Your First “Words” In Natural Language Processing
“Ba boo, mamma, dadda” — those are probably a child’s first words whenever they are trying to learn new words and how to speak. But what about computers?
Let me guess. You’ve probably heard of something called Natural Language Processing, or more commonly abbreviated to NLP, but you don’t know what it really is, or how it really works, right? Or maybe you haven’t heard about it at all, and you’re just reading out of curiosity. Well, in both cases, you’re in the right place. And trust me, in just a matter of minutes, you’ll get to know more than you would’ve imagined.
Let’s kick-off our journey by saying that you… yes, you… who are about to discover a lot of NLP facts you didn’t know about, have encountered NLP several times in your life. Well, you,… yes yes,… YOU again…, have used NLP solutions to solve a lot of your problems, and all of this without even noticing! Weird, huh?
Give me a minute or two… allow me to explain myself!
Basically, NLP is integrated into many aspects of our lives. Who among us hasn’t tried to translate a word from a language to another? Who wasn’t happy while seeing Google auto-completing their search request with some of the most likely sentences appearing at the top of guesses made by the search engine itself? Who wasn’t relieved when seeing their misspelled words automatically being corrected while writing an important email? Who hasn’t talked to Siri or Cortana, or at least saw someone talking to them?
Wow! So after all, it seems that NLP is something really familiar, right?
The answer is yes and no. The thing is, you’re familiar with what NLP can do, but you don’t know exactly how the magic of NLP happens to let the translator give you the correct word, or to let Google predict what you want to search for, let alone have your grammar and spelling mistakes be checked regularly or even to let Siri or Cortana understand what you want and respond back to you.
See? There’s a lot of stuff to cover. But have no fear, for I am here… Now through this article, you will get to know the cornerstones that will help you in any task involving NLP. And one thing to remember is that all of the people that did great work in NLP out there, were at some point beginners like you, studying the same concepts that you will start in a bit, and who knows? Maybe someday, you’ll be able to do something great yourself too!
So without further ado, let’s get started!
Some Definitions
What is Natural Language?
Natural Language refers to the way we humans communicate (which is mainly text or voice).
So, what’s Natural Language Processing?
Natural Language Processing (NLP) is a field of study that’s making use of natural language by extracting information from it.
It’s clear that nowadays, the amount of generated text is increasing exponentially, ranging from simple text messages we send, to news, articles, blog posts, social media posts, books, newspapers, and magazines. That’s why we need an automated way to process and organize this unstructured data.
And yes you’re right, this is where NLP comes in!
But as you know, nothing in life comes without challenges, right? This kind of gives life beauty in itself. Let’s skip the philosophy for now and proceed.
Some Challenges of Natural Language…
We might think that language is easy just for the fact that we are able to understand it despite its complexities. However, natural language has a lot of ambiguities.
Don’t agree? Let’s tell you about some.
- Lexical Ambiguity
Let’s go back to school when you were in your first class, and the teacher would ask you to look up a word definition for him — say the word “Bat”. Normally you would use your dictionary or surf the Internet for such a task, and most likely you’ll end up with some information similar to this.
So what you’ve got here is a word having two different meanings, and this is what we call Lexical Ambiguity.
2. Syntactic Ambiguity
Again let’s go back to school (we’re gonna do this several times, bear with me…), and imagine that your friend tells you this:
“The Professor said on Monday he would give an exam.” Now, normally in this case you would ask for further explanation to know if your professor said so on Monday, or if your exam is on (next) Monday. The answer is going to largely depend on how your friend intended to parse the sentence, and this is what syntactic ambiguity is all about.
3. Semantic Ambiguity
I guess the picture says it all, right? And I’m pretty sure, the fan is laughing right now because it didn’t mean that! But to give credit to the guy, the sentence could be understood both ways!
This is what we call Semantic Ambiguity.
I guess it’s pretty straightforward by now how ambiguous natural language can be. As humans, we can manage to understand it most of the times, but…what about computers?
De facto, just like us, computers have their own ways of avoiding ambiguities. Some of those techniques might include:
- Part-of-Speech (PoS) tagging
It is mainly about breaking down the sentence into words, and assigning to each word its part of speech (Noun, Verb, Adjective, Adverb…).
Computers learn how to do so in order to know who does what in a sentence.
2. Named Entity Recognition (NER)
This helps in extracting some specific entities from your text like dates, names, places, people, etc.
I’m sure that you’re familiar with what those techniques are. In fact, we were used to being graded in primary school based on answers to questions like:
“Circle the verbs and underline the nouns in the following passage (4 pts)” [That’s PoS]
“When and where did the story take place? (2 pts)” [Time and Place recognition]
“Who is the main character of the story? (1 pt)” [ Main character name recognition]
So just like those questions helped you understand a lot of texts before, they help computers understand natural language a bit more, and avoid ambiguities a lot more, which is fundamental for any NLP application.
Speaking of applications
Until now, we have covered some NLP applications that you already knew about. Let’s take a look at some new ones!
Sentiment Analysis
This is where we’re assigning an emotion or a sentiment to a sentence, a tweet, a movie review, etc… This is especially used to understand whether the user liked or didn’t like a movie, enjoyed or didn’t enjoy a product, etc.
Visual Question Answering
It’s when we train an AI model to look at an image, then answer a question that we asked. The model has to understand the content of the image, then understand the question it is being asked before it can answer, so this involves Computer Vision and NLP.
Image Captioning
Image captioning is another application that combines Computer Vision with NLP. You show the model an image and the model has to generate a sentence that describes it best.
Alright. Now that you know this much about NLP, let’s get to some serious stuff that involve things we do to get these great results.
In fact, in any NLP problem you face, there are several mandatory steps to perform. Through the rest of this article, we will cover the most important ones which involve Data Preparation and Feature Extraction.
Data Preparation
Like every Machine Learning problem, the first step to do is to get your data ready and cleaned to be able to use it. The only difference here is that our data is mainly in the form of text. Let’s call it a corpus. How do we prepare it? Follow these different steps below:
- Cleaning the text
Since text comes from different sources, we will have different kinds of noises we want to eliminate, and by noise, I mean everything that does not contribute to the meaning in a particular application. Some examples might include:
- Removing punctuation and special characters
- Removing numbers, emojis, leading and trailing white spaces
- Removing stopwords: words which do not add much meaning to the text like “of, at, by, for, with, …”
- Removing HTML/XML tags
- Normalizing the case
- Correcting spelling errors
- Replacing accented characters (like é for example).
One thing to note is not all of the cleaning techniques mentioned above are necessary for all problems. Cleaning your text is task-specific.
2. Tokenization
It’s mainly about splitting your text into smaller chunks called tokens. There are different approaches for doing this like splitting by word, by sentence, by whitespace, or splitting by a custom regular expression, depending on what you’re willing to do with your data.

