Unsupervised sentence representation with deep learning
In recent years, the field of natural-language processing (NLP) has gained a major boost in performance thanks to the technique of representing words as a continuous vector instead of a sparse one-hot encoded vector (Word2Vec).
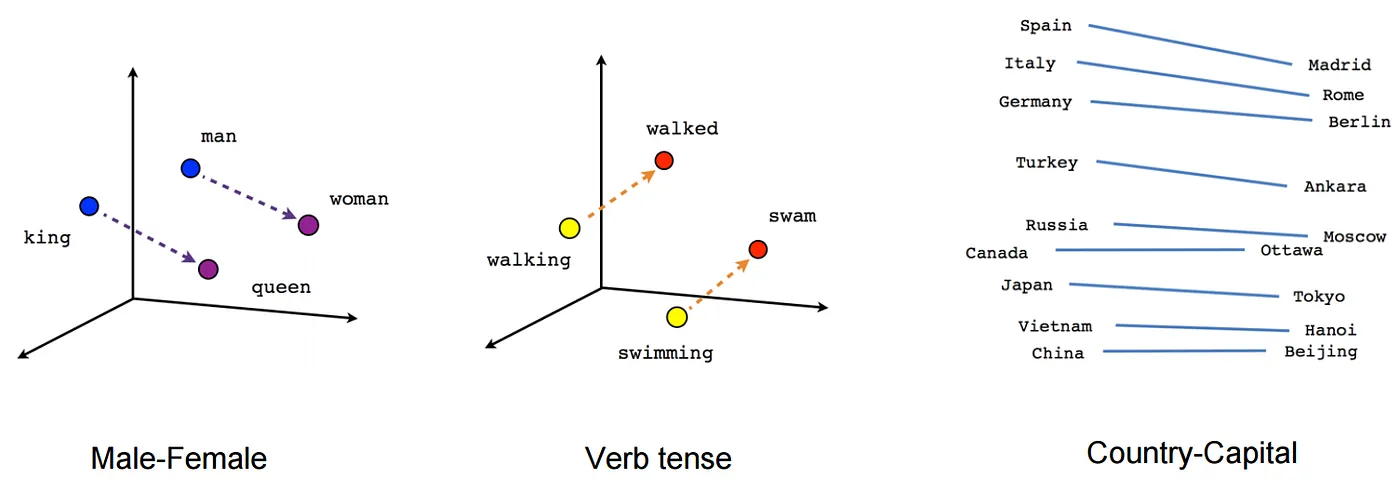
While Word2Vec works very well and creates nice semantics like King — Man + Woman = Queen, sometimes we are not interested in the representation of a word but in the representation of a sentence.
In this post, we will review and share code examples for several unsupervised, deep-learning methods of sentence representation. We will present their effectiveness as a pre-processing step for a specific text classification task.
The Classification Task
The data that we used to present the different sentence representation methods is based on 10,000 news articles that we scraped from the World Wide Web. The task is to classify each article into one of 10 possible topics (the data has topic labels, and is therefore a supervised task). For the sake of the presentation, I will use a logistic regression model, each time using a different pre-processing representation method that we will apply to the article headline.
Baseline model — Average Word2Vec
We will start with a very simple baseline. We will represent the headline by averaging the headline words in their Word2Vec representation. As previously mentioned, Word2Vec is a machine-learning method for representing words as vectors. The Word2Vec model is trained by predicting words close to the target word with a shallow neural network. You can read more about how the algorithm works here.
We can train our own Word2Vec with Gensim but in this example we will use a Google pre-trained Word2Vec model that was built based on Google news data. After representing each word as a vector, we will represent a sentence (the headline) as an average of its words (vectors) and run logistic regression for classification of the article’s category.
