Using Open-Source Tools and MongoDB to Build a RAG Pipeline From Scratch

Background
Last week, the fate of OpenAI as we all knew it was at risk. Sam Altman, CEO of OpenAI, was fired seemingly without warning. The root cause of this firing is unknown, but some people speculated that OpenAI achieved AGI internally, which prompted the board to hastily let the CEO go in an effort to save humanity. Whether it was a publicity stunt or the board had genuine reasons, this chaos serves as a poignant reminder of the fragility inherent in depending solely on platforms like OpenAI, which, despite their size and success, are not immune to operational disruptions. Such events could potentially lead to the abrupt cessation of critical AI services, impacting a multitude of dependent applications.
This realization highlights the imperative need for reliable alternatives to proprietary AI platforms. While existing solutions like Claude, Bard, and Bing offer some respite, the true potential for sustainable and independent application development lies within the realm of open-source technology.
However, navigating the open-source landscape, particularly in the domain of language models, can be a daunting task. Even for someone like me with a background in Artificial Intelligence and experience in developing neural networks, the complexity of open-source Large Language Models (LLMs) presents a significant challenge.
The breakthrough came with the discovery of Ollama, a versatile tool that simplifies the deployment of models. Ollama distinguishes itself by offering a comprehensive range of open-source models, accessible via straightforward API calls. In testing, certain models, such as codebooga, not only matched the capabilities of established models like ChatGPT 3.5, but it exceeded them. Beyond model diversity, Ollama also integrates seamless embedding generation, offering a cohesive and efficient API experience. In the wake of the recent upheavals at OpenAI, Ollama presents a viable and robust alternative, providing a much-needed safety net for AI projects.
