Bisecting the Voynich manuscript alphabet

I first read about the so-called Voynich manuscript (Beinecke Library ms 408) in a 2014 paper by the late Prof.Stephen Bax. Bax believed that the manuscript is not enciphered but “written in a natural language encoded in an unknown script.” This post is based on the same assumption. Earlier examples of an approach similar to the present investigation can be found in papers by Jacques Guy, in particular “Statistical properties of two folios of the Voynich manuscript” and “Vowel identification: an old (but good) algorithm” (both published in 1991).
More recent ideas on properties of Voynichese that might have a phonetic explanation are discussed on the blog of Emma May Smith.
The Hidden Markov Model experiments published by Rene Zandbergen have also been a major inspiration for the present post. The transcription page on Zandbergen’s site presents the different transcription systems discussed below. In particular, some familiarity with the standard EVA (Extensible Voynich Alphabet) transcription system is required in order to fully understand the content of this post. Actual transcription files can be downloaded from the voynich.nu site, together with the ivtt software.

A major difference between various Voynich ms transcriptions is the treatment of the ligatures known as “benches” and “bench gallows” (or “benched gallows”): does each of these ligatures constitute a single symbol or more than one?
In 2017, Mans Hulden published a paper titled “A phoneme clustering algorithm based on the obligatory contour principle”. His work describes an unsupervised algorithm aimed at clustering together similar phonemes on the basis of a phonemic or graphemic sample of an unknown language. In Hulden’s words, the algorithm “induces grouping of unknown phoneme symbols so as to maximize potential alternation of clusters in a sequence of symbols, i.e. a corpus”.
Hulden uses simulated annealing to process a text so that all its symbols are split into two sets (Set:0 and Set:1) that maximize the number of consecutive symbols belonging to different sets. The rationale behind Hulden’s algorithm is the “universal cross-linguistic tendency to avoid redundancy or repetition of similar speech features within a word or morpheme, especially if the phonemes are adjacent to one another” (this is known as the “obligatory contour principle” — OCP). The most obvious manifestation of this principle is the tendency of vowels to alternate with consonants. Hulden applied his algorithm to translations of the bible in 503 different languages: the vowel/consonant classification (presented in Table 3 in the paper) was correct on 95.1% of symbol types, improving the already good performance of Sukhotin’s algorithm(92.5%). On the average, only 1 in 20 symbols is misclassified. Since the errors are mostly rare characters, the accuracy on symbol tokens is even better (Hulden:96.55, Sukhotin:93.65).
The problem of identifying different classes of symbols in the Voynich alphabet is obviously quite difficult and transcription uncertainties about what a Voynich symbol is make things even harder. The fact that a software implementation of Hulden’s approach (also including the “old but good” Sukhotin algorithm discussed by Jacques Guy) is available on github made me curious to apply these methods to different Voynich transcriptions.
Even if the Voynich script is phonetic, it might be different from the modern scripts on which the algorithms discussed here are based. In particular, the script could be an abjad, i.e. a writing system in which only consonants are represented. In this case, Set:0 and Set:1 might correspond to two distinct sets of consonants (e.g. dental vs non-dental). A less drastic possibility is that the Voynich script includes abbreviations: some of the symbols (in particular the ligatures) might correspond to syllables rather than to individual sounds: syllables that start and end with consonants (such as “per” or “con” / “cum” which are often abbreviated in Latin sources) would behave like consonants, but syllables that include a consonant and a vowel could behave ambiguously, combining with both vowels and consonants. These considerations must be kept present when evaluating the results of processing systems developed for modern writing systems.
In this post, the following three methods have been considered:
“Brute force”: As the name suggests, this simple method does nothing smart: all possible subsets of the alphabet are tried, selecting the split that provides the highest alternation rate between Set:0 and Set:1 symbols. This method is computationally intensive, so only the 24 most frequent symbols have been considered for each alphabet: words containing less frequent symbols are ignored. I have implemented this method on the basis of Hulden’s description.
Hulden (OCP-cluster): The computation requirements of a brute force search are bypassed by applying a heuristic approximation of the search for the optimal alphabet split. My experiments confirm that Hulden’s algorithm is consistent with the results of the brute force search.