3. Stemming
Let’s say we have the words “playing”, “played”, and “play” in a corpus. Shall we consider them as three different words? Or assign them to one unique word “play” (the root)?
Well, if our application doesn’t care about the tense of the verb, we should consider them as one word because this won’t affect the results and it will reduce the complexity of our data. Otherwise, we shouldn’t.
This is actually called stemming.
The point of stemming is to reduce the complexity and the number of unique words that the model has to learn while maintaining useful information for said model.
Here’s an example covering some of the techniques mentioned above.

Feature Extraction
Even with the text corpus pre-processed in a suitable way for the application we’re working on, we now face a new issue: (extra points if you guessed this one!) a machine learning algorithm deals exclusively with numbers. This is why we need to transform words and sentences into numerical format. Thus, we need to have some features to score words or sentences according to them, and then those scores will represent the sentence numerically.
This is what we will discuss next through two different techniques.
Bag of Words (BoW)
This technique takes in a corpus and returns what we call a Word Index (or a vocab) that consists of the unique words in that corpus, each one assigned to a certain index. This vocab will represent our set of features.
Now each sentence (having whatever length), will be represented according to those features in a fixed-size vector (the vocab size).
But how do we score those features in a sentence?
There are several ways.
One Hot Encoding
In this technique, we score the features according to their presence (1) or absence (0) in a certain sentence. It’s super easy. Let’s look at this example.

Word Count
In this method, we score the features according to how many times they appear in the sentence.
So in our example, the first two sentences stay the same, but the last one changes because “fun” appears twice in the sentence.