Armed with the capabilities offered by Ollama, the next step was to enhance NexusGenAI, my Next–Generation AI Configuration Platform. The objective was ambitious yet clear: to develop a RAG pipeline leveraging open-source models and reduce our reliance on OpenAI’s APIs.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) is an approach in natural language processing that merges the capabilities of a retrieval system with a generative language model. This method involves three primary steps: storing critical information, retrieving relevant data, and enhancing the original query with the appropriate context.
Consider a scenario where you need an AI to produce responses tailored to your specific business needs. For instance, you want it to generate code utilizing patterns and libraries characteristic of your company’s codebase. While a model like ChatGPT is trained on a broad spectrum of data, it lacks specific insights about your business. To address this, you might opt to upload all pertinent data into a database, which can be queried later.
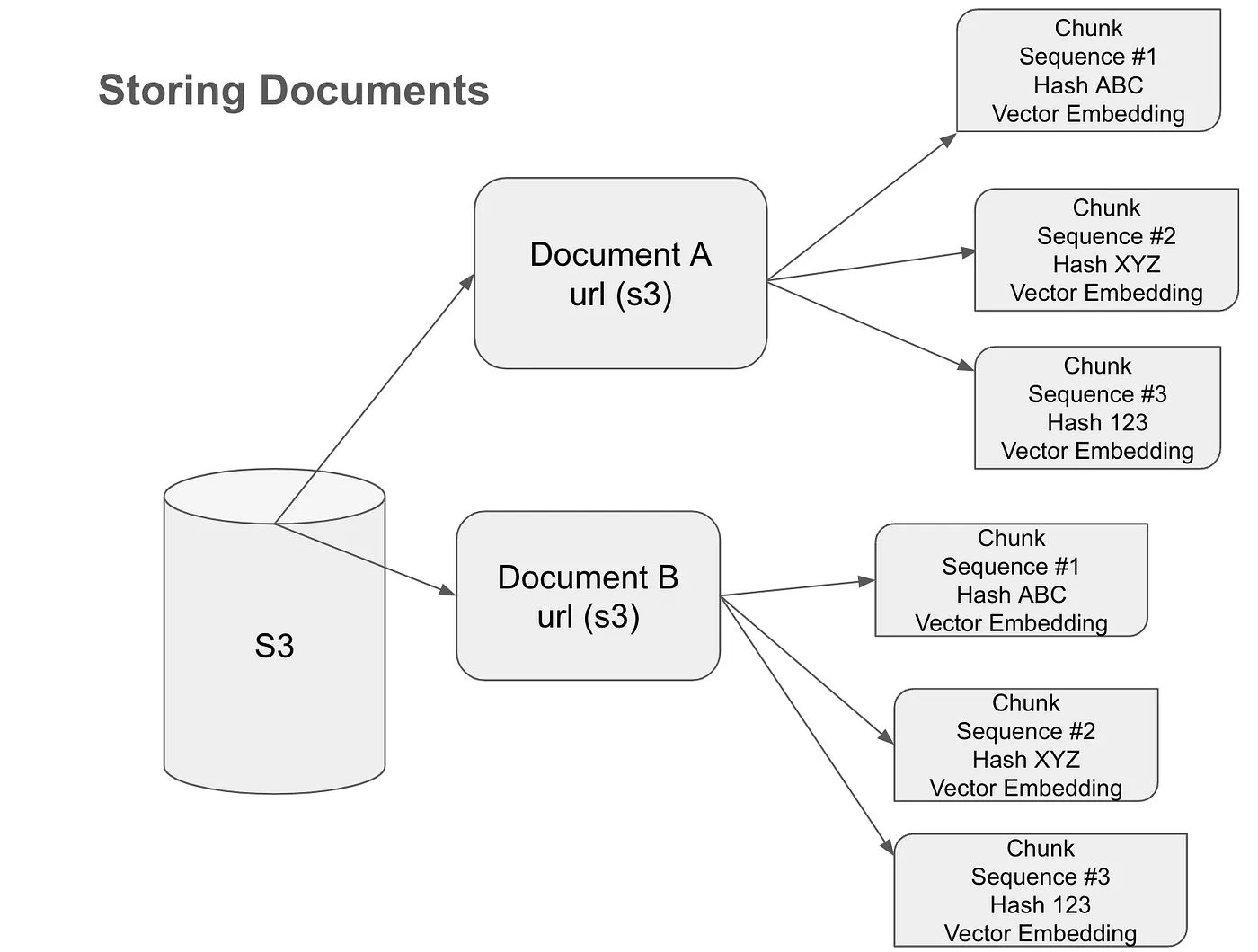
This database stores chunks of documents, along with their embeddings, making it a reservoir of information. When you pose a language query, the system also searches this database for additional context. This process is similar to how one would scour various resources to compile information for a research project.
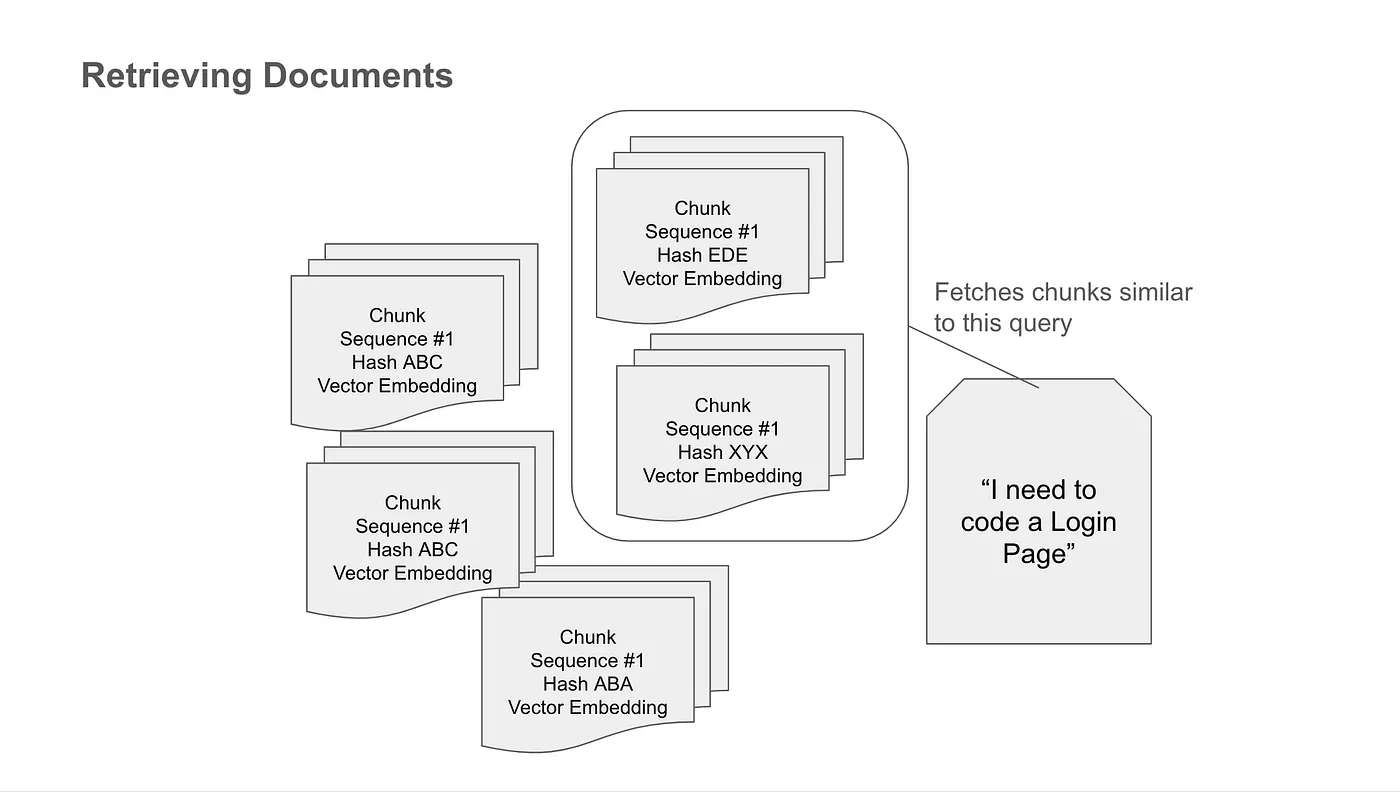
The system employs a similarity searching algorithm to fetch relevant data segments. In this process, both the original query and the relevant context are fed into the Large Language Model (LLM), resulting in a more pertinent and informed response.