Sukhotin: This is an ad-hoc method specifically designed to identify vowels. Hulden describes it as “a greedy approximation” of the search for the optimal split. An interesting feature of Sukhotin’s algorithm is that it outputs vowel candidates in order of decreasing reliability.
The methods have been applied to four texts in different languages written in the Latin alphabet and on several different transcriptions of the Voynich manuscript.
For each method, the resulting set of “Vowels” (Set:0) is listed, together with the percentage of consecutive symbols actually alternating between the two different sets. Candidate “Vowels” are listed both in the alphabet used by that specific transcription and in the standard EVA transcription system. For Voynich transcriptions, Set:0 is defined as the one containing the most frequent symbol (EVA:o).
Size (SZ) is the number of different symbols appearing in the text sample.
SOURCE |SZ|AL| SET:0 | %
--------+--+--+----------------------------------------+----
| |BF|a c e i o t u ä ü |73.0
Tristan |32|Hl|a c e ä i ê o î p u t ö y û ü |73.3
German | |Sk|e a i o u h ü ä p ö ê y û î |72.4
--------+--+--+----------------------------------------+----
| |BF|a e h i o u y |75.9
Dante |24|Hl|a e h i o u y |75.9
Italian | |Sk|e o a i u h y |75.9
--------+--+--+----------------------------------------+----
| |BF|a e i o u y |79.8
Mattioli|25|Hl|a e i o u y |79.8
Latin | |Sk|i e u a o y |79.8
--------+--+--+----------------------------------------+----
K.James | |BF|a d e i o t u |74.1
Bible |26|Hl|a d e i o t u |74.1
English | |Sk|e a o i t u d |74.1
--------+--+--+-------------------+--------------------+----
SOURCE |SZ|AL| SET:0 | SET:0 EVA | %
--------+--+--+-------------------+--------------------+----
| |BF|9 A C O |y a e o |81.8
VMS_CD |35|Hl|0 9 A C O L |iiir y a e o iim |81.8
| |Sk|O A C 9 0 L |o a e y iiir iim |81.8
--------+--+--+-------------------+--------------------+----
| |BF|A C G I O Z |a e y i o [Z] |77.9
VMS_FSG |24|Hl|A C G I O Z |a e y i o [Z] |77.9
| |Sk|O A C G Z I 7 |o a e y [Z] i j |77.9
--------+--+--+-------------------+--------------------+----
| |BF|a c e n o s y |a c e n o s y |80.2
VMS_EVA |22|Hl|a c e n o s y |a c e n o s y |80.2
TT | |Sk|o h a y n g v |o h a y n g v |72.5
--------+--+--+-------------------+--------------------+----
| |BF|a c e n o s u y |a c e n o s u y |80.4
VMS_EVA |25|Hl|a c e n o s u y |a c e n o s u y |80.4
ZL | |Sk|o h a y n g b u |o h a y n g b u |72.7
--------+--+--+-------------------+--------------------+----
| |BF|A E O U Y c |a e o ee y c |80.7
VMS_CUVA|27|Hl|A E O U Y c h |a e o ee y c h |80.7
| |Sk|O A Y E U c h |o a y e ee c h |80.7
--------+--+--+-------------------+--------------------+----
| |BF|E a e o y |ee a e o y |81.9
VMS_NEAL|33|Hl|E a c e o u y |ee a c e o u y |81.9
| |Sk|o a y e E c u h |o a y e ee c u h |81.9
--------+--+--+-------------------+--------------------+----
| |BF|E a e g o y |ee a e g o y |81.1
VMS_NEAL|32|Hl|E a c e g o u y |ee a c e g o u y |81.2
Cur.A | |Sk|o a y e E g c u h |o a y e ee g c u h |81.2
--------+--+--+-------------------+--------------------+----
| |BF|E a e o y |ee a e o y |82.5
VMS_NEAL|32|Hl|E a c e h o u y z |ee a c e h o u y z |82.5
Cur.B | |Sk|o a y e E c h u z i|o a y e ee c h u z i|82.5
-------+--+--+-------------------+-------------------+-----
VMS_GUY | |BF|C a c g i o t |ee a e y i o h |83.8
79v 80r |23|Hl|C a c g i o t |ee a e y i o h |83.8
1 | |Sk|o a g c C i t |o a y e ee i h |83.8
--------+--+--+-------------------+--------------------+----
VMS_GUY | |BF|C P Q a c g i o |ee [P] [Q] a e y i o|84.6
79v 80r |24|Hl|C P Q a c g i o |ee [P] [Q] a e y i o|84.6
2 | |Sk|o a g c C i Q P |o a y e ee i [Q] [P]|84.6Discussion of results
Gottfried von Strassburg (Tristan und Isolde), XIII Century, German. The German alphabet is a particularly numerous extension of the Latin alphabet, mostly because of various marks applied to vowels (e.g. umlaut). This text produced the highest number of errors (almost 10% of the symbols were misclassified) together with a low percentage of consecutive symbols alternating between Set:0 and Set:1 (73%). All misclassified symbols are consonants classified as vowels, while all vowels have been correctly identified. The errors are likely due to the frequent and sometimes long sequences of consonants, for instance (in particular with respect to ‘p’):
freundespflicht
sprach
kampf
empfieng
blüthenpracht
Quite exceptionally, with this German text, Sukhotin’s algorithm produces one error less than Hulden’s.
