Auto-Correction and Suggestions Using LSTM based Char2Vec Model

Introduction
Have you ever been curious about how your phone automatically corrects your texts? Or how Google knows you misspelt a word before you do?
Let me tell you, this is based on the topic widely known as autocorrection. In this post, I am going to walk you through a similar character-based language model that I built to suggest and autocorrect the words.
Problem Statement:
I along with my team at Version1’s Innovation Lab was involved in a project to understand various handwritten forms. Even for the most advanced players in the market, understanding handwritten text is a difficult task. There are many reasons including, no standard way of writing, noise and distortion among the characters, poorly scanned form images or the direction of writing which may differ from person to person. Due to these challenges, we were getting a lot of incorrectly recognized field values in the forms.
To address this problem we added an extra layer on top of the existing process named the post-processing phase which corrects these form fields. I have used Bi-LSTM based Char2Vec model to correct these words (in this case Irish last names) and achieved an accuracy of 94.36% with two-letter edit words (words that have two letters misspelt).
Before we dive into the technicalities and how I built this model, let us first understand some fundamentals briefly in the next section.
Fundamentals
- What is Word Embeddings?
It is simply a vector representation of the words. To be specific, the vector space model (VSM) is a space where text is represented as vectors in such a way that words with similar contexts and semantics are near each other.
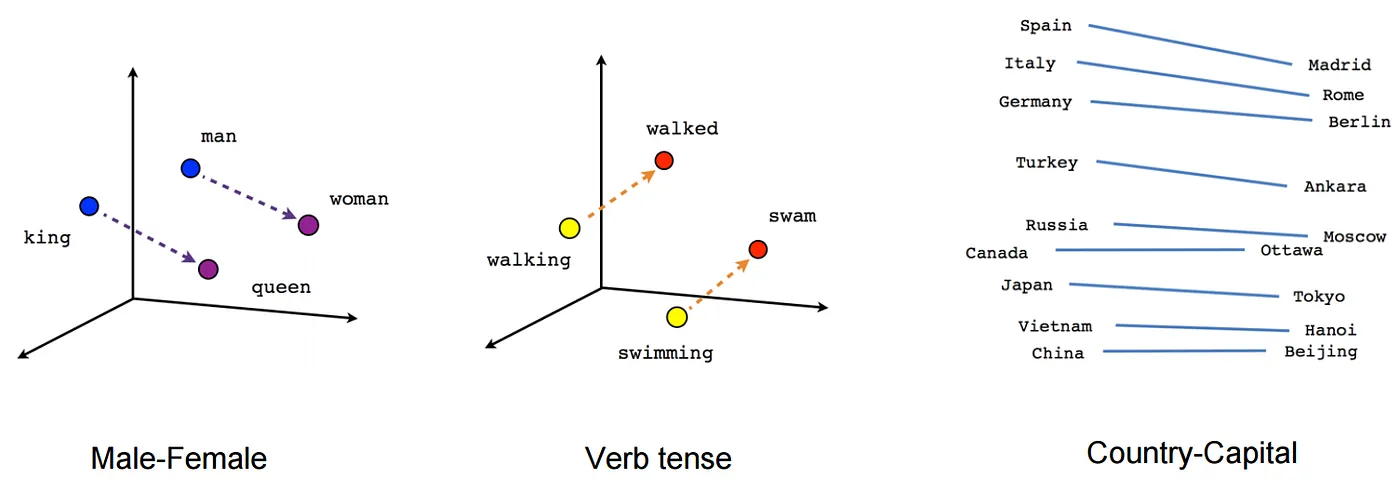
Related words occupy closer space as shown in the figure above. To find where to place the word in the space, the distance between their respective vectors is calculated.
2. How to Compute Word Embeddings?
It can be computed using various ways which can be broadly classified into two categories:
- Frequency-based Embeddings: Count-based methods compute the statistics of how often some word co-occurs with its neighbour words, and then map these count-statistics down to a small, dense vector for each word. The methods are Count Vector, TF-IDF Vector and Co-Occurance Vector
- Predictions-based Embeddings: Predictive models directly try to predict a word from its neighbours in terms of learned small, dense embedding vectors. The methods are Continuous Bag of words (CBOW) and Skip Gram.
Discussing all the methods is out of the scope of this post. To know more about them please check this link. For now, we will be focusing on the Neural Network-based approach popularly know as Word2Vec which is a mix of CBOW and Skip-Gram. To get the embeddings for each word from these algorithms they use a simple three-layer neural network: input, hidden and output layer. The weight between the hidden layer and the output layer is taken as the word vector representation of the word.
Let us briefly understand both prediction-based approaches:
i. CBOW: This model learns to predict a target word using all terms in its neighbourhood. The target word is predicted using the number of the context vectors. The adjacent terms taken into consideration is determined by a pre-defined window size surrounding the target word.
ii. Skip-Gram: This model, on the other hand, learns to predict a word based on a neighbouring word. To put it simply, given a word, it learns to predict another word in its context.