Retrieval Augmented Generation (RAG) has a wide array of applications, including AI-powered agents, AI pair programmers, and AI-Guided trading. For instance, NexusTrade’s AI-powered chat leverages the NexusGenAI configuration platform, enabling users to devise and evaluate complex algorithmic trading strategies without needing to write any code. For those interested in developing AI applications, understanding how to set up a RAG pipeline is crucial. This method enhances the capability of AI systems to deliver more precise and contextually relevant outputs, making them more effective and valuable in various practical applications.
Setting up a Retrieval Augmented Generation (RAG) Pipeline in Under 15 Minutes: Enhancing AI Programming Agents with Contextual Knowledge
In this article, I’ll guide you through setting up a RAG pipeline, specifically tailored for developing an AI Programming Agent, in less than 15 minutes.
Environmental Setup (approximately 3 minutes)
Our journey begins with setting up the environment for Ollama, which is compatible with all environments.
- If you’re on Windows or Linux, run the following command
curl https://ollama.ai/install.sh | shIf you’re on MacOS, just click the link in the Ollama repo and download it.
Once Ollama is installed, launch it using this simple command:
ollama run llama2Ollama offers a variety of models to experiment with, including llama2 and several coding-specific models. For a full list, refer to Ollama’s official library.
After verifying that the Ollama library is functioning correctly, start the server with the command:
ollama serveIf you encounter an error like Error: listen tcp 127.0.0.1:11434: bind: address already in use, it typically indicates that Ollama is already running in the background.
This setup process is designed to be user-friendly and efficient, echoing the simplicity of creating a ChatGPT account, but with the added capability to integrate a rich variety of models suitable for various AI development needs. With the environment set, you’re now ready to embark on the actual construction of the RAG pipeline, unlocking a new level of context-aware coding assistance.
Chunking text (approximately 3 minutes)
Once the environment and model setup are complete, the next critical step in establishing an efficient RAG pipeline is text chunking. This process involves extracting and segmenting the text from your documents, which will later be used for retrieval and augmentation in the RAG system.
Extracting Text from Documents
The ease of text extraction depends largely on the format of your documents. For simple text files, the extraction is straightforward. However, more complex document types like PDFs or Word documents require additional steps:
- Utilize libraries such as
pdf-parsefor PDFs andmammothfor Word documents. These tools are adept at extracting text while preserving the essential formatting and structure. - Once extracted, the text can be stored in an accessible location, such as Amazon S3 or a database. This ensures that the data is ready for subsequent processing and retrieval.
Intelligent Document Chunking
With the full document text at hand, the challenge is to segment or ‘chunk’ the text in a manner that aligns with the needs of the RAG pipeline. The naive approach is to cut the text in equal segments of x characters. However, this strategy has drawbacks, such as cutting off in the middle of a word. Keeping in tune with using open-source models, I decided to use codebooga to assist in developing an intelligent chunking algorithm.
After experimenting with a few prompts, I developed a component capable of effectively chunking text. This algorithm goes beyond traditional chunking methods, which often risk cutting off sentences midway. Instead, it’s designed to be contextually aware, aiming to separate sections of text logically and meaningfully. When the ‘submit’ button is clicked, this tool not only chunks the document but also generates embeddings for each segment.
