An Overview of Scotland’s Linked Data Projects from SLiDInG 7
Both Academic Research, and Implementation in Industry and the Public Sector
On the 12th of October I hosted the 7th meetup of the Scottish Linked Data Interest Group, otherwise known as SLiDInG 7.

SLiDInG 7 was supported by The Scottish Government and SICSA Data Science, and organised by Wallscope and Heriot-Watt’s Semantic Web Lab (SWeL).
We brought industry, academia, and the public sector together to share current work, ideas, and challenges around linked data in Scotland. In this article, I have shared some of this ongoing work to encourage discussion and collaboration.
If you would like to be involved, please take a look at the Conclusion below.
We begin with a note from Shona Nicol. Following in no particular order, here are some of Scotland’s ongoing linked data projects:
A Comment from Shona Nicol
Shona is the Head of Data Standards at The Scottish Government and says:
“Unlocking the potential of Scotland’s data assets is vital if Scotland is to succeed in its economic, social, and environmental ambitions. The linked data projects discussed at SLiDInG 7 and highlighted in this article are great case studies and help drive the uptake and use of data standards (following FAIR principles), supporting the creation and management of high-quality data and enabling data to be reused, a vital step in creating the necessary data environment for success.”
Fiona McNeill
Fiona is currently a Reader in Computing Education at The University of Edinburgh and is working to answer the question:
“If I want to get as much data as possible as quickly as possible out of multiple data sources that probably use different terminology, different structures, different levels of detail, and that I might not even know that I will want to get data from until run time, how can I do that?” [source].
Fiona specified that she has a particular interest in the crisis and disaster management domains, as it is extremely important for a decision maker to get all the relevant data they need very quickly.

Poor decisions are made because the correct data was not accessible at the time, and there are many challenges here (commonly due to siloed data):
- Automatic Query Reformulation - Queries need to be formulated for an exact data silo’s structure, so how then do you broadcast queries to many sources that are structured differently from one and other? Queries need to be automatically rewritten to return results from varying data structures.
- Data Provenance - Complex queries can return results across multiple data sources, but how do you know the data is reliable? We need to know how the data is generated, where it is originally sourced from, when it was last updated, etc… in order to determine its quality.
- Returning Optimum Results - Fiona looks at both whether data is useful, and whether it is reliable. These two factors need to be considered in order to return the most suitable information to a decision maker, when needed.
Fiona explained that evaluating systems designed for crisis and disaster management is difficult. During a disaster, any technology used needs to be thoroughly fool-proof and reliable, so extensive evaluation in simulations is essential. Simulations are expensive, hard to organise, and require the involvement of a lot of people involved in disaster coordination, who are very busy and may have to cancel at any moment if an actual crisis occurs. Even quantifying whether a decision was in fact the best decision is difficult - complicating evaluation results and adding to this challenging problem.
Fiona also works in the education domain. I will go in to further detail on this when discussing one of her PhD students - Jack Walker.
Ian Allaway
Ian is the Director and Co-Founder of Wallscope, a technology company with an aim “to empower organisations to navigate and link ever-increasing volumes of information, and to present this in an understandable and engaging way” [source].

When Wallscope was initially founded, Ian explained that they first got involved with Apache Stanbol, a semantic content manager, but found that it was over-engineered for Wallscope’s uses. They decided to spend the following years developing a data-processing platform to extract entities, create knowledge graphs, and feed their visualisation studio.
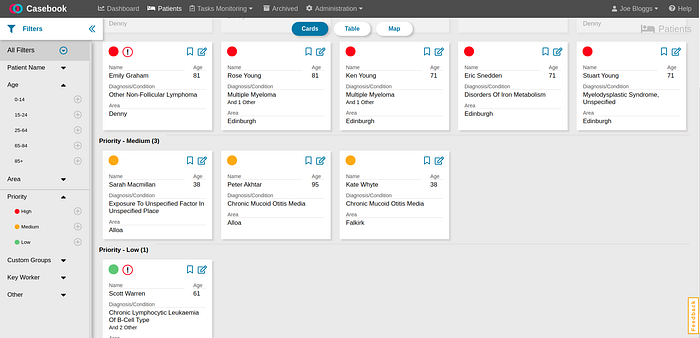
Ian talked in detail about one of Wallscope’s projects called Casebook, a healthcare application for improved patient management.
He noted that this is just one example of what Wallscope can do with knowledge graphs.
As is common, the NHS creates and manages a wide range of huge data sources - and staff often need to consult several of them to make an informed decision. Using Wallscope’s platform and visualisation studio, patients requiring continued care remain visible, in real-time, as they move through the healthcare systems.
In particular, machine learning models are used to extract crucial information from unstructured data, and pass this information to another component of Wallscope’s Platform called Data Foundry - which ingests this information and integrates it with a central knowledge graph.
Ian says this live central knowledge graph is what feeds the visualisation studio, the crucial intuitive interfaces that communicate the masses of information to a decision maker as needed.
Ian then pointed out that they have a blog, including articles that detail how Wallscope develops their linked data applications.
Peter Tolland
Peter Tolland is the Head of Directorate Programmes at The Scottish Government and, in particular, he is part of the Digital Transformation Division - responsible for the government’s digital ecosystem.

