[ 2017 UCAN 論壇分享] 智能時代的語音設計

繼上次與大家分享的 Airbnb 創意總監 Steve Selzer,在 2107 UCAN 主會場分享的 <Design for Friction> 後。本週的分享,將繼續為各位帶來 Nathan 在今年 UCAN 創新分論壇中的演講內容 <智能時代的語音設計>。

2016 的上半年相信大家還記得 AR/VR 的火熱,但到了下半年人工智能( Artificial Intelligence, A.I.)卻變成了新的科技熱詞,各大互聯網公司紛紛推出各自的 A.I. 產品,開始搶占這個新的市場。
Alphabet 的 CEO Larry Page 在 2016 年的 Google I/O 大會上,正式提出了「We’re Moving from a Mobile-First to an ‘AI-First’ World」,將從無線優先開始進入人工智能優先,其實就揭開了這場白熱化的市場競爭。

Nathan 的設計團隊由於主要是對接阿里人工智能實驗室,有機會嘗試設計比較前沿的語音交互產品。因此也積極在思考隨著人工智能與語音技術的成熟,具備 Artificail Inteeligence(A.I.), Internet of Thing (IOT), 與 Conversational User Interface (CUI) 屬性的產品,設計師該從哪些維度來設計。
所以也趁著今年 UCAN 的論壇機會,總結了業務中的設計經驗,以及對 CUI 設計方法的研究與觀點。與大家分享脫離了設計師所擅長的介面後,該如何解決語音交互產品的體驗問題。
本文會依照當時的演講稿內容,分為四個段落來跟大家分享:
1. 科技型態的改變
2. 設計思維的改變
3. 設計方法的改變
4. 設計角色的改變
由於受限演講時間的原因,每個段落會以概括的方式來說明,細節的部分 Nathan 會再找時間分享給大家。讓大家也有機會一睹,前沿產品在開發過程中會遇到的各種心酸血淚。
那麽本文開始囉!
本文適合(1)對於語音設計有興趣的 Designer(2)嘗試建設 CUI 設計體系的 UX Manager(3)想知道前沿技術產品的 Anybody

科技型態的改變
從 2016 年美國的 Gartner 研究機構,所發佈的新技術成熟度曲線,可以看到「感知機器時代」已慢慢來臨。包含機器學習「Machine Learning」、虛擬個人助理「Virtual Personal Assistant」、用戶對話介面「Conversational User Interface」、智能機器人「Smart Robot」、自然語言問答等。語音人工智能相關的技術,大體已經運過了技術炒作期,開始有相關的技術沈澱與商業應用。

