電子商務大哉問,怎麼對零售產品訂價?
理論實務交界處(一)
文 MeiCheng Shih / 圖 Wei-Hsun Chen
本文寫給對電子商務零售產業本身,或者對資料科學方法在商業上的應用有興趣的朋友,而若是剛好在準備案例面試的朋友,也或許能從這篇文章中獲得一些資訊。此外,本文花了一些篇幅在介紹因果分析的基本概念,對於這個題目有興趣的朋友也可以閱讀一下。
此外,你剛好是正在找資料科學工作的新鮮人嗎?如果是的話,也可以參考這兩篇關於在美國找資料科學工作的文章:在美找資料科學工作? 從定義你想要的開始! 實踐吧!資料科學面試該如何短期衝刺。
文章大綱
前言
對任何一個電子商務零售平台來說,其貨品的訂價方法會和該平台的商業模式高度相關。現今多元的電子零售商業模式則衍生出了各種不同的訂價過程,有些還十分複雜。
理論上,資料科學可以將這些訂價過程化繁為簡,然而大部分的過程牽涉到許多商業部門間的協調,難以被自動和系統化。
除此之外,公部門組織基於公平原則對商品價格有訂定一些規範,而這些規範會讓訂價難度增加。舉例來說,美國公部門限制電子商務平台不能在同一時間對兩個不同的客戶顯示不同價錢。這對顧客來說是好的,但對訂價來說則是挑戰,因為這扼殺了利用 A/B 測試或類似實驗來理解價錢和銷量關係的可能性。

以上是資料科學在處理訂價問題時無法扮演主角的兩個主因。但資料科學還是可以成為好輔助的!本文將根據我自己的經驗,介紹一個用資料科學方法輔助電子商務零售平台訂價的案例。
訂價過程五階段
我將分享的訂價案例有下列五個階段:
- 預測產品成本
- 估計市場價格
- 估計產品需求彈性
- 根據成本,市場價格和需求彈性得出建議售價
- 就現今商業策略對建議售價做修正
然後這五階段大致上構成了我以前公司的訂價系統。
也有其他使用類似訂價過程的公司。其中,一些較小的公司只會做一和五點,有點規模的公司可能會做到一二五點,但很少做到全部五點。另外要注意的是,上述幾點都是基於企業對顧客 (B to C) 的訂價,應該不適用於企業對企業 (B to B) 或顧客對顧客 (C to C) 的狀況。
預測產品成本
產品的成本大致上分為進貨,倉儲,和運送相關三種成本。進貨成本是向製造商購買的價格,倉儲就是儲放的成本。至於和運送相關的成本有兩大類:第一次運送到府的成本,與補件/換貨的成本。
在商品被擺上網站時,該商品唯一已知的成本是進貨成本,其它成本則尚未穩定:
- 倉儲成本會依照商品囤積數量與出貨週期而有所改變
- 運送到府成本會受製造商位置,商品儲放位置,和可用的運輸模式/者所影響
- 補件或退件成本會依照顧客需求,產品品質,和商品描述精確度而改變
因此在將成本運用於訂價時,倉儲和運算成本是需要被預測的。資料科學的個體/趨勢預測 (prediction/forecasting) 方法可以用來處理這個商業問題。而根據預測出來的值,作業研究方法 (Operations Research) 中的大規模整數最佳化 (large scale integer optimization) 則可能可以用來減少最終的真實成本。
估計市場價格
市場價格就是競爭者和自家商品打對台的價格。當對手網站存在相同商品的時候,該商品價格就是市場價格。當不存在的時候,市場價格就是顧客心中一個虛擬的值,通常由相似商品的價格決定。此外,同商品在不同競爭者平台也可能有不同價錢。
估計市場價格有兩個步驟:
- 對於自家商品,找出競爭者網站上相同或相似的商品
- 用這些商品的價格去估計市場價格。
這兩個步驟都有數種對應的資料科學方法,以下舉一例:
- 利用對手網站上商品的圖片和說來計算商品相似度(similarity),並利用這些數字來定義相同和相似商品
- 將上階段資訊和價格輸入個體預測模式來估計市場價格。理論上越相似的商品,其價格對市場價格的影響就越大