Dante (Divine Commedy), XIV Century, Italian. In this case, I have mapped accented vowels into unaccented characters, resulting in an alphabet of 24 symbols. The three methods generate identical results (the alphabet is small enough to be entirely processed by brute force). Symbol ‘h’ is misclassified as a vowel — in Italian this character doesn’t have a proper phonetic value and is mostly used to modify the value of the preceding consonant. In other words, the single misclassified character really stands out as something special.
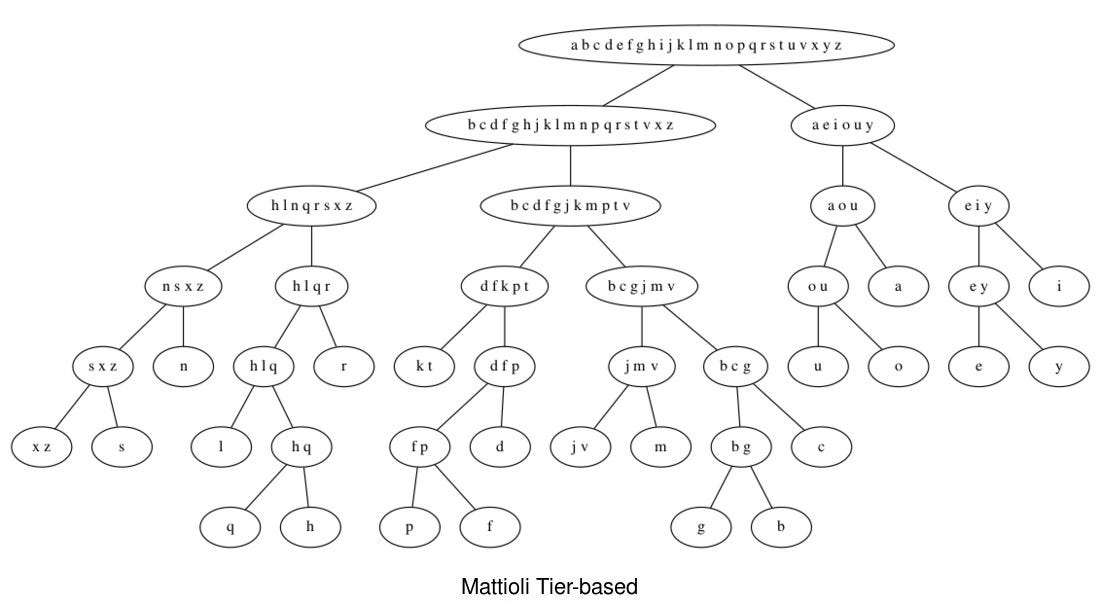
Mattioli (Commentarii in libros sex), XVI Century, Latin. The three algorithms produce consistent and error-free results. In this text, ‘y’ is used as a vowel pronounced as ‘i’.
King James Bible, XVII Century, English. Also in this case, the three methods produce the same output. Two consonants (‘t’ and ‘d’) are misclassified as vowels. The percentage of alternating consecutive symbols is low (74%). As for German, the relatively high error rate corresponds to a relatively low alternation percentage.