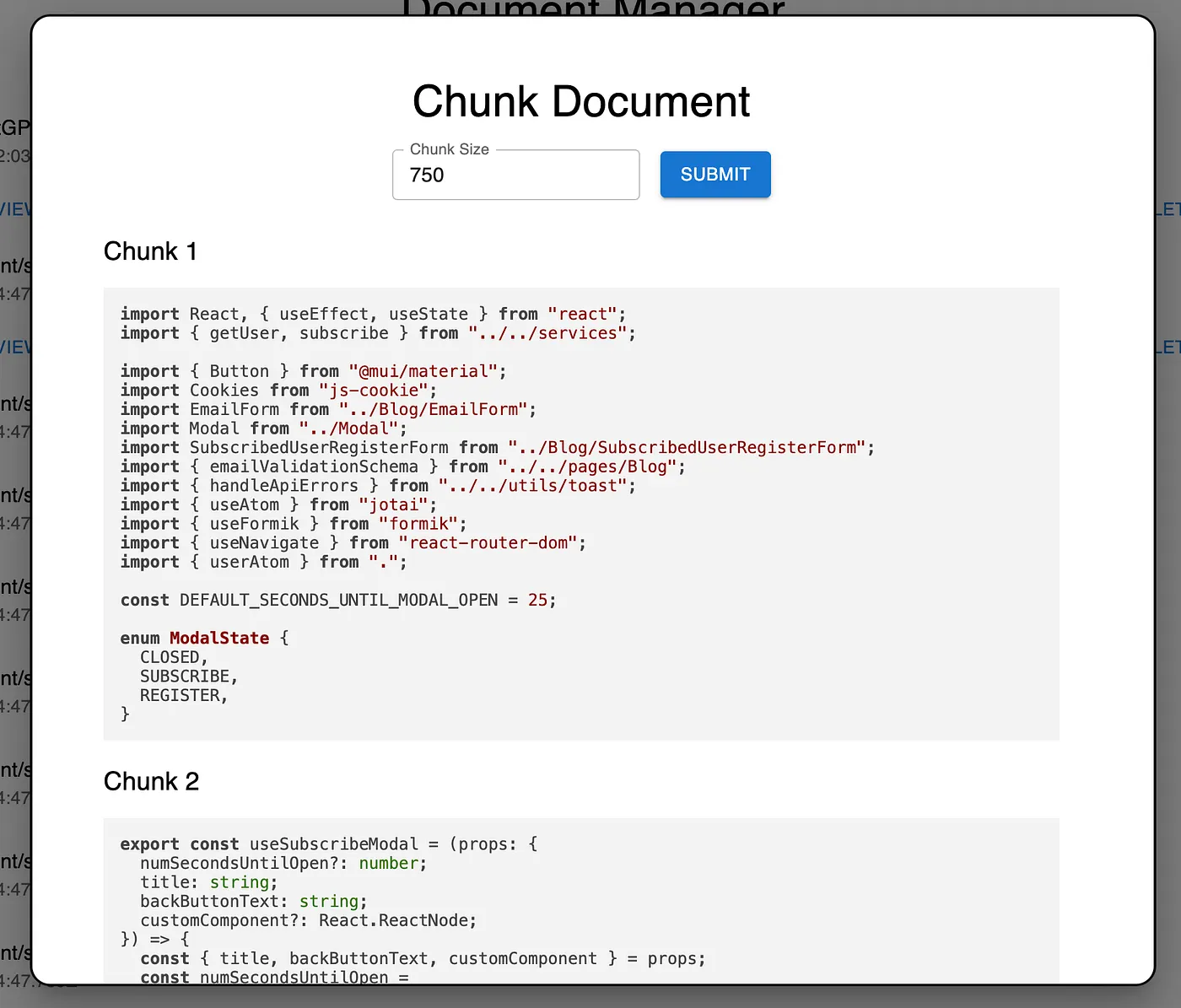
The User Interface for this intelligent document chunker is key to its functionality. It provides a user-friendly platform to input text, execute the chunking process, and visualize the resulting segments along with their embeddings. This tool is essential for preparing the text for the next phase in the RAG pipeline: vectorization.
Vectorizing Text (approximately 3 minutes)
Once the text is chunked, the next step is to convert these chunks into vectors, a process made straightforward with Ollama. Vectorization is crucial as it transforms the text into a format that can be efficiently processed and retrieved by the RAG system. In Ollama, this is achieved using a simple API call:
curl http://localhost:11434/api/embeddings -d '{
"model": "llama2",
"prompt": "Here is an article about llamas..."