Peter expressed a keen interest to hear about the many ongoing projects and how data underpins them. One challenge that he noted as particularly important is the repeated efforts going on around the world. Everyone has a problem that they think linked data can solve, but he sees collaboration as one of the most effective paths to actually tackle them.
To help facilitate collaboration, Peter chairs the “Once for Scotland” public sector collaboration forum - a group (with 22 members at the time) seeking to encourage wider collaboration across government. Providing the opportunity for organisations to showcase and raise awareness of the work in their areas. This group can now share ideas, helping to avoid duplication of effort, and get more eyes (from various perspectives) on a project to spot challenges as early as possible. The collaboration forum is essentially ‘crowd-sourcing’ knowledge into a central repository to benefit government overall.
Alasdair Gray
Alasdair is an Associate Professor in Computer Science at Heriot-Watt University, working to make data findable and interoperable. He works on several very interesting projects and is one of the driving forces behind FAIR data.
The FAIR data principles intend to guide the creation of Findable, Accessible, Interoperable, and Reusable digital assets. A vital note is that these principles are considered for both humans and machines - data should be findable, accessible, interoperable, and reusable by machines without (or with minimal) human intervention.
FAIR data does not have to be open data, and does not necessarily have to be RDF. Though, Alasdair points out that he has never seen an example of FAIR data that wasn’t RDF.
You can read a practical guide to go FAIR here.
Going further, Alasdair is working on the FAIRplus project, which is developing guidelines and tools to make data FAIR within the pharmaceutical domain. Notably, there is ongoing development of the FAIR cookbook - a collection of ‘recipes’ that detail how to publish FAIR data in the life sciences.
Alasdair is currently working with many industries (e.g. government and building regulators) but has a particular interest in healthcare and life sciences. He is working with pharmaceutical companies to make their data FAIRplus and chairs the Bioschemas leadership team.
Bioschemas encourages people in life sciences to use a standard markup in their digital assets so they are indexed by search engines and other services - making them easier to find, integrate, and analyse in a distributed manner.

Alasdair, and the rest of the Bioschemas community propose new additions to schema.org (a common set of schema’s for structured data - founded by Google, Microsoft, and Yahoo!) in the life science domains. In addition, they create profiles - community agreed layers - on top of the schema.org vocabulary to add constraints. These constraints represent information properties agreed in life sciences about genes, proteins, chemicals, etc…
Finally, Alasdair discussed his tool called BMUSE, a directed scraping tool to extract content from web-pages and build it into a knowledge graph (using Bioschema’s markup and Wikidata as a backbone).
As I am sure I have made clear, Alasdair is involved in many projects that all share a common goal: making data findable and interoperable.
Peter Winstanley
Peter Winstanley worked for The Scottish Government for 18 years (as a data interoperability specialist) and is now an Ontologist at Semantic Arts. He has been tackling siloed data for over 20 years now, giving his expert advice to many audiences (e.g. as a member of the UK Government’s Data Standards Panel and invited expert at multiple W3C data working groups).

Peter described gist, an upper-level ontology for enterprise information systems. It was developed by Semantic Arts and is available on an open license, though you can buy it if the open license terms are not suitable for you. gist contrasts with other, perhaps more academic, upper-level ontologies in being targeted for use in enterprises. It is available for direct download into Protege (e.g. the current version is loaded through this link).