3. Challenges with Word2Vec Model?
As discussed in the previous section Word2Vec uses a neural network model to learn word associations from a large corpus of text. This model has some semantic information about the sense of words extracted while training on large texts corpora but, they operate with a fixed vocabulary (usually lacking some rarely used words).
This is a huge disadvantage when it comes to solving certain NLP problems. A semantic language model is inefficient in solving certain types of NLP tasks if several significant terms in a text do not belong to the model’s vocabulary — the model would be unable to interpret these words. If we try to process texts written by humans, we might end up in this situation (these could be replies, comments, documents or posts on the web). These texts could include typos, slang, uncommon words from unique locations, or given names that are not included in language dictionaries and, as a result, not in the semantic model as well.
4. Introduction to Char2Vec Model?
To solve the problem mentioned above, Intuition Engineering created a language model that creates word embeddings based solely on their spelling and gathers similar vectors to similarly spelt words.
The model represents the sequence of symbols (words) with a fixed-length vector, the similarity in words spelling is represented by the distance metric between vectors. Since this model is not based on a dictionary (it does not store a fixed dictionary of terms with corresponding vector representations), its initialization and usage do not require a large amount of computing power.
In the plot below, green words are the correct ones and the black ones are the typos that are similarly spelt but are not present in the dictionary. The model was able to group them based on the vector distance metric.

I have developed a similar language-based character model with a few advancements like using Bi-LSTM for getting the embeddings and a combination of KNN and Levenshtein distance to find the closest neighbours instead of cosine based similarity which resulted in significant improvement in the accuracy.
5. Levenshtein Distance
Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other. For example, the Levenshtein distance between “kitten” and “sitting” is 3 since, at a minimum, 3 edits are required to change one into the other.
- kitten → sitten (substitution of “s” for “k”)
- sitten → sittin (substitution of “i” for “e”)
- sittin → sitting (insertion of “g” at the end).
I have used Levenshtein distance to find the closest match to the current word vector among all the nearest neighbours. To calculate the nearest neighbours I used k-nearest neighbours based on ANN search (approximate nearest neighbor) using nmslib.
6. LSTM and Bi-LSTM
Long short-term memory (LSTM) is an artificial recurrent neural network (RNN) architecture used in the field of deep learning. Unlike standard feedforward neural networks, LSTM has feedback connections. It can not only process single data points, but also entire sequences of data. A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell remembers values over arbitrary time intervals and the three gates regulate the flow of information into and out of the cell. I would highly recommend this blog to understand the LSTM in more detail.

Bidirectional LSTMs (Bi-LSTM), also uses the same LSTM units but the data flow in both directions which means, we feed the learning algorithm with the original data once from beginning to the end and once from end to beginning. I have used this Bi-LSTM architecture as the base model for generating the embeddings which have shown very good results. Let us now look at how I have implemented this model in the next section.
Implementation
The approach that I have used is inspired by the work done by Lettria in this post. The approach is as follows:
- Create a training dataset.
- Train a model which gives character-level word embeddings.
- Vectorizing the entire dictionary and building an index for efficient search.
- Vectorize misspelt word and look for their nearest neighbours.
- Training Dataset Creation
Training data has been created using a dictionary of 6K+ words (Irish last names). I generated several misspelt words using insertion, deletion, transposing and replacing characters from the original words. This resulted in the creation of four similar words for each correct one, which results in 24K+similar tuples. For eg: (Ankit, Ankt), (Ankit, Anikt), (Ankit, Ankeit), (Ankit,Abkit).
Similarly, I created four non-similar words for each correct one which resulted in 24k+ non-similar tuples. For eg: (Ankit, Sumit), (Ankit, John), (Ankit, Robert), (Ankit, Alexander). So the entire training dataset becomes around 48K+ tuples. Finally, I assigned the target for similar pairs as 0 and no-similar pairs as 1.
2. Model Training and Architecture
The model uses two layers of Bi-LSTM to build an embedding of a chosen size. A higher dimension provides more accurate results at the cost of longer computation time. For this model, we have settled for a dimension of 300.
The model is trained by passing a tuple of words which are either two completely different words or a word and a misspelling of it as described in the section above. The training objective is to minimize the difference between the two embeddings for similar tuple and maximize it for different words.