Word Frequencies with TF-IDF
I’m sorry, but … let’s go again to school for a quick minute.
Let’s say you’re presenting a project, and your teacher is grading it according to specific features. Suppose one of those features was “creativity”, and another one was “understandability” (a new word I created meaning the ability to understand a certain topic).
Your project was super creative. Your friends’ projects weren’t that much. But, all of the class projects were understandable.
Now for sure, you will be graded for creativity a lot more than you will be for “understandability” because you’re being rewarded for doing something that others didn’t do.
And the same idea applies to the TF-IDF technique.
Think of this approach as a way to give credit for words that are more interesting in a document but not across all documents. We have two factors involved in the analysis:
- Term frequency tf which states how often a given word appears in a document
- Inverse document frequency idf which shows how rare the word is across all documents in the corpus
Just to give you an idea, let’s take the word “fun” from our third sentence:
tfidf = 2 log (3/2) = 0.35
We do the same for all the words, and we get this table where sentences are now “vectorized” into numerical values.

Limitations of Bag of Words (BoW)
a. Sparsity
Suppose you have a huge corpus. Then your vocab size will largely increase, and you’ll end up with a lot of features where your sentences will have a lot of zeros (0) in their representation with just a few ones (1). This is what we call sparsity.
b. No order
This method does not take into consideration the order of your words, and this might affect results in some problems (ex. The two sentences “This was good, not bad”, and “This was bad, not good” will be represented in the same way because they contain the same exact words).
c. Meaning
This technique doesn’t take into consideration the real meaning of the sentence. It’s mainly involved in whether a certain word from a dictionary is or is not present in a sentence.
This is why we need another technique to be more powerful than BoW for some applications.
Word Embeddings
This method consists in learning a representation of the text where words with similar meanings have a similar representation, overcoming some limitations of the BoW. Cool, huh?
Word2Vec
This is one of the earliest and most famous word embedding models, which is literally converting words into vectors. It is an unsupervised learning approach where the model is given a text corpus and it learns an embedding for the words in this corpus.
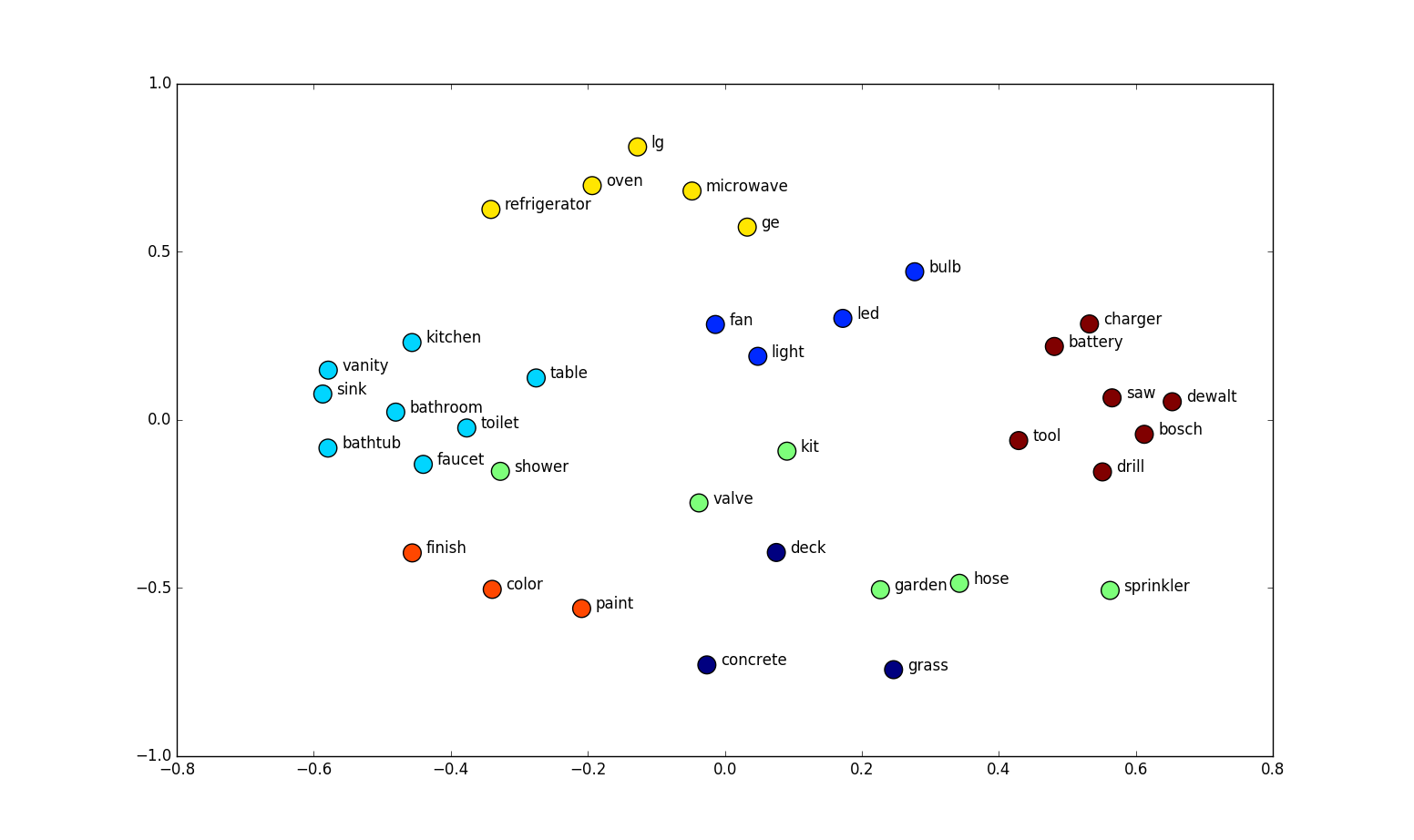
The figure below shows an example where words are represented based on 2 features (since we’re in the XY plane), and I guess it’s clear how words with similar meanings are close to each other.
In real problems, those 2 dimensions are more like 300 dimensions. You can represent words in the n-dimensional space.