語音交互技術,主要包含自動語音識別 (Automatic Speech Recognition, ASR)、自然語言理解 (Natural Language Understanding, NLU)、自然語言生成 (Natural Language Generation, NLG)與文字轉語音能力 (Text to Speech, TTS)等技術。
簡單的理解,就如同真人在與人進行對話的「聆聽」、「理解」、「回覆」三種能力。也因為是基於人類的聽覺系統所發展出來的交互技術,目前這樣的交互方式也被定義為人機對話介面(Converational User Interface, CUI)。當然也有一說是基於語言聲音系統,所以稱為(Voice User Interface, VUI)。
除了大家耳熟能詳的 Siri 和 目前火紅的 Alexa,另外舉幾個例子來說明,這些與語音交互深度相關的技術,目前具體達到了什麼水平。
如果你常常往中國參加一些互聯網大會或技術論壇,應該對實時語音字幕比較熟悉,以往這樣的場合大多會請速記師來做實時紀錄。但實時語音識別技術 ASR 的成熟,已經讓機器取代這部分的工作變成了可能。雖然會因口音和嘈雜背景環境的影響,目前 ASR 技術在較好的拾音環境中,甚至有高達 97% 準確率。
而如果在 ASR 技術上再加上一些關鍵字理解和歸納的能力後,也已經開始被用到了一些相對較為專業的領域。例如截至 2016 年 8月,浙江省已經有超過32 萬起的案件,是透過智能語音法庭的方式來輔助法官判案。
語音交互雖然在深度垂直領域已經以了一些商業應用,但從橫向面的角度來看,整體還是 Too Young Too Simple,整個產業目前還屬於比較前期的階段。整體來說 ASR 與 TTS 技術相對比較成熟,已經有較多的商業化應用。
但像是 NLP/NLU 技術,甚至基於語音、語調和說話內容,來分析情緒等應用。都還在研發的路上。NLU 目前在比較簡單的垂直領域中,像是天氣查詢這種已經有不錯的表現。但到了交叉領域就還有許多訓練量要處理。必須依賴更精準的算法與大數據,才能慢慢的往鋼鐵人中的 Javis 那樣,能進行更為自然的語音交互。
語音技術真要說目前帶來最大的不同,是越來越多相關的語音產品及應用面市,使用者的行為已經開始慢慢被改變。用戶不在只是透過手機這個媒介來獲取相關服務,更多的是開始透過一個公共入口與設備,來使用不同公司所提供的應用服務。
以 Amazon 和 Google 為首的幾個大型互聯網公司巨頭。已經開始進行很深的市場佈局。從智能語音音箱到語音技術開放平台,甚至相關的開發者應用生態,都已經具備了一定的雛形,中國內部的幾個公司,包含聯想、百度、京東,今年也預計發佈幾個語音產品,宣告正式開啟中國市場的白熱化競爭。

設計思維的改變
每次的科技革新與技術變革,接續而來就是人機交戶方式與設計型式的改變。從最早的打孔機交互、到鍵盤滑鼠的點擊交互、再到目前主流的手機手勢交互。
設計師主要的設計載體,大多還是圍繞在圖像介面 GUI 上。而智能時代的來臨,也讓設計師的設計範疇,從二維的介面設計上升到了三維的無介面設計。我們需要先認知到 GUI 與 CUI 的差異,才能從原有的 GUI 設計思維轉變為 CUI 設計思維。
雖然說 CUI 語音交互產品,已經進入了我們的日常生活中,但大家目前在生活中更常碰到的相關語音產品,大多還是帶點介面的。更多的時候,我們仍是將語音交互能力,作為輔助產品使用的手段。
如目前許多 App 都有的語音搜索,更多是透過 ASR 技術,來取代原有的手動鍵盤輸入,在這個例子中可以發現,語音交互能力在用戶意圖非常明確的情境下,會比 GUI 的使用成本低上許多。使用者只要說出心中的意圖,就能立即到達對應的介面進行操作。
以往我們設計師所熟悉的交互方式,更多是仰賴視覺刺激的輸入。但如前面所提的,語音 ASR、NLU、TTS 等技術的慢慢成熟,讓 CUI 這種脫離視覺的交互方式變成了可能。
如果從所謂的人類對話的角度切入,我們可以大致將語音 A.I. 分為幾個不同的能力。聆聽語音及組織語言是構成對話的基本要素,但如果要產生一來一往的對話時,則還需要對話雙方有理解語意的能力,以及對應的知識底蘊。
簡單的歸納語音 A.I. 技術,其實也是對應的這樣的架構。