Peter explained that organisations usually have many initial questions about how gist could help them - but once they see it and get to use it, they want to use it more widely. gist is developed in an agile way with short sprints, so it is constantly improved over time. Ongoing developments are open to the public on GitHub.
Peter added that Semantic Arts are making an effort to run many events and workshops - the latest ones can be found here.
Jessica Chen-Burger
Jessica is an Assistant Professor in Computer Science at Heriot-Watt University, working on several very interesting projects. She spent some time developing business models with reasoning and predicate generation for IBM. This predicate generation required further work to create several automated verification, validation, and visualisation tools. This work often centred around Virtual Workflow Machines, one of Jessica’s key interests.

Turning to Machine Learning, Jessica has recently questioned whether we can verify and validate data in process mining? In addition, she has been exploring which semantic web technologies could assist with this goal.
Antero Duarte
Antero is the Lead Developer at Wallscope and, since starting there in 2015, has worked extensively on their platform and linked data applications. He noted that he has particular interest in re-using tools and ontologies during development - to ensure maximum interoperability.
One component of Wallscope’s platform that Antero talked about in detail is the data access management layer, called HiCCUP.
Knowledge Graphs are usually open to the world and not restricted in any way, but an organisation’s data is usually littered with sensitive information (e.g. payroll, staff personal contact details, customer information, etc…).
For this reason, a secure layer is required to provide fine-grained control between knowledge graphs and the various applications using them.
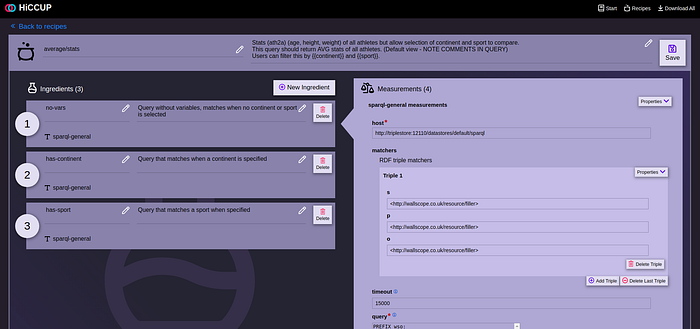
More specifically, Antero explains that HiCCUP creates APIs that do not just enable security control, but can also connect to external tools. For example, these APIs can utilise Solr for text search, templated SPARQL queries, or even JSON APIs. The ability to receive JSON calls and then return results across multiple sources in RDF is incredibly useful.
Antero also mentioned that he recently spoke at an online “Innovating with Open Data” event on the power of machine learning:
Jack Walker
Jack is a PhD student at The University of Edinburgh (supervised by Fiona McNeill above) researching how linked data can be utilised to better adapt education to individuals.
Every student, every class and every teacher is different. Teachers are faced with the daily challenge of finding and creating quality resources catered to their learner’s needs. Today however, the distribution of learning materials between teachers in Scotland is chaotic. Poorly annotated, uneditable and duplicated resources are scattered across the internet. Teachers only have so many hours in a day to not only teach but to prepare their lessons so, this project aims to enable teachers altruistic nature by building a system that streamlines the process of finding, adapting and sharing learning materials.
Jack initially worked to build a front-end application to help do exactly this, but he is now looking to develop RDF representations of both courses and curriculums.
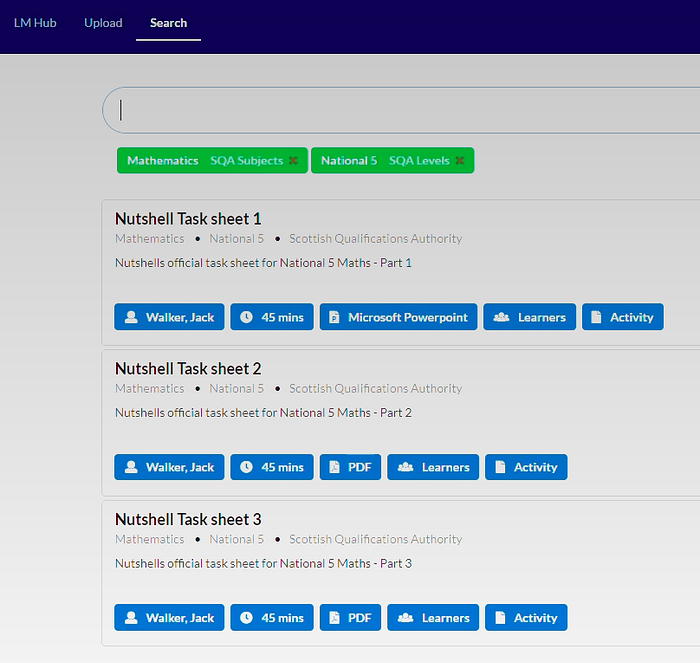
Using a structured representation of these materials, pupils can access individual resources tailored to their needs and stage of learning.
For example, Jack has also been working with Altra to make a past paper explorer for History teachers. He has been overwhelmed by the positive responses from over 1000 teachers and received numerous requests for additional features. This initial focus on History in Scotland’s curriculum has allowed them to understand how subjects, levels, and learning materials relate to each other. They plan to extend this to all subjects and then widen their focus to other countries - working closely with educators as they grow.