}'For the specific application of creating an AI-Powered Pair Programmer, I decided to vectorize the entire source code of the src/client directory. This approach ensures that the AI has access to a comprehensive representation of the codebase, enhancing its ability to provide relevant and context-aware programming assistance.
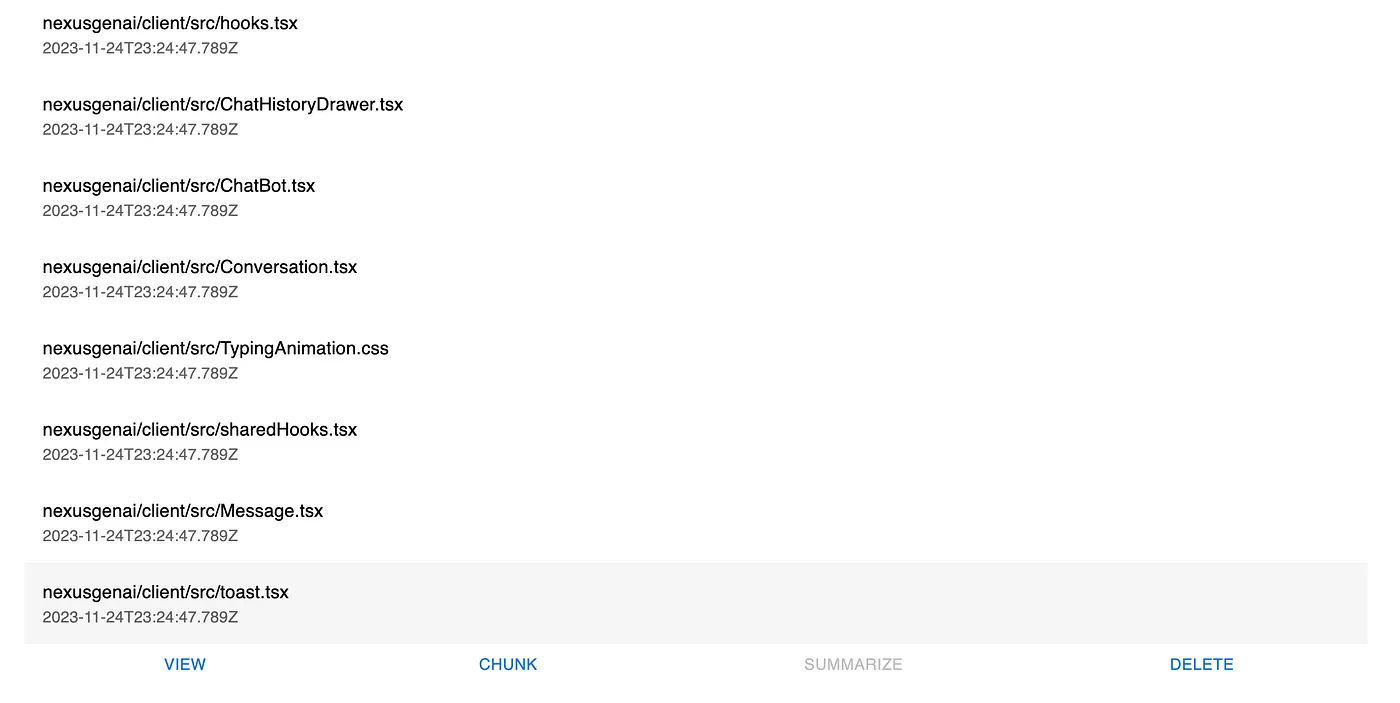
Retrieving Vectors (approximately 3 minutes)
Retrieving vectors is a critical step in setting up a RAG pipeline. This involves creating and fetching vector representations of the stored documents or data chunks, which are essential for the similarity searching algorithm used later in the pipeline.