與圖像識別領域不同的是,語音 A.I. 的技術模塊都是相對獨立的。像是 ASR 與硬體構造、拾音環境與聲學信號的研究領域較有相關。NLU 意圖理解則需要依賴算法的優化,以及大量數據的訓練。
因此不同於我們在 GUI 設計中所熟悉的技術能力,CUI 的設計過程會遇到很大的技術局限性,很容易因此導致產品體驗非常差。
因此語音體驗設計師(Voice User Experience Designer)會更著重在理解語音技術能力的限制,並在目前的語音技術限制與商業應用場景中,找到一個恰到好處的平衡點。
這點 Amazon Alexa 的語音設計團隊已經做了一個很好的示範。目前 Amazon 在美國西雅圖與紐約,各有一隻專門設計 Alexa 語音交互體驗的設計團隊。相同的 Google Home 也編製了這麼一個團隊,專門來研究如何設計語音交互的體驗。
說到語音體驗設計師的職責,或許大多人會聚焦重點在電子音效與對話內容的設計。在這個思考上,我們團隊內部前後做了許多次的專家工作坊和對應的設計研究,藉由模擬人機交互領域中著名的「恐怖谷理論」。來探索在機器擬人語音對談時,有哪些因子是設計師可以具體著手發力的。
「恐怖谷理論」是指機器人與人類,在外表、動作上的相似程度到達一定水準時,人類會對機器人產生極為負面的情感。
我們嘗試透過指定劇本、以及無劇本的方式,讓一人扮演真人一人扮演機器人來重現這樣的場景,並在過程中觀察和會後訪談,來找出虛擬角色的扮演中,有哪些因子會影響最終的體驗。這樣的對話模擬方式,其實也是語音設計中的使用性測試方式之一。

從總結的設計維度中,可以發現透過模擬對談的行為模式,以及相關知識結構、人格情緒設計的方式,來塑造出一個虛擬人格。熟悉過程的設計,其實就相當於我們在 CUI 中常說的大數據或個性化,透過語音交互的使用過程,了解用戶的習慣並進而幫助達到更好的使用體驗。
其實也就像是我們的現實生活中,與人剛認識到熟悉的這麼一個過程,幫然在這樣的時間點上,這樣的設計可能還稍微早了些,但其實借鑒 GUI 發展,我們可以知道 CUI 設計必然會走上相同的道路。
擬人設計因子上,包含了較為概括的聲音、談吐、知識、行為、性格這些維度,這些因子都是幫助我們在所謂的擬人化設計上,設計師可以思考該從哪些維度來切入。當然這些因子與模式,必須得根據不同的產品、不同的業務、不同的用戶群做設定。
從專家工作坊、設計資料調研與研究中可以發現,商業環境中的語音體驗設計師,具體的設計內容可以分為「聲音形象」、「對話交互」、「對話內容」等三個部分。
聲音形象的設計,其實相當於我們在 GUI 中所說的品牌設計。但更大的挑戰是設計師要去思考賦予人性的邊界點在什麼地方?以目前的技術和可實現的場景,一昧的賦予人性可能會帶來過度設計的問題。
對話交互包含了 Chatbot 和語音交互,在脫離的 GUI 圖像輔助的設計載體後,語音交互會需要有更明確的設計目標,包含對話場景的觸發、語音交互的引導等。更重要的是語音體驗設計師,要去了解使用者在使用過程中,對語音產品的期待,並根據實際的場景與用戶期待,來設計相對應的對話 Scenario。