#load data and Word2vec model
df = pd.read_csv("news_dataset.csv")
data = df[['body','headline','category']]
w2v = gensim.models.KeyedVectors.load_word2vec_format('/GoogleNews-vectors-negative300.bin', binary=True)#Build X and Y
x = np.random.rand(len(data),300)
for i in range(len(data)):
k = 0
non = 0
values = np.zeros(300)
for j in data['headline'].iloc[i].split(' '):
if j in w2v:
values+= w2v[j]
k+=1
if k > 0:
x[i,:]=values/k
else: non+=1
y = LabelEncoder().fit_transform(data['category'].values)msk = np.random.rand(len(data)) < 0.8
X_train,y_train,X_test,y_test = x[msk],y[msk],x[~msk],y[~msk]#Train the model
lr = LogisticRegression().fit(X_train,y_train)
lr.score(X_test,y_test)
Our baseline average Word2Vec model achieved an accuracy score of 68%. This is good, but let’s see if we can do better.
The average Word2Vec method has two main weaknesses: it is a bag-of-words model that doesn’t relate to the word order, and all the words are treated with the same weight. We will try to address these issues in the next methods by leveraging RNN architectures for sentence representation.
Autoencoder
An autoencoder is an unsupervised deep learning model that attempts to copy its input to its output. The trick of autoencoders is that the dimension of the middle-hidden layer is lower than that of the input data. Thus, the neural network must represent the input in a smart and compact way in order to reconstruct it successfully. In many cases, using the autoencoder for feature extraction has proved to be very effective.

Our autoencoder is a simple Sequnce2Sequence architecture built from an input layer followed by an embedding layer, an LSTM layer, and a softmax layer. Both the input and the output of the entire architecture are the headline, and we will use the output of the LSTM to represent the headline. After getting the representation from the encoder, we will use logistic regression to predict categories. In order to gain more data, we will train the autoencoder with all the sentences in the articles and not just the headline.
#parse all sentences
sentenses = []
for i in data['body'].values:
for j in nltk.sent_tokenize(i):
sentenses.append(j)#preprocess for keras
num_words=2000
maxlen=20tokenizer = Tokenizer(num_words = num_words, split=' ')
tokenizer.fit_on_texts(sentenses)
seqs = tokenizer.texts_to_sequences(sentenses)
pad_seqs = []
for i in seqs:
if len(i)>4:
pad_seqs.append(i)
pad_seqs = pad_sequences(pad_seqs,maxlen)#The model
embed_dim = 150
latent_dim = 128
batch_size = 64#### Encoder Model ####
encoder_inputs = Input(shape=(maxlen,), name='Encoder-Input')
emb_layer = Embedding(num_words, embed_dim,input_length = maxlen, name='Body-Word-Embedding', mask_zero=False)
# Word embeding for encoder (ex: Issue Body)
x = emb_layer(encoder_inputs)state_h = GRU(latent_dim, name='Encoder-Last-GRU')(x)
encoder_model = Model(inputs=encoder_inputs, outputs=state_h, name='Encoder-Model')seq2seq_encoder_out = encoder_model(encoder_inputs)#### Decoder Model ####decoded = RepeatVector(maxlen)(seq2seq_encoder_out)
decoder_gru = GRU(latent_dim, return_sequences=True, name='Decoder-GRU-before')
decoder_gru_output = decoder_gru(decoded)decoder_dense = Dense(num_words, activation='softmax', name='Final-Output-Dense-before')
decoder_outputs = decoder_dense(decoder_gru_output)#### Seq2Seq Model #####seq2seq_decoder_out = decoder_model([decoder_inputs, seq2seq_encoder_out])
seq2seq_Model = Model(encoder_inputs,decoder_outputs )seq2seq_Model.compile(optimizer=optimizers.Nadam(lr=0.001), loss='sparse_categorical_crossentropy')history = seq2seq_Model.fit(pad_seqs, np.expand_dims(pad_seqs, -1),
batch_size=batch_size,
epochs=5,
validation_split=0.12)#Feature extraction
headlines = tokenizer.texts_to_sequences(data['headline'].values)
headlines = pad_sequences(headlines,maxlen=maxlen)x = encoder_model.predict(headlines)#classifier
X_train,y_train,X_test,y_test = x[msk],y[msk],x[~msk],y[~msk]
lr = LogisticRegression().fit(X_train,y_train)
lr.score(X_test,y_test)
We achieved an accuracy score of 60%, which is actually worse than our baseline. We can probably improve this score by optimizing the hyperparameters, increasing the number of training epochs, or training the model on more data.