Voynich ms CD: Currier-D’Imperio transcription. This transcription uses a large alphabet, mapping relatively long Voynichese sequences into a single character. It has been used in several statistical studies of Voynichese, including the above mentioned paper by Jacques Guy. The four characters selected by the brute-force computation match the four first “vowels” identified by the Sukhotin algorithm. The other two characters identified by the Sukhotin and Hulden methods correspond to rare sequences and should be considered unreliable. The alternation percentage obtained with this transcription is quite high (81.8%).
Voynich ms FSG: First Study Group transcription. The Voynich ligatures known as “bench-gallows” (e.g. EVA ckh) are here translated as gallows+Z, so it was impossible to translate FSG:Z into a EVA symbol or sequence of symbols. The four symbols that were assigned to Set:0 with the CD transcription (EVA:a,e,o,y) are confirmed, with the addition of the above described ‘Z’ and of ‘i’. The FSG transcription treats EVA:i somehow inconsistently: for instance mapping the EVA sequence ‘iin’ into the single symbol ‘M’, but transcribing EVA:iir as ‘IIR’. These transcription choices are possibly the cause of the low alternation (77.9%).
Voynich ms EVA TT: Takahashi EVA transcription and EVA ZL: Zandbergen-Landini EVA transcription. These are two different transcriptions using the same conventions. The EVA alphabet has a finer granularity than the two systems described above and Voynich ligatures are here represented by multiple symbols. The fact that EVA effectively uses more symbol tokens to represent Voynichese words results in more symbols being assigned to Set:0 in order to maximize alternation. EVA:a,e,o,y are still assigned to SET:0, with the addition of EVA:c,n,s. The final alternating rate (80.2–80.4%) is higher than that for the FSG transcription and lower than that for the CD transcription. With the EVA alphabet, the Sukhotin algorithm produces a suboptimal result, with a much lower alternating rate (72.5–72.7%). It is interesting to note that the two different transcriptions based on the same alphabet produce compatible results: the only difference is the presence of EVA:u in the ZL transcription, a rare character that apparently was not used by Takahashi.
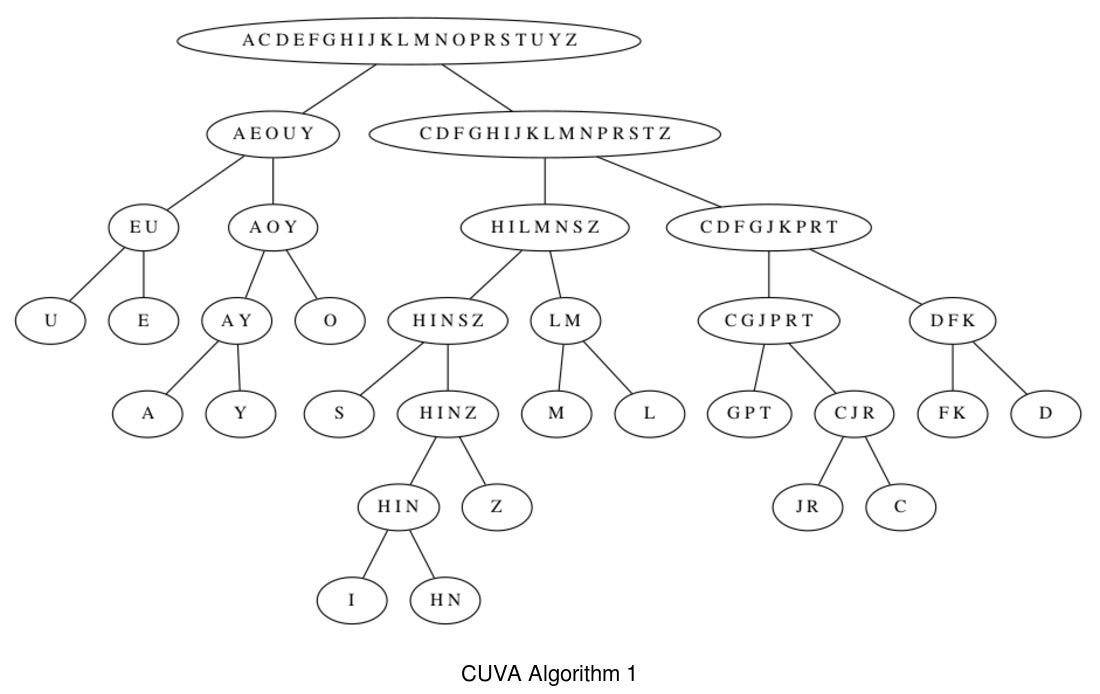
Voynich ms CUVA: ZL EVA transcription translated into CUVA. Rene Zandbergen recently introduced an EVA-based alphabet that is somehow intermediate between Currier and EVA (hence the name Cuva). This alphabet maps the EVA sequences ‘cth’ and ‘tch’ into the same sequence ‘TS’ (and similarly for the other “gallows” EVA:k,p,f). So, the treatment of “bench gallows” differs from all the transcription systems mentioned above (CD maps the ligature into a single symbol, FSG uses a unique symbol ‘Z’ that is appended to the gallows, EVA uses three symbols to represent the ligature). Cuva also uses a single symbol for some frequent EVA sequences (e.g. ‘ee’ and the “benches” ‘ch’ and ‘sh’). The results for SET:0 are consistent with those produced with the very different CD transcription. The only addition to EVA:a,e,o,y are EVA:c and EVA:h, which in Cuva are rare (a total of 29 occurrences) as residuals of the joining of the “benches” and “bench gallows” ligatures into single symbols.
