Flash Loans, The Graph, and Triangular Arbitrage : Spot Opportunities Like Tony Soprano Pt I.

If you want to cash in like Tony Soprano, you need to spot opportunities like him too. Finding profitable opportunities in today’s decentralized markets can be a daunting task. With the overwhelming amount of data in decentralized markets, this task has only gotten more challenging. However, by utilizing tools like The Graph, traders can gain a critical advantage in discovering and exploiting triangular arbitrage opportunities — just like Tony would have. The result? Increased profitability and success in the market.
Prerequisites
- Understanding of graph data structures
- Knowledge of the Uniswap CFMM model (V2)
What we’ll cover
- Queries to The Graph for subgraph data
- An algorithm to discover undirected simple cycles
Calls to The Graph
We will focus on three decentralized markets, Uniswap V2, Uniswap V3, and Sushiswap. Their subgraphs all contain similar schemas, which affords us flexibility in building our GraphQL queries.
Building our calls to The Graph, we take the following end points for each DEX and input them into a standard Axios post request.
- Uniswap V3
https://api.thegraph.com/subgraphs/name/uniswap/uniswap-v3 - Uniswap V2 https://api.thegraph.com/subgraphs/name/uniswap/uniswap-v2
- Sushiswap https://api.thegraph.com/subgraphs/name/sushiswap/exchange
async function axios_call(query) {
try {
const url = '--- end point ---';
const { data } = await axios.post(url, query);
return data;
} catch (error) {
console.error(error);
}
}Now that we have our Axios requests set up, what data do we exactly need from our liquidity pools?
- Liquidity pools UUID
- Token reserves
- Token prices
- Token UUIDs
- Token decimal points (important later for on chain calls)
Considering a single DEX can host thousands of liquidity pools at a time this seems like a pretty large scope. One way we can narrow this down is by asking, when do arbitrage opportunities arise?
Arbitrage opportunities are almost always triggered by higher market volume. So we should focus our indexing around volume. Luckily for us, each subgraph we are working with offers a few parameters for us to use.
Take for example the following GraphQL queries and the parameters.
---- GraphQL for uniswap V2 and sushiswap -----
{
pairHourDatas(first: 1000, orderBy: hourlyTxns, orderDirection: desc, where: {hourStartUnix_gte:${-- unix timestamp --}}){
pair {
id
reserve0
reserve1
token0Price
token1Price
token0 {
symbol
id
decimals
derivedETH
}
token1 {
symbol
id
decimals
derivedETH
}
}
}
}---- GraphQL for uniswap V3 -----
{
poolHourDatas(first: 1000, orderBy: txCount, orderDirection: desc, where: {periodStartUnix_gte: ${-- unix timestamp -- }}){
pool {
id
feeTier
token0Price
token1Price
liquidity
tick
sqrtPrice
token0 {
symbol
decimals
id
derivedETH
}
token1 {
symbol
decimals
id
derivedETH
}
}
}
}The parameters index for LPs (liquidity pools) with high USD volume and high transaction volume. Additionally, the ‘where’ parameter offers us some flexibility by specifying a time frame as a unix timestamp (useful if you plan to schedule tasks).
Passing each of the GraphQL queries to its respected Axios post request, the returned response is an array of liquidity pools for each DEX.

Although each subgraph contains similar schemas, there are slight differences in the naming conventions of each one; therefore, we need to prepare our subgraph data by formatting each liquidity pool to have the same key names. Once we have formatted each array, we merge them and pass the data to our mapping algorithm.
Building Our Algorithm
We need to think of our collected data as a massive graph, where each vertex of the graph is a token and its edges are liquidity pools.