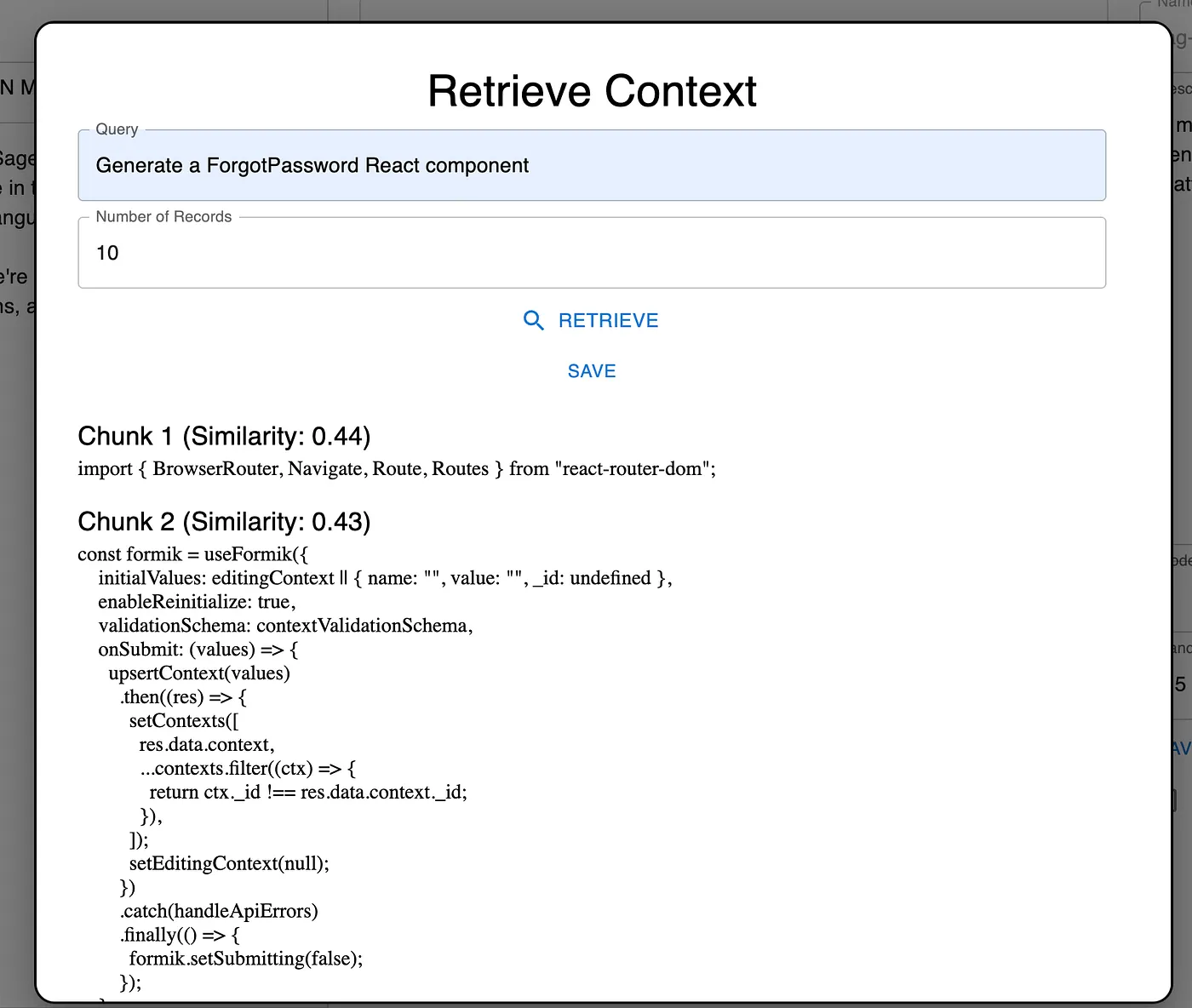
Because I’m using MongoDB, which really isn’t built for Vector similarity search, I had to implement my own function for performing similarity searching. This looked like the following
static async findSimilarChunks(
tenantId: Id,
text: string,
numRecords: number,
client: GenerativeAIServiceClient
) {
const embeddings = await client.embeddings(text);
const batchSize = CHUNK_BATCH_SIZE;
let hasMore = true;
let skip = 0;
let similarChunks: { id: string; similarity: number }[] = [];
while (hasMore) {
const batch = await DocumentChunkModel.find({
tenantId: tenantId,
vector: { $ne: null },
})
.skip(skip)
.limit(batchSize);
if (batch.length === 0) {
hasMore = false;
} else {
batch.forEach((chunk) => {
const similarity = cosineSimilarity(embeddings, chunk.vector);
similarChunks.push({ id: chunk._id.toString(), similarity });
});
skip += batch.length;
}
}
// Optionally sort the results by similarity
similarChunks.sort((a, b) => b.similarity - a.similarity);
return similarChunks.slice(0, numRecords);
}End Result
Before Implementing a RAG Pipeline
Initially, when I used a basic prompt to generate a Forgot Password Page, the result was purely in HTML format, which was unsuitable for my React-based application.