Jack has created a short video series detailing his work here and his long term plan is below:
Seyed Amir Hosseini
Seyed is a PhD student at Heriot-Watt University (supervised by Alasdair Gray above) researching how we can analyse and evaluate the quality of references on Wikidata. Statements on Wikidata have references to show the source of that knowledge - but not the quality of the source, which is difficult to even define.
Seyed then went on to explain that he had a particular interest in the impact of bots on Wikidata references. He wants to investigate how human references compare in quality to bot references. Following this, Seyed is looking to use a relation extraction method (like FRED) to provide qualified references for statements based upon Wikipedia references. More than 99% of Wikidata items have a corresponding Wikipedia article.
Seyed also told us that he took part in a recent Biohackathon and is continuing the project as a short-term goal. As Wikidata is so large, containing items on a wide range of topics (sports, geography, literature, etc…), there needs to be a practical way to extract subsets of it. Seyed discussed three methods for doing this and is currently working on number 3 so that he can complete his above work on smaller topical datasets (before turning to the entirety of Wikidata):
- Use custom SPARQL construct queries to generate RDF dumps.
- Using the Shape Expression Language (ShEx) to describe topics (e.g. chemistry and life science) and then extract data using a slurper.
- Use a tool like WDumper - which Seyed is currently working to improve.
Imran Asif
Imran is a PhD student at Heriot-Watt (supervised by both Alasdair Gray and Jessica Chen-Burger above), whose research centres around nanopublications - the smallest unit of publishable information.
Nanopublications are published in RDF, are partially FAIR, and have three basic elements:
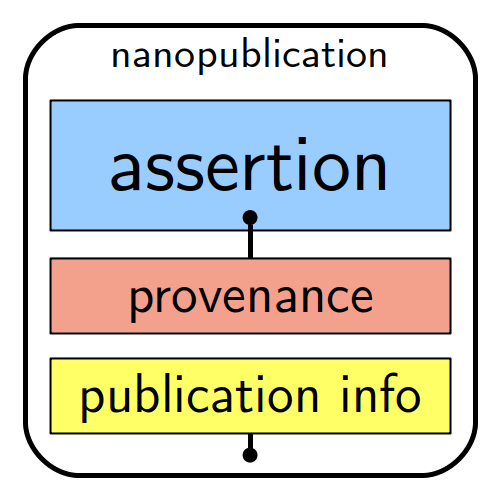
- Assertion - the claim (e.g. malaria is transmitted by mosquitoes).
- Provenance - how this assertion came to be (scientific methods, reference studies, etc…).
- Publication Info - Metadata including who asserted this, when, reuse licenses, etc…
Imran informed us that there are 10 million nanopublications published globally in the life sciences domain alone. He therefore began his work investigating their quality and highlighting issues. For example, many nanopublications were not provided in the standard structure and had minimal provenance information.
Next, Imran explored the publishing platforms (e.g. DisGeNET, neXtProt, and WikiPathways) and found they were not easily interoperable. He therefore developed and proposed a model to bring nanopublications together on a particular topic with a timeline of discourse.
Imran explained that he is now working on auto-generating nanopublications, in the social sciences domain, and building a framework to highlight contradicting assertions. He believes that the nanopublication could become a proxy of the blockchain.
Antonia Gieschen
Antonia is a PhD student at The University of Edinburgh, specialising in computational statistics, data mining, and business analytics - currently working on “Scottish prescription behaviour during the 2020 COVID-19 pandemic”.
This project is an expansion on Antonia’s previous work to explore the prescription behaviour of Scottish GPs more generally. She wonders how COVID-19 has impacted the healthcare system from a prescription angle - thought to be a good indicator of how well the system is working. Using several data-sources, Antonia can compare prescription behaviour with previous years, other regions, and even other individual GPs.
A lot of this data is released as open data by Public Health Scotland here.
To illustrate her point, Antonia showed us an example of two groups of prescriptions. She explained that the 2020 prescription volume over the year fell into one of two categories - either there was a “March spike” in prescription volume, or an “April drop” in prescription volume compared to previous years. For example:


