Triplet Loss Demystified in 5 mins
A simplified explanation of the triplet loss.

Deep learning is fun. It will be quick and worth your time. Let us jump right in.
Loss functions are valleys of neural networks (pun intended) without which it can’t learn highly complex and rich representations of an image used for various tasks like detection, segmentation, classification, re-identification, tracking etc. with such brilliance.
In this article, I will unravel understanding of a loss function: Triplet Loss, first introduced in FaceNet paper in 2015 and one of the most used loss functions for image representation learning.
Being used by some of the most sophisticated deep-learning based systems like FaceID, Windows Hello etc. used by millions of users.
What is a triplet loss?

Before we jump into the intricate details, let me give the outline a few useful definitions.
- Anchor: An image ‘a’ selected from a dataset.
- Positive: An image ‘p’ selected such that it belongs to the same class as the anchor ‘a’.
- Negative: An image ’n’ selected such that it belongs to any other class but the class of anchor ‘a’.
A triplet is represented as:
Triplet : (Anchor , Positive , Negative)
The basic idea is to formulate a loss such that it pulls (anchor and positive) together, and push (anchor and negative) away by a margin.
distance(a,p) + margin < distance(a,n)
Remember when you pick positive, it should be any image but anchor belonging to the same class as anchor***.

Imagine it as if you are playing ‘tug of war’. You are the first one(anchor) in the group on the forefront (brave you), pulling the rope along with your not so brave teammates(positives) and simultaneously pushing the rope away from the opponents from the other side(negatives). That’s pretty much it.
No rocket science here otherwise I would not be doing it :P
Loss Function

f(x): Embedding generated by the model on an image x
Distance metric used in the paper is ‘squared euclidean distance’.
Now that we have a clear idea of triplet loss, let us quickly understand how to use it in an actual training setup.
Dataset Sampling
Unlike most deep learning strategies, where we randomly fetch samples from the dataset per batch, here, we cannot follow the same. We can actually, but it does not hurt anyone being a little smart.
Carefully see the loss function, and you will see a problem.
While training using triplet loss, we need to parse through not n but n³ samples to generate n training samples (triplets) due to 3 samples per triplet in a batch of size n. Sad :(
Wake up your algorithmic part of the brain and think how to mitigate this issue?
The answer is Triplet Selection Strategy mentioned in the FaceNet paper[1]. (FYI: Don’t be cruel if you know any recent and better approaches that came in recent papers. It is a starter to the meal.)
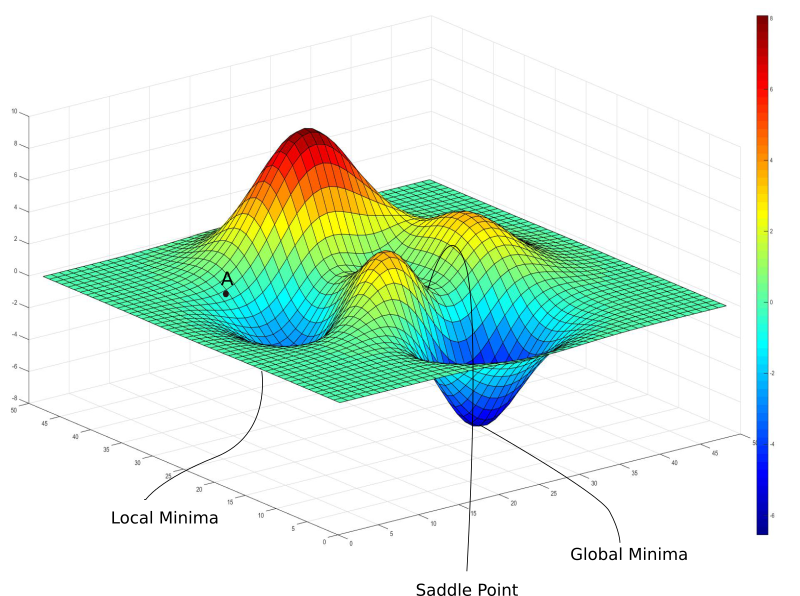
The idea is to pick hard positives and hard negatives for your training so that the model can learn from hard triplets to improve itself after every epoch. The approach is also known as hard mining. If we randomly feed triplets to training, there is a chance it may learn via easy samples early on in training, hit a local minima and fail in optimum convergence.

Hard Positives: After you select an anchor image, select the positive image from the same class as the anchor(apart from anchor), such that distance between the anchor and selected positive is the farthest(maximum distance) than any other images[argmax].

Hard Negatives: After you select an anchor image, select the negative image from a different class from the anchor, such that the distance between the anchor and chosen negative is the least(minimum distance) than rest of images[argmin].

There are 2 ways we can implement this:-
Offline Hard Mining
- Generate triplets offline every n steps of training, using the most recent network checkpoint(model) and computing the argmin and argmax on a subset of the data.
- Overall this technique is not very efficient since we need to do a full pass on the training set to generate triplets. It also requires to update the offline mined triplets regularly.[2]
Online Hard Mining
- This can be done by selecting the hard positive/negative exemplars from within a mini-batch.
- This technique gives you more triplets for a single batch of inputs and doesn’t require any offline mining. It is, therefore, much more efficient.[2]

A crucial thing about hard mining is, opposed to mining hard positives and hard negatives across entire dataset(highly inefficient) we are mining across mini-batch (a small subset of data) which can serve as semi-hard triplets for the dataset.

Many research studies show that is the best strategy to go after as there are high chances of model collapse early on in the training if you mine very hard triplets early on in training. We don’t want to hit local minima early on in training. The model ends up learning nothing***.
Semi-hard negatives are the way to go…..for training of course.
There it is. All the information on the vanilla triplet loss is right there.
If you have read it thoroughly or not, you will leave the page with something helpful. Clap(s) is your way of expressing gratitude, and it would mean a lot. It will motivate me to put more meaningful and factual content out there.
Please follow VisionWizard, if you are interested in learning about latest and greatest of deep learning research.

{kind=link}