap form the given channel
sudo snap install wine-rater --channel <required channel>After downloading the Snap, install hooks will push the image automatically to the registry. The result can be tested by querying the HTTP V2 API:
$ curl -X GET http://localhost:32000/v2/_catalog
{"repositories":["kserve-wine-rater"]}
$ curl -X GET http://localhost:32000/v2/kserve-wine-rater/tags/list
{"name":"kserve-wine-rater","tags":["<chosen version>"]}In the current networking configuration, when defining the KServe deployment file to allow tools like Keel to poll the image version and update deployments, the InferenceService can be deployed using:
kubectl apply -f - <<EOF
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: wine-rater
spec:
predictor:
containers:
- name: kserve-container
image: <registry svc ClusterIP>:5000/kserve-wine-rater:<the version>
EOFThe result:
$ kubectl get inferenceservices
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
wine-rater http://wine-rater.default.example.com True 100 wine-rater-predictor-00001 47sCalling the model:
export MODEL_NAME=wine-rater
export INGRESS_HOST=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
export INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].port}')
export SERVICE_HOSTNAME=$(kubectl get inferenceservice $MODEL_NAME -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl \
-H "Host: ${SERVICE_HOSTNAME}" \
-H "Content-Type: application/json" \
-d '{"inputs": [{"name": "input1","shape": [1,11],"datatype": "FP32","data": [[5.6,0.31,0.37,1.4,0.074,12.0,96.0,0.9954,3.32,0.58,9.2]]}]}' \
http://${INGRESS_HOST}:${INGRESS_PORT}/v2/models/${MODEL_NAME}/inferModel response:
$ curl \
-H "Host: ${SERVICE_HOSTNAME}" \
-H "Content-Type: application/json" \
-d '{"inputs": [{"name": "input1","shape": [1,11],"datatype": "FP32","data": [[5.6,0.31,0.37,1.4,0.074,12.0,96.0,0.9954,3.32,0.58,9.2]]}]}' \
http://${INGRESS_HOST}:${INGRESS_PORT}/v2/models/${MODEL_NAME}/infer
{"model_name":"wine-rater","model_version":null,"id":"f00ad461-e7f6-48b2-a707-f3a3a7bc604b","parameters":null,"outputs":[{"name":"output-0","shape":[1],"datatype":"FP64","parameters":null,"data":[5.288068083678879]}]}Voila!
Summary
Using Snap, MicroK8s and KServe, we build a fully working, secure, scalable and self-updating ML-on-Edge delivery system running on Ubuntu Core. The deployed models are available to the host. They can also be configured to be available to the outside world using NodePortand all have a standard API structure.
The edge site can be extended and customised with the following ideas:
- Observability using COS
- IoT Device Fleet Management
- On-container-update model deployment updates using Keel
- Configured Snap update management
Keep on experimenting with open-source tools and share your results!
Reach out to me via my social media