The issue is finding the path between each token, which can be viewed as a simple DFS (depth first search) problem. What we need to return is an undirected cyclic subgraph with three vertices represented as liquidity pools.
Considering our subgraph data as a simple DFS problem, we can break down our algorithm into a few stages:
- De-structuring the subgraph data
- Base graph and spanning tree builds
- Finding all undirected cyclic cycles with token UUIDs
- Rebuild the cycle to contain liquidity pool data
- Calculate potential profitability
Starting point
produce_simple_paths( ) — is the initial function that takes the subgraph data and produces a profitable triangular arbitrage opportunity.
function produce_simple_exchange_paths(subgraph_data) {
const path_keys_and_ids = [];
const [pairUUID, poolAddresses] =
get_multiple_objects_for_mapping(exchangeObject);
const { graph, poolAddress } = build_adjacency_list(poolAddresses, pairUUID);
const tree = get_tree(graph);
const cycles = get_all_cycles(graph, tree);
for (const cycle of cycles) {
const keys = build_base_to_quote_keys(cycle, poolAddress);
path_keys_and_ids.push({ keys: keys, token_ids: cycle });
}
return path_keys_and_ids;
}I. De-structuring our subgraph data
Using get_multiple_objects_for_mapping( ), we produce three distinct hash-maps by de-structuring our subgraph data.
function get_multiple_objects_for_mapping(
exchangeObject,
pairUUID = {},
poolAddresses = {},
poolInfo = {}
) {
for (const pair of exchangeObject) {
const key1 = `${pair.token0.id}-${pair.token1.id}`;
const key2 = `${pair.token1.id}-${pair.token0.id}`;
pairUUID[pair.token0.id]
? pairUUID[pair.token0.id].add(pair.token1.id)
: (pairUUID[pair.token0.id] = new Set([pair.token1.id]));
pairUUID[pair.token1.id]
? pairUUID[pair.token1.id].add(pair.token0.id)
: (pairUUID[pair.token1.id] = new Set([pair.token0.id]));
poolAddresses[key1]
? poolAddresses[key1].add(`${pair.id}`)
: (poolAddresses[key1] = new Set([`${pair.id}`]));
poolAddresses[key2]
? poolAddresses[key2].add(`${pair.id}`)
: (poolAddresses[key2] = new Set([`${pair.id}`]));
pair.token_ids = [pair.token0.id, pair.token1.id];
poolInfo[pair.id] = pair;
}
return [pairUUID, poolAddresses, poolInfo];
}The pairUUID hash-map is used to build our base graph and spanning tree in order to discover possible cycles. Rather than using the liquidity pools UUID as the edges, a custom key is used in order to find our cycle. The key consists of two token UUIDs separated with a hyphen ‘-’.
After we find all possible cycles containing token UUIDs the poolAddress hash-map is utilized to find the liquidity pool UUID. Finally, once we retrieve the LPs UUID, it’s used as a key to pull the its information from the poolInfo hash-map.
II. Base Graph and Spanning Tree
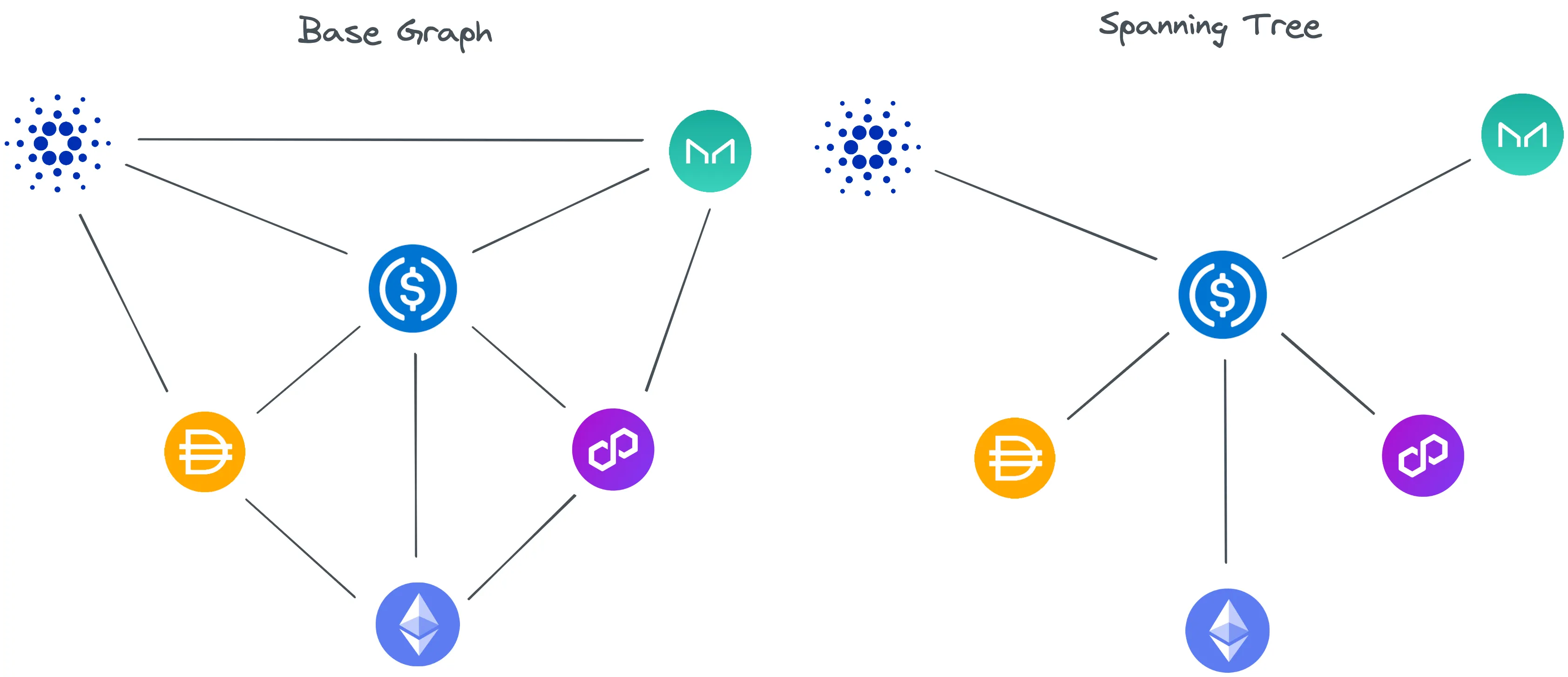