Language model
Our second method is training a language model to represent our sentences. A language model describes the probability of a text existing in a language. For example, the sentence “I like eating bananas” would be more probable than “I like eating convolutions.” We train a language model by slicing windows of n words and predicting what the next word will be in the text. You can read more about language modeling with RNN here. By building a language model, we gain an understanding of how “journalistic English” is built, and the model should be capable of focusing on important words in its representation.

Our architecture is similar to the autoencoder architecture, but instead of predicting a sequence of words, we will only be predicting one word. The input will contain windows of 20 words from the articles, and the label will be the 21st word. After training the language model, we will take the headline representation from the LSTM output hidden state and run logistic regression to predict categories.
#Building X and Y
num_words=2000
maxlen=20
tokenizer = Tokenizer(num_words = num_words, split=' ')
tokenizer.fit_on_texts(df['body'].values)
seqs = tokenizer.texts_to_sequences(df['body'].values)seq = []
for i in seqs:
seq+=i
X = []
Y = []
for i in tqdm(range(len(seq)-maxlen-1)):
X.append(seq[i:i+maxlen])
Y.append(seq[i+maxlen+1])X = pd.DataFrame(X)
Y = pd.DataFrame(Y)
Y[0]=Y[0].astype('category')
Y =pd.get_dummies(Y)#Buidling the network
embed_dim = 150
lstm_out = 128
batch_size= 128model = Sequential()
model.add(Embedding(num_words, embed_dim,input_length = maxlen))
model.add(Bidirectional(LSTM(lstm_out)))
model.add(Dense(Y.shape[1],activation='softmax'))
adam = Adam(lr=0.001, beta_1=0.7, beta_2=0.99, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss = 'categorical_crossentropy', optimizer=adam)
model.summary()print('fit')
model.fit(X, Y, batch_size =batch_size,validation_split=0.1, epochs = 5, verbose = 1)#Feature extraction
headlines = tokenizer.texts_to_sequences(data['headline'].values)
headlines = pad_sequences(headlines,maxlen=maxlen)
inp = model.input
outputs = [model.layers[1].output]
functor = K.function([inp]+ [K.learning_phase()], outputs )
x = functor([headlines, 1.])[0]#classifier
X_train,y_train,X_test,y_test = x[msk],y[msk],x[~msk],y[~msk]
lr = LogisticRegression().fit(X_train,y_train)
lr.score(X_test,y_test)
We achieved an accuracy score of 72%. This is better than our baseline, but let’s see if we can make it better still.
Skip-Thought Vectors
In the skip-thought paper from 2015, the authors took the same intuition from the language model. However, in skip thought, instead of predicting the next word, we are predicting the previous and the next sentence. This gives the model more context for the sentence, thus we can build better representations of sentences. For more information about the model, check out this great blog post.

We will build a Seq2Seq architecture similar to the autoencoder architecture, but with two main differences. First, we will have two output layers with LSTMs — one for the previous sentence and one for the next sentence. Second, we will use teacher forcing in the output LSTMs. This means that instead of giving the output LSTM the previous hidden state only, we will also give it the real previous word (you can see an illustration of the input in the picture above, in the bottom line of the outputs).