Let’s do some NLP math!
Now imagine, after you’ve done that, you can do vector operations on words, the same way you used to do it in Linear Algebra! It’s super interesting! Let’s take an example.
Take a closer look at this picture and try to extract word relations from vector relations.
When we say in Algebra:
This means in NLP that London is to England the same as Rome is to Italy.
Now suppose for some reason, you don’t know the capital of France, but you know that
you can compute the coordinates for the capital of France, and see that it is Paris in the vector space representation.
Take a minute to look at the picture and everything will sound clear!
But how did we get those vectors?
In order for the vector operations to be successful, the words should be at the right place relative to each other, and this requires training. I won’t go into details on how we train Word2Vec models, but I will try to give you an idea that will help you understand it.
The Word2Vec model works by using small neural networks to calculate the word embeddings based on words’ neighboring words, also called the local context. There are two different approaches for Word2Vec models: Continuous bag of words (CBOW) and Continuous Skip-gram model.
The CBOW model
It’s similar to when your teacher (again) in early classes would ask you to fill in the blanks with the appropriate word, and if you choose the correct one, this means that you understood the context of the sentence and the meaning of the word.
So the CBOW model learns the embedding by predicting the current word based on its context.
The skip-gram model
It is similar to when your teacher (no more I promise) asks you to write a sentence that contains a specific word (with some constraints of course). That way, he would make sure you understand in which context such a word could be applied.
So the continuous skip-gram model learns by predicting the surrounding words given a current word.
See? The same techniques that helped you understand the language better, are now a fundamental part of training a machine to understand some semantics!
This Word2Vec model seems powerful, but how about we integrate it into our existing deep learning models?
Deep Learning and Embedding Layer
Instead of applying an existing word embedding model on the dataset, we introduce a new layer to the model called the Embedding layer. This layer will learn the word embedding jointly with the network, while training, and your network will end up looking like this.
Conclusion
I guess this is it! You’ve just learned the basics of NLP, and I’m pretty sure by now that you’ve gotten a better understanding of what happens on the other side of a great NLP application. I’m also sure that when an NLP application doesn’t get you well, you’ll be more understanding than before.
I really hope you enjoyed what we discussed. Now that our journey has come to an end, I really encourage you to go way beyond that and start doing some great things in NLP. Just keep in your mind that everything starts with a first step, and trust me, you just did it.
Interested to start your journey in Machine learning? Register today to Zaka’s live virtual Artificial Intelligence Bootcamp and get ready to develop your knowledge in AI!
Don’t forget to support with a clap!
You can join our efforts at Zaka and help democratize AI in your city! Reach out and let us know.
To discover Zaka, visit www.zaka.ai
Subscribe to our newsletter and follow us on our social media accounts to stay up to date with our news and activities:

{kind=link}
{kind=link}
{kind=link}