在計算市場價格時,也可以依照商品所在競爭平台的特性,或商品曝光時的狀況去進行一些修正:
- 曝光量較低平台上的價錢或許沒有曝光量高的平台來得重要
- 和自己平台相比,價格定位高或低很多平台上的價錢影響可能較小
- 自家和對手商品在 Google Ad 或者 Paid Search 中同時出現的次數
估計產品需求彈性
需求彈性描述某商品價格和銷售量的關係,通常是用商品銷售量的百分變動比除以價格百分變動比。這是整個訂價過程中最困難的階段。而困難的原因有兩個:
- 不能同時給兩個顧客看兩種價格,所以不能做 A/B 測試,只能用歷史資料去衡量價格和銷售量的關係
- 有許多其他因素會同時影響價格和銷售量(註一),這會對價格和銷售量的相對變動量產生干擾,使得其兩者的關係難以被準確衡量
因為以上兩點,需求曲線的衡量不能被視為一個單純的預測問題,應被視為一個因果分析 (Causal Inference) 問題。因果分析的目標就是在估計兩變因關係時,隔離其他變因干擾的方法。其分析資料來源主要有三個:
- 隨機實驗(random experiment,變因控制的很好的 A/B 測試是一例)
- 準隨機實驗(quasi-experiment,例如有些變因無法控制的 A/B 測試)
- 觀測資料(observational data)
隨機實驗在此不討論。使用準隨機實驗或者觀測資料的因果分析方法以統計方法居多 (註二),然後這幾年又發展出了一些混合機器學習和統計概念的方法 (註三)。另外,有一派相關的方法稱為可解釋機器學習 (interpretable machine learning),這些方法在符合一定條件 (註四) 的狀況下,被認為具有做因果推論的能力。
以下將以訂價問題為例,說明因果分析中各種變因的類型和稱呼。價格是獨立變因 (independent variable),銷售量是應變因 (dependent variable)。另外只影響銷售量的因素稱為控制 (control) 變因,受價錢影響然後再影響銷售量的是中間變因 (intermediator),在自身改變時會同時影響價格和銷售量的稱為干擾因子 (confounder),其關係如下圖。對這些變因關係的了解會影響因果分析方法的選用,和得到結果的正確性。
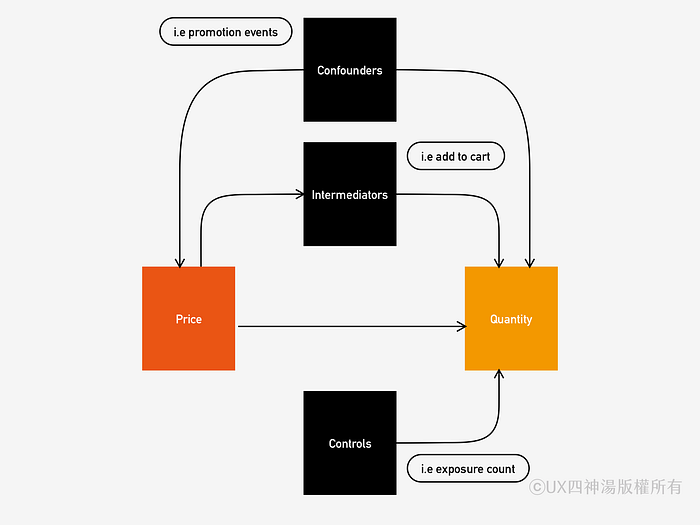
除了上述的因果分析法以外,間接的 A/B 測試也或許可行。公部門准許同時給不同顧客不同價格的折扣,所以可以利用這個方式來測試顧客對不同價格的反應。但若是顧客的價格敏感性會受到折扣存在與否的影響 (這是一個普遍的假設),那這條路就是行不通的。
除了估計某商品價格對於其銷售量的影響外,其餘相似/相關 (註五) 商品 (註一中 “ 同時影響價格和銷售量” 中的第二點) 價格對該商品銷售量的影響也可以考慮。這些影響通常統稱為交叉價格效應 (cross price effect) 。交叉價格效應非常難被估計,原因如下:
- 相似/相關商品眾多,所以其交互影響關係會形成一個複雜的網路關係
- 交差效應對銷售量影響的力道,通常會比商品本身價格要小很多 (所以在某些狀況下假設這個效應不存在也是可行的)
- 在估計效應大小時無法建立獨立的控制組(control)做比較(註六)
對於上述第三點,因果分析中有應對該問題的方法。但要注意的事情是,因果分析的準確和資料中隱含的干擾因子與控制變因的干擾高度相關,所以也時常會有得不出可用結果的狀況。
根據成本,市場價格和需求彈性得出建議售價
本文中,建議售價是指理想狀態下可讓靜利潤 ( net profit) 最大化的價格。在只考慮成本時,設定一個毛利率 (growth margin) 即可計算出建議售價。而在只考慮成本和需求彈性時,將成本和需求彈性帶入個體經濟學中的函數就可得出建議售價。