#Build x and y
num_words=2000
maxlen=20tokenizer = Tokenizer(num_words = num_words, split=' ')
tokenizer.fit_on_texts(sentenses)
seqs = tokenizer.texts_to_sequences(sentenses)
pad_seqs = pad_sequences(seqs,maxlen)x_skip = []
y_before = []
y_after = []for i in tqdm(range(1,len(seqs)-1)):
if len(seqs[i])>4:
x_skip.append(pad_seqs[i].tolist())
y_before.append(pad_seqs[i-1].tolist())
y_after.append(pad_seqs[i+1].tolist())x_before = np.matrix([[0]+i[:-1] for i in y_before])
x_after =np.matrix([[0]+i[:-1] for i in y_after])
x_skip = np.matrix(x_skip)
y_before = np.matrix(y_before)
y_after = np.matrix(y_after)#Building the model
embed_dim = 150
latent_dim = 128
batch_size = 64#### Encoder Model ####
encoder_inputs = Input(shape=(maxlen,), name='Encoder-Input')
emb_layer = Embedding(num_words, embed_dim,input_length = maxlen, name='Body-Word-Embedding', mask_zero=False)
x = emb_layer(encoder_inputs)_, state_h = GRU(latent_dim, return_state=True, name='Encoder-Last-GRU')(x)encoder_model = Model(inputs=encoder_inputs, outputs=state_h, name='Encoder-Model')seq2seq_encoder_out = encoder_model(encoder_inputs)#### Decoder Model ####
decoder_inputs_before = Input(shape=(None,), name='Decoder-Input-before') # for teacher forcingdec_emb_before = emb_layer(decoder_inputs_before)decoder_gru_before = GRU(latent_dim, return_state=True, return_sequences=True, name='Decoder-GRU-before')
decoder_gru_output_before, _ = decoder_gru_before(dec_emb_before, initial_state=seq2seq_encoder_out)decoder_dense_before = Dense(num_words, activation='softmax', name='Final-Output-Dense-before')
decoder_outputs_before = decoder_dense_before(decoder_gru_output_before)decoder_inputs_after = Input(shape=(None,), name='Decoder-Input-after') # for teacher forcingdec_emb_after = emb_layer(decoder_inputs_after)decoder_gru_after = GRU(latent_dim, return_state=True, return_sequences=True, name='Decoder-GRU-after')
decoder_gru_output_after, _ = decoder_gru_after(dec_emb_after, initial_state=seq2seq_encoder_out)decoder_dense_after = Dense(num_words, activation='softmax', name='Final-Output-Dense-after')
decoder_outputs_after = decoder_dense_after(decoder_gru_output_after)#### Seq2Seq Model ####seq2seq_Model = Model([encoder_inputs, decoder_inputs_before,decoder_inputs_after], [decoder_outputs_before,decoder_outputs_after])seq2seq_Model.compile(optimizer=optimizers.Nadam(lr=0.001), loss='sparse_categorical_crossentropy')seq2seq_Model.summary()history = seq2seq_Model.fit([x_skip,x_before, x_after], [np.expand_dims(y_before, -1),np.expand_dims(y_after, -1)],
batch_size=batch_size,
epochs=10,
validation_split=0.12)#Feature extraction
headlines = tokenizer.texts_to_sequences(data['headline'].values)
headlines = pad_sequences(headlines,maxlen=maxlen)x = encoder_model.predict(headlines)#classifier
X_train,y_train,X_test,y_test = x[msk],y[msk],x[~msk],y[~msk]
lr = LogisticRegression().fit(X_train,y_train)
lr.score(X_test,y_test)
We achieved an accuracy score of 74%. This is the best score we’ve achieved so far!
Conclusion
In this post, we reviewed three unsupervised methods for creating vector representations of sentences with RNNs and presented their effectiveness in solving a supervised task. The results of the autoencoder method were worse than the results for the baseline model (possibly because of the relatively small dataset used). The language and skip-thought vector models, both of which used context for predicting words or sentences, obtained the best result.
The many options available for improving the methods we’ve presented include tuning the hyperparameters, training using more epochs, using a pre-trained embedding matrix, changing the neural network architecture, and more. In theory, such advanced tuning work might change some of the results, but I believe the basic intuition of each pre-processing method can be achieved with the examples I’ve shared above.
Hope you enjoyed my post, and you’re more than welcomed to read and follow our blog at YellowBlog.