Voynich ms Neal: ZL EVA transcription modified according to a system suggested by Philip Neal. This system is older than Cuva, but follows the same principle: processing EVA to join the most frequent sequences and ligatures into single characters. In this case (as in the CD system) each “bench gallows” has its own single symbol. The results are consistent with those produced for the Cuva and Currier-D’Imperio systems. Also in this case, EVA:c is residual and essentially irrelevant (only 15 occurrences, versus more than 12,000 occurrences in the ZL EVA transcription).
Voynich ms Neal Currier A and B: The two subsets of the manuscript known as “Currier A” and “Currier B” represented with Neal’s system. The major difference highlighted by the independent processing of the two subsets is that, in Currier A only, the symbol represented by EVA:g is classified as belonging to Set:0. The symbol is not frequent (120 occurrences in the whole manuscript). The other two differences (EVA:h and EVA:z) only total 20 occurrences in the whole ms in Neal encoding. Symbols EVA:a,e,o,y are confirmed as belonging to Set:0 in both Currier A and B.
Voynich ms Guy, f79v and f80r. I tried to replicate the experiments described by Guy in his 1991 paper “Statistical properties of two folios of the Voynich manuscript”. Guy uses two different modified versions of a transcription by Bennett. I have been unable to find Bennett’s transcription, but it is described on the site of Rene Zandbergen.
On the basis of Zandbergen’s table, I converted the two pages analysed by Guy from the Currier D’Imperio transcription to Bennett’s system. Then I applied the modifications described by Guy and checked character frequencies with the tables included in Guy’s paper. Some manual editing was necessary, mostly because several occurrences of EVA:f (Currier:V) were erroneously transcribed as EVA:p (Currier:B) in the CD file. I finally managed to replicate Guy’s results, in particular for his first transcription variant (presented at pag.209, Table 1). The three algorithms unanimously identify these vowel candidates:
o g a c C i t | EVA:o y a e ee i h

For the second modified transcription variant, I obtained results similar to Guy’s, but for what appears to be an error in the paper: at pag.214, GUY:t (Bennett:T, EVA:h) is listed as the last “vowel” produced by Sukhotin algorithm; Table 2 at pag.211 doesn’t list ‘t’ (which indeed doesn’t appear after Guy’s substitutions are applied to Bennett’s transcription) and instead marks ‘Q’ as the seventh and last “Vowel” identified by Sukhotin’s algorithm. Symbols ‘Q’ and ‘P’ appear only once in the two pages analysed by Guy, in the first word immediately below the blue stream flowing horizontally midpage f80r. This word was transcribed as EVA:cthcthey by Takahashi, but it contains an uncommon ligature. According to my test, Sukhotin classifies both Q and P as “Vowels”.