設計方法的改變
前面所提到的科技引領交互形式的改變,以及與 GUI 十分不同的 CUI 設計思維。其實只是粗略的幫我們分了幾個設計可以從中發力的角度。在實際的設計過程中,我們結合了這樣的思考,嘗試進行語音 A.I. 的 IOT 產品設計時,遇到了許多以前無法想像的問題。
我們對於個人智能管家這件事情一直都有個憧憬,近幾年的 Amazon Echo 和 Google Home 的大肆廣告,似乎讓人覺得這個時代已經來臨。從 Robin Willians 主演的「變人」,到史蒂芬史匹柏的「A.I.」,近期的「Her」,甚至鋼鐵人中的 JAVIS,給觀眾傳達的都是無所不能的家庭語音 A.I. 管家。
所以當一款「A.I.」、「語音交互」、「個人助手」等標籤的產品、進到使用者的家庭環境時,用戶就會對他有過高且不實際的期待。
這種過高的期待很容易就會讓使用者有「Easy Anything to Anything」的使用心智。但在目前的語音技術限制下,讓用戶進行無受限的操作時,帶來的就是產品體驗上的惡夢。
Alexa 在去年開始火紅的其中一個重要原因,是他結合了目前的語音交互限制,在商業場景中找到了可行的方案。Apple Siri 想變成鋼鐵人裡的 Javis,試圖回應使用者所有的問題。Alexa 比較簡單,他僅僅是做到聽懂你正確表述的命令,並做出對應的回饋。
“ 簡單一點反而讓用戶有更相符的產品使用心智 ”
因此語音體驗設計師,就是在目前的技術限制下,結合對話交互來幫助用戶進行預期管理,在語音產品設計核心目標,應該更傾向去做「Let User ASK, not TALK」。
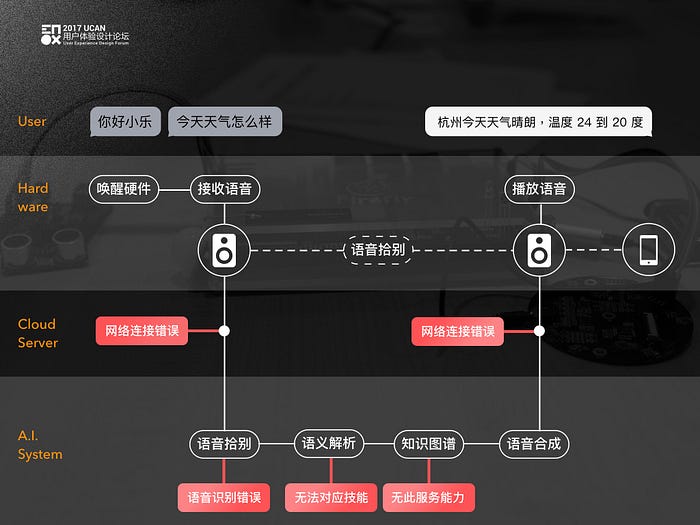
透過一張濃縮簡圖將語音交互的幾個重要節點歸納出來。

用戶使用語音產品的過程中,可以大致分為「聆聽」、「處理」、「回饋」三個階段。考慮到設備產品在家庭環境、或固定空間的拾音環境。如果設備隨時隨地的回應用戶的對話時,會造成使用者日常生活中的混亂。
因此在設計這類產品時,通常都會加入「喚醒設備」的關鍵字設計,避免用戶過於輕易或誤用的喚醒設備。
用戶觸發設備後,所輸入的語音內容會經過語音拾別、語意解析、知識理解等不同過程。在語意解析中甚至還會需要有多輪追問關鍵字的交互行為,來獲取完成用戶意圖所需要的關鍵信息。
「響應狀態的設計」以及「語音內容的設計」相對容易理解。而前面所提的設計用戶的操作心智,並做好預期管理,主要是透過「交互行為的設計」來實現。
在 GUI 中我們會因不同的任務場景、內容導向來做不同的設計。CUI 中也是一樣的,為了避免用戶在使用過程中,變成 Anything to Anthing 的使用心智。將用戶所進行的輸入,分類成不同的任務類型,並設計出對應的使用過程與反饋,就能幫助用戶對他所準備進行的操作有相符的預期。