若又將市場價格納入考慮,問題就會變得稍微複雜。有多種可能的處理方法,在這邊我會舉出兩種。一種是將市場價格視為交叉價格效應的一部分,和交叉價格效應一起處理。另外一種是建立考慮市場價格的價格彈性函數。和之前固定價格彈性的假設不同,價格彈性將會依照商品價格和市場價格的相對比例而有所變動。
若是不考慮交叉價格效應,所有商品的建議售價都可以獨立計算,因為不同商品的價格和銷售量彼此之間不會有互動。當考慮交叉價格效應以後,商品彼此間的價格和銷售量連動會變得非常複雜。此外,交叉價格效應的估計本身又非常困難,所以任何訂價過程在開始考慮交叉價格效應時,難度將會大幅提升。而最佳化演算法 (optimization algorithm) 會是處理這種問題的利器。
就現今商業策略對建議售價做修正
建議售價出來以後,管理和行銷商品的組別會參考這數值來決定最終價格。資料科學在這個階段會處於更次要的角色,但依照可用的資料,可能還是可以發揮一些影響力。
以下是一個例子。當平台發展一陣子以後,部分顧客對平台的忠誠度可能會提升,這些顧客或許比較不會比價,或者願意相信高價錢的商品是有更好品質的。在這狀況下,平台可以選擇去增加整體產品的平均售價,好來增加總利潤。基於對平台的信任,顧客短期間很可能會繼續購買平台貨物,但在長期間呢?會不會有損害?另外一個常見例子則是,在平台初始期時降價吸引顧客,並在一段時間後提高價格。這又是否可行呢?
這裡需要處理的商業問題是升降價長期間對於顧客行為的影響。顧客行為可用活躍度,單次購買價值,或年均購買總值去量化,然後用因果分析方法去估計價格和這幾個指標的關係。然而對第二個問題來說,平台初始時可用的資料長度很可能不足,可能很難作出準確的估算。
結語
在商業分析相關的領域中,資料科學一直都是輔助的角色,而真正決定影響力的,是藉由資料科學傳達的訊息本身。我自己把資料科學看成是一種用數字傳遞想法的語言,並相信在這個數據決策的時代,掌握這種語言對長期的職涯發展是有幫助的。

在我們學語言的時候都需要一些範例,告訴我們詞語的意義和使用的場合。在台灣,已經有許多對於資料科學這個語言的意義進行解說的努力,而我這個系列則希望可以承接這些努力 ,給大家一些不同關於這個語言在不同 “使用場合”的例子。
若是你想到了什麼有趣的應用例子,都歡迎和我與其他資料科學人分享!
註一:影響商品價格和銷售量的可能相關因素
只影響銷售量 (control):產品的曝光度 (impression),網頁上鄰近商品的價格,網頁上處於特殊位置商品的價格
受價錢影響然後影響銷售量 (intermediator):點擊率 (在商品總覽網頁有顯示價格時),購物車率 (added to cart)
同時影響價格和銷售量 (confounder):商品的特價和行銷策略,競爭者相似商品的價格 (如果自家平台在訂價時有考慮市場價格),商品過去的價格
註二:見傾向分數 (Propensity Score) ,雙重健全估計 (Doubly Robust Estimation) ,和反事實分析 (Counterfactual Analysis)
註三:見雙重機器學習 (Double Machine Learning) 與和與深度學習在反事實分析的應用
註四:見後門準則 (back-door criterion) 和傳遞法則 (descendant rule,或搜尋中間變數的影響)
註五:有時候特性不相似的產品還是會產生關聯,例如在網頁上的時候被擺在彼此旁邊的產品,或者在網站上特價商品位置的產品和其他產品
註六:控制和比較組 (treatment group) 的成員通常要特性相似,然後交叉價格效應通常發生在特性相似的商品之間。在這兩個前提下,當比較組價格改變時,控制組的銷售量可能會受到影響,所以說不存在獨立的控制組