The two graphs are both used to discover our cycles. Our first graph represents our base graph. It contains all the token UUIDs as vertices and all its corresponding neighbors.
function build_adjacency_list(poolAddress, pairSymbols) {
const vertArr = [];
for (const key in poolAddress) {
poolAddress[key] = Array.from(poolAddress[key]);
}
for (let key in pairSymbols) {
let verticeObj = {
vertex: key,
neighbors: Array.from(pairSymbols[key]),
};
vertArr.push(verticeObj);
}
let graph = {
vertices: vertArr,
};
return { graph, poolAddress };
}Our second graph represents a spanning tree, which is constructed as a hash-map. We build our spanning tree by iterating over our base graph, then input the corresponding tokens. Throughout the iteration, a visitedVerticies set is maintained and if a token is not found in this set we add it to our spanning tree.
function get_tree(graph) {
const spannigTree = new Map();
for (const coin of graph.vertices) {
spannigTree.set(coin.vertex, new Set());
}
let visitedVertices = new Set();
graph.vertices.forEach((node) => {
node.neighbors.forEach((child) => {
if (!visitedVertices.has(child)) {
visitedVertices.add(child);
spannigTree.get(node.vertex).add(child);
spannigTree.get(child).add(node.vertex);
}
});
});
return spannigTree;
}III. Finding Our Undirected Path
Taking both our base graph and spanning tree, we pass them to get_all_cycles( ), which performs a traversal on the spanning tree. In order to find a cycle, we use ‘removed edges’ between tokens produced from our get_rejected( ).
function get_all_cycles(graph, spannigTree) {
let cycles = [];
let rejectedEdges = get_rejected(graph, spannigTree);
rejectedEdges.forEach((edge) => {
const ends = edge.split('-');
const start = ends[0];
const end = ends[1];
const cycle = find_cycle(start, end, spannigTree);
if (cycle && cycle.length <= 3) {
cycles.push(cycle);
}
});
return cycles;
}get_rejected( ) — finds the ‘removed edges’ as we iterate through our base graph and build our spanning tree. If a token in the spanning trees corresponding set is not present, it is considered a ‘removed edge’ and thus part of a possible cycle.
function get_rejected(graph, tree) {
let rejectedEdges = new Set();
graph.vertices.forEach((node) => {
if (tree.has(node.vertex)) {
node.neighbors.forEach((child) => {
if (!tree.get(node.vertex).has(child)) {
if (!rejectedEdges.has(child + '-' + node.vertex)) {
rejectedEdges.add(node.vertex + '-' + child);
}
}
});
}
});
return rejectedEdges;
}A cycle can be found in the base graph that connects the two ends of the removed edge. As the spanning tree does not contain any cycles, a path can be traced from any token to another. By tracing the cycle between both ends of the removed edge within the Spanning Tree, a path can be obtained.