問答操作型:
問答類以及命令類的操作都屬於這個類型,用戶在進行這類型的語音輸入時,大多是具有較為明確的目的性。
比如用戶問「杭州今天天氣怎麼樣?」的問題時,更多的期望是「講出一句話」後,就能獲得對應得反饋。
這種類型也是我們在產品設計中,更傾向讓用戶進行的操作。因為這類型的語料在語句上,自然的會擁有比較結構化、帶有指向性的關鍵詞。因此在設計中,我們也需要以「效率」、「明確」等設計目標,來盡量縮減這個類型的整體交互過程,提操用戶的操作效率。
內容播報型:
新聞類的、音頻音樂類的操作都歸類在這麼類型上,這類型的共通點是 TTS 上的回覆內容會相對較多。
比如用戶問「讀一下忘廬山瀑布」,語音 A.I. 會回覆「好的,『望廬山瀑布』,作者李白,日照香爐生紫煙,遙看瀑布掛前川,飛流直下三千尺,疑是銀河落九天」
在這個類型中,我們考慮的是「清晰」、「簡潔」。因為在使用者接收信息的過程中,只有 30 % 是透過聲音的刺激。短時間的聆聽注意力也就大約 11~13 秒左右。當 TTS 內容超出一定訊息接收成本時,很容易就會影響用戶的使用體驗。
引導同步型:
這個類型是語音交互任務中,最重要也最難實現的類型。前面更多的任務是比較明確且帶結構化關鍵字的。語音 A.I. 的算法模型還算能理解用戶所表達的意圖。但「引導同步」類型的問題,大多是用戶所說的語音命令不夠明確,或許需要更為複雜的交互過程。
也如同真實世界的對話場景,比較不結構化、較為泛話口語的表達方式,才更符合一般使用者的對話情境。因此這種類型上,我們嘗試使用了「對話框架」的設計方式,在判斷用戶的意圖過程中,逐步的縣縮對話走向直到用戶完成意圖的輸入。

語音對話框架包含了「引導」、「限縮」、「回覆」、「轉化」四個過程。如果用戶所表達的意圖內容,帶有一些關鍵訊息但仍不足時,可以透過引導以及有侷限性的追問句,來快速限縮用戶的對話走向。並在回覆內容中,讓用戶知道如果他要完成意圖,還需要輸入什麼關鍵訊息。
總體而言,每次的語音交互其實都有「引導」、「限縮」、「回覆」、「轉化」四個過程。設計師要幫助語音 A.I. 據用戶當前輸入的訊息完整度,來判斷屬於什麼樣的階段。
在語音體驗設計中,設計師一定要先分析當前的場景,用戶可能會進行的輸入是什麼樣的類型,並透過不同類型所對應的回饋結果,讓用戶可能在家居場景中所會輸入的 Anything,轉成相對應的對話結構。使用者自然就會在使用產品的過程中,有相符的預期。
情感化設計
GUI 中有所謂的情感化設計,當然 CUI 中也是一樣的。但在無界面可以著力的情形下。用戶在表達相同的意圖時,可能會使用很多種表達方式。如前面所說的,用戶在真實場景中,更多時候是使用較為口語化的方式來進行語音交互。
例如用戶想設計一個提醒時,可能會說「幫我設一個提醒下午開會」、「提醒我下午開會」、「設個提醒下午開會」等不同的表達方式。甚至當語音確認「是否間呀一個提醒『下午開會』」時,用戶可能也會說出「是的」、「好的」、「Yes」 等差異極大的確認方式。
這個問題上其實設計師能做的事情非常有限。我們除了透過挖掘場景,來盡量收集用戶對相同意圖,可能產生的不同表達方式。我們還需要透過設計非正常流程的對話交互,來幫助用戶離開錯誤的場景,也就是所謂的 CUI 情感化設計。
比如像前面的用戶使用語音產品的交互流程,幾個可能發生錯誤的節點,都需要設計師事先設計錯誤發生時,該如何引導用戶脫離當前的使用場景。
對於設計師和工程師來說,語音設計中最為困難的就是要面對大量無用的輸入訊息,整個語音交互過程,用戶可能的輸入是無法像 GUI 那樣相對規範化的。甚至用戶在交互過程中,只能依靠有限的提示以及短期記憶來完成操作。
所以語音設計的方法中,最重要的一條原則,或者說是最好的方式。就是快速的去利用一些工具,來模擬整個語音交互的過程。利用語音交互行為來管理用戶預期的方式,是需要設計師親身體驗所設計的交互過程,才能有更為清楚的認知。
設計角色的改變
從「科技型態的改變」、「設計思維的改變」到「設計方法的改變」,與大家分享了,我們在業務中所總結出的「語音體驗設計師」的設計角色。包含透過對話交互行為、對話內容結構、對話框架限縮走向等方式,來進行「語音交互的預期管理」。
接下來跟大家分享的是,在實際的設計過程中,這樣的設計角色是如何在產品開發過程中與團隊協作的。
在 CUI 開發過程中有個比較致命的問題,也是所謂的「無界面設計」所導致的。以往產品定義釐清後,設計師介入的工作形式,在 CUI 的開發流程中,可能是不存在的。
因此「語音體驗設計師」這個角色,在 CUI 的開發過程應該更往用戶體驗的人本設計的方向來著力。