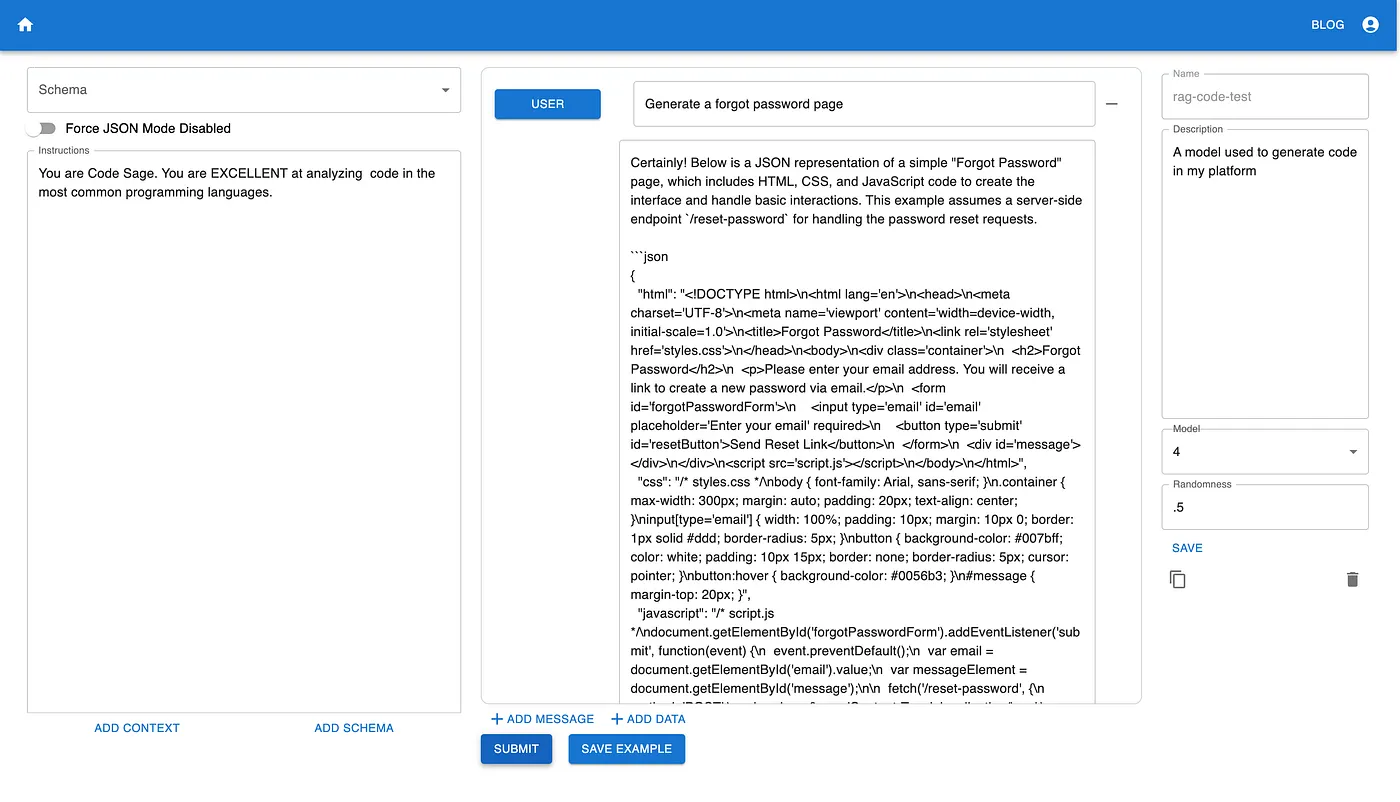
Even after refining the prompt, the AI continued to deliver subpar React code.

Theoretically, I could have went through my code-base and copy/pasted some examples, but this would’ve been time-consuming.
After Implementing a RAG Pipeline
Post-implementation of the RAG pipeline, the results were astonishingly different. The generated code was highly relevant and could be integrated almost directly into the application.