Utilizing the removed edge, we split it and pass the starting token and end token to the find_cycle( ), which recursively performs a DFS traversal on our spanning tree.

The recursion ends when the end vertex is reached or when all vertices are visited. Once the end vertex is reached, the path taken to reach it is considered a cycle.
function find_cycle(
start_token,
end_token,
spannigTree,
visited = new Set(),
parents = new Map(),
current_node = start_token,
parent_node = ' '
) {
let cycle = null;
visited.add(current_node);
parents.set(current_node, parent_node);
const destinations = spannigTree.get(current_node);
for (const destination of destinations) {
if (destination === end_token) {
cycle = get_cycle_path(start_token, end_token, current_node, parents);
return cycle;
}
if (destination === parents.get(current_node)) {
continue;
}
if (!visited.has(destination)) {
cycle = find_cycle(
start_token,
end_token,
spannigTree,
visited,
parents,
destination,
current_node
);
if (cycle) {
return cycle;
}
}
}
return cycle;
}Finally, when a path is discovered, the get_cycle_path( ) is invoked. It backtracks the spanning tree from the end to the start and validates the cycle. The returned result is a nested array of token UUIDs.
function get_cycle_path(start, end, current, parents) {
let cycle = [end];
while (current !== start) {
cycle.push(current);
current = parents.get(current);
}
cycle.push(start);
return cycle;
}

IV. Rebuilding Our Cycles
Rebuilding our cycles is comprised of two steps. First, we get the paths liquidity pool UUIDs. Second, we get the liquidity pool information. Utilizing both hash-maps built during de-structuring, this process is simplified.

In order to find our liquidity pool UUIDs we iterate over our array of token paths and call build_base_to_quote_keys( ).
function build_base_to_quote_keys(cycle, poolAddress) {
const [first_token_id, second_token_id, third_token_id] = cycle;
const first_pool_key = `${first_token_id}-${second_token_id}`;
const second_pool_key = `${second_token_id}-${third_token_id}`;
const third_pool_key = `${third_token_id}-${first_token_id}`;
const addresses = [
poolAddress[first_pool_key],
poolAddress[second_pool_key],
poolAddress[third_pool_key],
];
const all_paths_from_cycle = get_all_address_permutations(addresses);
return all_paths_from_cycle;
}Each token has a compliment (according to its indexed position) is re — joined to build a token key. We take each token key and pass them to our poolAddress hash-map, which pulls our liquidity pool UUID. There may be some occasions when our token keys pull multiple UUIDs. In other words, other exchanges have the same token pairings.

Based on the above, the get_all_address_permutations( ) takes the array of liquidity pool UUIDs and returns all its permutations.
function get_all_address_permutations(
addresses,
loop = 0,
result = [],
current = []
) {
if (loop === addresses.length) {
result.push(current);
} else {
addresses[loop].forEach((item) => {
get_all_address_permutations(addresses, loop + 1, result, [
...current,
item,
]);
});
}
return result;
}Each produced permutation is considered a cycle with the same token path, but with a different liquidity pool to trade in. After the process is complete, we will have a list of elements that contain the initial token UUID path and an array of liquidity pool UUIDs representing unique trading paths.
Whats next?
In part 2, we explore the methods and tools necessary to determine the profitability of discovered triangular arbitrage opportunities in decentralized markets. Traders can leverage this knowledge to take advantage of these opportunities and improve their chances of success.
We will delve into how we make on-chain data calls to vet each potential discovered path. Check out part 2 to gain valuable insights that can help you elevate your trading game and achieve increased profitability in the market : Flash Loans, The Graph, and Triangular Arbitrage : Spot Opportunities Like Tony Soprano Pt II.
Sources and Further Reading
- Finding simple cycles in further depth
- The Graph — our Blockchain Indexing Protocol
- Uniswap V3 Development Book
New to trading? Try crypto trading bots or copy trading on best crypto exchanges
Join Coinmonks Telegram Channel and Youtube Channel get daily Crypto News
