Overfitting and Underfitting of a machine learning model
Hi! Guys here I am with my first blog. Have you ever given a thought behind the poor performance of your machine learning model? The cause behind this performance is the Overfitting and Underfitting of the trained model. An important consideration in learning the target function(i.e f(x)) from the training data is how well the model generalizes to new data. Generalization is important because the data we collect is only a sample, it is incomplete and noisy.

Generalization of the model
The model is required to learn the general features of training data rather than learning the specific features of a data. By this generalization, the model performs well under the unseen data by having a good prediction score on the testing data. Sometimes the model learns only the specific features including the noise which makes it very poor under the testing data, though having a very good score on training data.
There is a terminology used in machine learning when we talk about how well a machine learning model learns and generalizes to new data, namely Overfitting and Underfitting. These are the two biggest cause for the poor performance of machine learning algorithms.
Overfitting and Underfitting
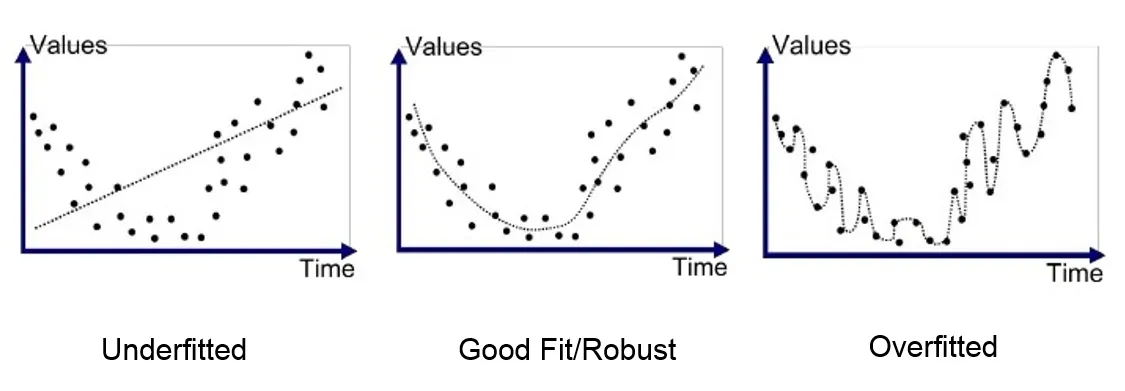
Overfitting means a model that models the data too well. That means the model which has been trained on a trained data, it has learned all the features including the noises, thus having a very good score on the training data. While the prediction score on the testing data is very poor. Picking of noise while training negatively impacts the model’s ability to generalize. Overfitting is more likely with non-parametric and nonlinear models as they are more flexible while learning a target function.
Underfitting refers to a model that can neither model the training data nor generalize to the testing data. These models are not suitable and are obvious they will have poor performance on the training data. These are easy to detect as well.
These are the screenshots of code and the output.



To get the full code:- https://github.com/DB11051998/Underfitting-and-overfitting/tree/master
Fixing of the model

The most common problem in the applied machine learning model is overfitting. To overcome this issue we got a fix. The re-sampling method(K-cross-validation) can be used to overcome this. It allows us to train and test the model k-times on different subsets of training data and build up an estimate of the performance of the model on unseen data. It subdivides the training into the numbers of sub-data which depends on the K value. Each time the model is trained and that model is tested on the validation sets(a subset of the training data). And then the cross-validation score is analyzed to see whether the algorithm taken is fine for the dataset or not.
We got functions in the scikit-learn library to do the above task.
https://scikit-learn.org/stable/modules/cross_validation.html

I hope this might have given you some idea about the topic and must have cleared all your basic confusions.
Thanks for reading, any feedback is welcome.