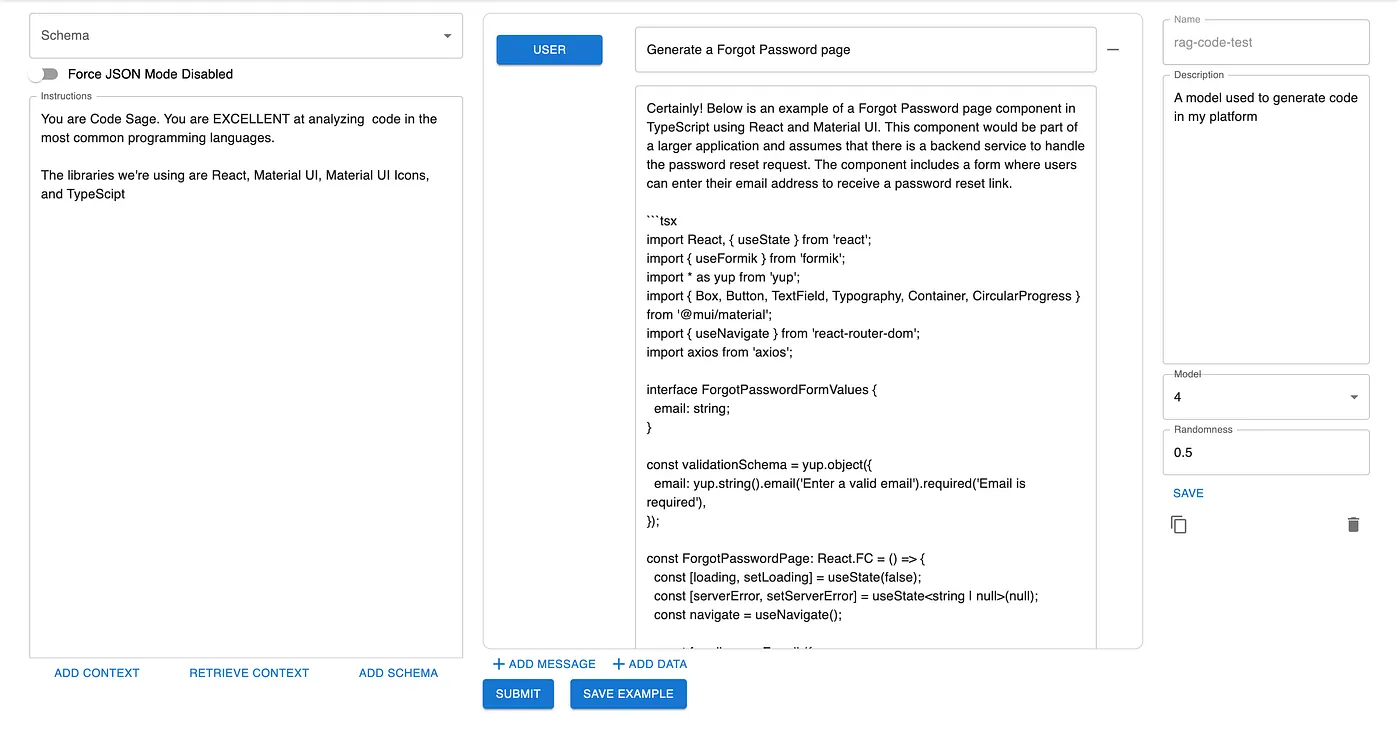
This marked improvement was achieved with just 15 minutes of effort in setting up the pipeline. And this is just the beginning!
Areas of Improvement
The RAG pipeline still has room for refinement. For example, summarizing each chunk using Large Language Models (LLMs) could provide richer context in our vector database. Additionally, we could attempt to decipher the user intent from the request, and enrich the input with additional information that may make it easier to search for in the database. Finally, we could experiment with our chunks, making them bigger or smaller, or adding or removing some. All of these configuration options are available in NexusGenAI.
Conclusion
The entire process of setting up a RAG pipeline, especially with NexusGenAI, turned out to be remarkably straightforward and efficient. The ease with which documents can be uploaded and integrated into an AI application using NexusGenAI streamlines the process significantly.
This endeavor comes at a time when the AI world was almost turned upside down by Sam Altman’s departure. While he recently rejoined OpenAI, the chaos that ensued highlights the growing importance and capability of open-source models in the AI landscape. The simplicity and power of the RAG pipeline, all seamlessly integrated into NexusGenAI, demonstrate that reliable, effective AI solutions can be developed independently of major AI platforms. This is a promising development for those seeking to harness the power of AI while maintaining control and flexibility in their applications. The success of this project reinforces the notion that with tools like NexusGenAI, the potential of AI is not only accessible but also within the grasp of any developer looking to push the boundaries of technology.
Thank you for reading! Stay tuned for more content related to LLMs and AI. Interested in applying AI to finance? Subscribe to Aurora’s Insights! Want to try out the AI-Chat for yourself? Create an account on NexusTrade today!