在 CUI 的開發過程中,最容易遇到的問題就是相同的意圖,用戶可能會在不同的時間點、不同的地點、不同的環境中,都會有不同的表達方式。所以設計師要更進入到用戶具體使用產品的環境中,去挖掘用戶可能會產生的意圖,以及對應可能的表達方式。
甚至要依不同的地域、不同的人群來看會有多少種的表達方式。
CUI 與 GUI 在處理錯誤的設計上,最大的不同點在于由於沒有界面來限定用戶的操作,CUI 更需要提前考慮用戶可能的使用方式。需求、意圖、表達方式挖掘的越多,用戶在進行語音交互時可能遇到的錯誤情境遇越少。
挖掘出用戶的意圖以及可能的表達方式後,語音設計師的主要工作,會在設計用戶進行語音交互的對話流程,設計方式中所提到的「對話框架設計」以及其他的預期管理的方式,都是在這個階段來使用。
設計師需要將用戶可能輸入的意圖,疏理出幾種可能的操作路徑,並依邏輯對應關係來判斷用戶最終需要的反饋。這部份的設計,就需要仰賴設計師根據不同的任務屬性,來訂定不同的設計目標,並且編寫最終用戶所接收到的語音內容。
最後,也是最重要的事情是,所有語音設計師所設計出的成果,都需要放到真實的環境中來測試使用。真實的使用過程往往會超乎一開始所設定的交互流程,因此需要透過真實情境的用戶可用性測試,才能知道設計出來的結果,是否符合真實的使用情境。
最後想跟大家分享幾點 Nathan 在語音設計上的思考。Amazon Echo 的成功讓語音交互技術,在今年有爆炸性的資金與能量投入,有了很大的成長。但其實整個產業圈都還屬於在前期布局和探索階段,甚至連市場中的營利模式都還未明朗。
現階段而言語音設計的最大挑戰,更多還是屬於我們到底用語音交互這個能力,來幫助用戶完成什麼事情。
Amazon、Google 等幾家公司,正在利用優勢的資源以及大量的數據作入口平台。但如面所提的中間的垂直語音應用,還需要不同領域的開發者以及服務商來完成,原先的產業生態其也只是換了另外一種形式來展現。要達倒向鋼鐵人中的 Javis 那樣,其實需要平台以及垂直服務應用的相輔相成。
設計師在智能時代除了原先的 GUI、服務設計以外,隨著語音技術的越來越成熟,開發成本越來越低。CUI 設計將會是越來越容易涉及到的領域,因此大家可以及早做好準備,迎接智能時代的新設計挑戰。

如果你看到這裡,真心要謝謝你看完落落長的一篇內容 XD
相信大家一定可以感覺到,這個內容分享更多是針對趨勢以及方向,和設計方法、角色的改變,具體的產品設計過程基本比較少。
原因除了本次的設計論壇分享時間有限外,Nathan 目前支持的產品是簽了保密協定的,許多內部的設計資料和文檔都還無法分享給大家。
但隨著產品發佈過後,Nathan 會慢慢將這部分的內容開放出來,讓大家也能在沒有機會支持語音設計的條件下,了解未來人工智能時代可能會興起的新設計領域。
如果你對於 CUI, Voice A.I. 設計有想法或問題的話,非常歡迎留言給我們。
謝謝大家看完,如果你覺得你喜歡這篇文章的話,也請給我們贊喔!~
-Nathan