Arpita MishraKey Interview Questions and Expert Insights on Optimization and Data Handling — Part 21) What are some ways to optimize Spark jobs?6d ago6d ago
Arpita MishraBeginner’s Guide to PySpark Interview Questions: RDDs, DataFrames, and Transformations — Part 11) What is PySpark, and how does it differ from Apache Spark?Jul 9Jul 9
Arpita MishraAll-In-One SQL Guide: From Fundamentals to Performance TuningSQL (Structured Query Language) is a standardized programming language used for managing and manipulating relational databases. It allows…Jul 4Jul 4
Arpita MishraBeginner’s Guide for E-commerce Analytics using PySpark : Advanced Syntax and Use Cases for Top…Let’s consider a practical scenario where we have a large dataset of e-commerce transactions, and we want to analyse customer purchasing…Jun 27Jun 27
Arpita MishraFrom Basics to Advanced: Navigating Apache Hive for Big Data ProfessionalsApache Hive is a data warehousing and SQL-like query language for Hadoop. Developed by Facebook, it is now a part of the Apache Software…Jun 23Jun 23
Arpita MishraMastering Apache Spark: Key Concepts and Practical TipsApache Spark is an open-source, distributed computing system designed for fast and general-purpose big data processing. Developed at UC…Jun 15Jun 15
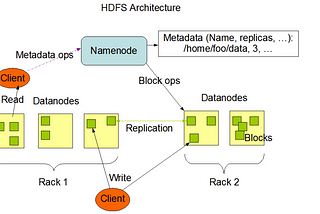
Arpita MishraIntroduction to Bigdata and Hadoop EcosystemThe big data ecosystem is a comprehensive suite of technologies and tools designed to handle the complexities of managing, processing, and…Jun 7Jun 7
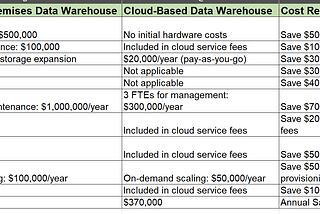
Arpita MishraRevolutionize Your IT Budget: Cost Analysis of Cloud Data Warehousing SolutionsIn today’s fast-paced digital landscape, optimizing IT budgets while maintaining robust data management is crucial. Cloud data warehousing…Jun 5Jun 5
Arpita MishraRedefining Data Management: Modern Data Warehousing and Its FutureA modern data warehouse is a cloud-based, scalable, and highly flexible data storage solution designed to handle large volumes of diverse…Jun 3Jun 3