I have trained this model on Databricks for 50 epochs. To train the entire Bi-LSTM based Char2Vec model, it took about 3 hours with GPU. It can take up to 8 hours on a typical CPU machine.
3. Visualization
Once we have trained our model, the next step is to check it can cluster the similarly spelt words or not. Firstly, I defined some correct and incorrect (misspelt) words which were then vectorized by the trained model. By projecting them on a 2D plane with PCA we obtained the following plot:

Great Success! The black names are the correct ones and the red ones are misspelt ones. It can be seen that similarly spelt words are closer to each other.
Note: The word “mcmahone” looks like it is far from the actual surname but it's not. If we look at it from the right-hand direction we would find that it is closer to the actual surname.
4. Usage Correction
The next step is to check if we can correct these misspelt words. To do so, we will vectorize our entire dictionary of 6K+ words. This process might take some time based on the size of the words but for my dictionary, it took just 1 minute on my CPU.
The final step is to construct an index that allows us to efficiently search for the nearest vectors. To do that we used nmslib a library specialized in Approximated nearest neighbour (ANN) search.
Once we have the dictionary vectorized and index created the next step is to find the k nearest neighbour for the current misspelt word using these indexes. In my case, I kept k=80 which was the default value and it worked perfectly fine. Once we get the k (here 80) neighbours, we checked the Levenshtein distance of the misspelt words with their neighbours and filter the ones that have the lowest distance.

In the output above we can see that the model was able to suggest the correct last name ‘bolger’ in all the cases. Edit distance 1 means there is one wrong or missing letter and Edit distance 2 means there are two wrong or missing letters in the input (misspelt word).
5. Evaluation
The above results were just for a single word (surname) with two different edits, but I wanted to evaluate the model on all of the incorrectly spelt words.
To do so I used a custom metric that checks if the actual word present in the model’s Auto-correct suggestion as shown in Fig 7. If the actual word is present in suggestions I consider that prediction as correct else incorrect.

Finally, I calculated the accuracy by dividing the total num of correct predictions by the total number of predictions. The overall accuracy I achieved is 94.36% as shown in Fig 8.
Limitations
- This model does not work well with words that have a length less than 3.
- The training time increases significantly if the embedding and training set sizes are increased.
- Vectorization of the dictionary takes time if the word count is huge.
Some Other Applications
- Improved form validation for data entry i.e. this model could be used to correct the user errors while entering the data.
- Data Cleaning: Fixing bad data in the database tables
- Fetching insights: A lot of the question-answer platforms like Reddit, Quora, and Stack Overflow have user-based inputs. A lot of the times users make typos or use slags while writing. It is difficult for a machine to understand those words which makes it difficult to perform analysis. This could be fixed using our current model by finding the closest correct word to those typos.
Conclusion
Character-level embeddings provide excellent overall efficiency, particularly for longer words. Bi-LSTM works even better for understanding the sequence and embeddings. Future works include testing this model in various other scenario and measure the accuracy.
Hope this post was helpful. If you liked it please follow me on medium, give this post a clap and stay tuned for my future posts. You can also connect with me on LinkedIn or Github.
References
- https://hackernoon.com/chars2vec-character-based-language-model-for-handling-real-world-texts-with-spelling-errors-and-a3e4053a147d
- https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec
- https://towardsdatascience.com/embedding-for-spelling-correction-92c93f835d79
- https://israelg99.github.io/2017-03-22-Vector-Representations-of-Words/
- https://kavita-ganesan.com/comparison-between-cbow-skipgram-subword/
- https://github.com/Lettria/Char2Vec
- https://en.wikipedia.org/wiki/Levenshtein_distance
- https://colah.github.io/posts/2015-08-Understanding-LSTMs/
About the Author
Ankit Kumar is currently a Data Scientist at CeADAR, Ireland working within Version 1’s Innovation Labs as an Innovation Data Scientist who generates creative solutions and proofs of concepts for businesses to ensure Version 1 at the leading edge of breakthrough innovations.