Antonia explains that this behaviour is clearly due do COVID-19. If you have an eye irritation, people may not go to their GP to avoid the virus (or because they didn’t want to bother the busy NHS). On the other hand, if people have a respiratory issue - they are very likely to get themselves checked. This is just one of Antonia’s findings that clearly show an impact of COVID-19 on prescription behaviour.
As mentioned, Antonia doesn’t just investigate temporal differences, but spatial-temporal changes too. She is also running unsupervised machine learning over several sources of this open data and NLP on textual data. All of this analysis requires data sources which are findable, accessible, interoperable, and reusable (which you will recognise as FAIR from above). Antonia recently spoke at an online “Innovating with Open Data” event which you can watch here:
Jonathan Strachan
Johnny is a Software Engineer at Wallscope, starting there in early 2019. He explained that he works on many of Wallscope’s projects but was particularly excited to talk about STRVCT - a SKOS vocabulary builder that he developed.
STRVCT allows users to upload, create, download and edit vocabularies and visualise them in real time.

Johnny hopes that STRVCT will make SKOS very accessible to organisations, allowing them to utilise vocabularies and ontologies across their datasets, departments, offices, and with collaborators - improving the interoperability and quality of their resources.
Francesco Belvedere
Francesco is a Full Stack Developer at Wallscope, starting in 2017, and has worked extensively on Wallscope’s platform. He was particularly keen to talk about Pronto (article) - a tool he developed to find predicates and types in commonly used ontologies. He released this tool open-source so that organisations can even load their own internal ontologies and therefore search them with ease.
Francesco explained that the reuse of ontologies is a critical aspect of their existence as a means of knowledge representation. Although, the many existing ontologies make searching them tedious, labour-intensive, and time-consuming. One has to iteratively and manually inspect a number of ontologies until a suitable ontological component is found. In comes Pronto:
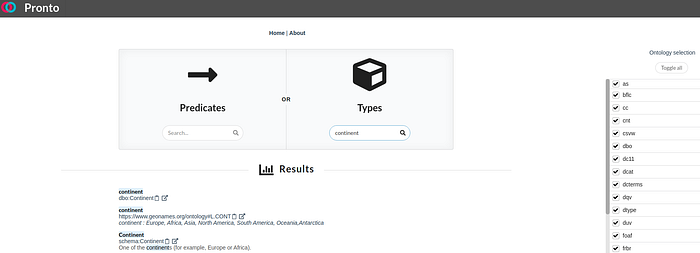
Pronto allows people to search for types and predicates within a number of ontologies. For example, to find an appropriate entity type for continent entities, Francesco typed “continent” into the Types search bar. The ontologies you can search by default are selected from the prefix.cc user-curated “popular” list (exact list here). As mentioned though, it is available open-source if custom ontology searching is required.
Francesco even made a short demo video, demonstrating its use within a section of Wallscope’s Olympics project with RDFox.
Angus Addlesee (me)
Finally, Angus (the author of this article) is a PhD Researcher at Heriot-Watt University, working on conversational AI. More specifically, I am working to adapt voice assistants (Siri, Alexa, etc…) to be more accessible for people with dementia.
This work (alongside complementary work to make voice assistants for blind and partially sighted people) combines NLP, computer vision, linguistics, ethics, etc… but is not clearly related to linked data. I have however worked with linked data extensively (with Wallscope since early 2017) and have written frequently on the topic.
In the background however, I have been working with Wallscope and partners to integrate linked data with my work (as planned for a long time). I shared this idea during SLiDInG 7 and have since been working on a knowledge graph stream representation of natural conversation as it unfolds.
Once this work is developed, I will detail it on Medium, publish it academically, release it open-source, and share across Twitter/LinkedIn as I do so. Ultimately, the plan is to integrate this with my core research.
Conclusion
I hope you have enjoyed reading about the various projects presented at SLiDInG 7 from some fantastic people!
We did discuss that the group has become very ‘central belt’ oriented. We know there are many interesting projects going on across the whole country, and want to highlight that this is not an exhaustive list.
If you are working on linked data projects in Scotland - please do get in touch for SLiDInG 8.
In addition, if you are from outwith Scotland and feel there would be a benefit to share ideas with each other (for potential collaboration for example), then do message me and I’ll arrange something if there is enough interest.