The candidate Vowels according to Guy’s Table.2 are:
o g a c C i Q | EVA:o y a e ee i [?]
My run of the Sukhotin algorithm produces these results:
o a g c C i Q P | EVA:o a y e ee i [?] [?]
The results are also confirmed by the “brute force” and Hulden’s algorithms.
Discussion of Guy’s results
Guy’s “Statistical analysis” only examined two pages of the Voynich manuscript in two similar variants of a single transcription, applying a suboptimal search method. When the paper was written, almost 30 years ago, the situation was much worse for statistical Voynich research. Today, several different transcriptions are available and the improvements in both computing power and processing algorithms grant more options. The experiments discussed above mostly confirm Guy’s work. Analyses based on different transcriptions and on different subsets of the manuscript than that examined by Guy produce the same (or at least very similar) results. The characters EVA:o,a,e,y consistently appear to behave like vowels.
Observing that EVA:y (‘g’, in Guy’s transcription) occurs at the end of words 90% of the times, Guy wrote that the character could be a word-final graphic variant for one of the other hypothetical vowels (EVA:o, a, e, ee). He also suggested that ‘g’ / EVA:y “might well replace all four vowels in word-final position. Perhaps the language of the Voynich manuscript (if it is a language, and not a fabrication), like many others had the last syllable of its words unstressed, and only some indistinct vowel could occur in that position. There is nothing unusual there; English, amongst many other languages, does that to a very good extent”.
Emma May Smith formulated a hypothesis that can be seen as a specialization of Guy’s comment. Her analysis is in many ways more detailed than Guy’s: in particular she carefully observed the occurrence patterns of EVA:a and EVA:y, pointing out that the two characters are largely complementary and possibly equivalent. Please refer to her blog post to examine the ample evidence that she presents.
Guy discusses EVA:e and EVA:ee (‘c’ and ‘C’ in his transcription) as completely independent symbols. His hypothesis is that EVA:ee might be a graphic variant of EVA:a (both possibly corresponding to the “a” sound). Also in this case, Emma May Smith has produced a more detailed analysis, with a different angle: EVA:e occurs in sequences of various length (‘e’,’ee’,’eee’,’eeee’). Since all these sequences appear in similar environments (i.e. the same immediately preceding and following symbols), May Smith treats them as a single “family”, focusing on the problem of detailing the different lengths of the e-sequences.
HMM results
Without entering into the details of the single experiments, the results described above are largely consistent with those produced by Rene Zandbergen using a different technique (HMM: Hidden Markov Models). In my opinion, the most notable difference is that, with the First Study Group transcription, HMM selects EVA:ch as belonging to Set:0 (together with the “usual” EVA:o,e,y,a and the rare character EVA:g). On the other hand, the three algorithms applied here are unanimous in not considering “benches” ligatures EVA:ch/sh as “vowels”. Of course this observation only applies to transcriptions that treat the “benches” as a single symbol.
The tier-based version of Hulden’s algorithm
Hulden writes that “Many identity avoidance effects have been documented that seem to operate not by strict adjacency, but over intervening material, such as consonants and vowels”. On this basis, he developed two iterative versions of his algorithm.
The first version, after splitting the symbols into Set:0 and Set:1, iterates on each set by considering the sequences of consecutive symbols that were assigned to the same set. So, if ‘e’,’o’,’y’ belong to Set:0 and ‘d’,’l’,t’ belong to Set:1, the word “oteoldy” will trigger processing of ‘eo’ in the refinement of Set:0 and of ‘ld’ in the refinement of Set:1.
In the second version (which Hulden calls “tier-based”), after the top level split, all the symbols belonging to Set:0 are removed from each word and the resulting sequence is processed. A symmetrical process is applied to Set:1. In the example above, “oteoldy” would generate “oeoy” for the refinement of Set:0 and “tld” for the refinement of Set:1 (this is of course based on the observation that the principle also operates “over intervening material”).
Here you can see examples of the output of the two versions of the algorithm applied to Mattioli and to the Voynich Cuva transcription. My impression, is that the two different methods too often disagree and, given the many uncertainties with Voynich transcriptions, these algorithms do not provided reliable results beyond the top level split.





{kind=link}
{kind=link}
{kind=link}
{kind=link}