Andreas KunarGPU-Accelerated Containers for M1/M2/M3… MacsApple silicon Macs with MacOS always had a major shortcoming for me — their GPUs were not useable in containers or virtual machines (VMs)…Jun 20Jun 20
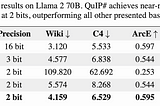
Andreas KunarBreaking News: Run Large LLMs Locally with Less RAM and Higher Speed through llama.cpp with QuIP#A recent update to llama.cpp enables a new “crazy-sounding, but useable” 2-bit quantization for LLMs — QuIP: Quantization with Incoherence…Jan 111Jan 111
Andreas KunarBenchmarking Apple’s MLX vs. llama.cppIt might be a bit unfair to compare the performance of Apple’s new MLX framework (while using Python) to llama.cpp (written in C/C++ using…Dec 23, 20231Dec 23, 20231
Andreas KunarRunning Mixtral AI on your MacMistral AI’s new Mixtral AI model to me is a breakthrough — with its GPT3.5-like answer-quality, excellent additional French, German…Dec 15, 20232Dec 15, 20232
Andreas Kunarllama.cpp Performance & Apple Siliconllama.cpp enables running Large Language Models (LLMs) on your own machine. Their CPUs, GPUs, RAM size/speed, but also the used models are…Dec 2, 2023Dec 2, 2023
Andreas KunarThoughts on Apple Silicon Performance for Local LLMsApple silicon, with its integrated GPUs and unified, large, wide RAM looks very tempting for AI work. Especially when using Georgi…Nov 25, 20234Nov 25, 20234