Bibhusha OjhaVisualize Data Lake (S3) with Amazon QuicksightDon’t just store data, visualize it!Apr 1Apr 1
Bibhusha OjhaKaffeinated Code: Brewing Up Kafka Basics with Docker ImagesGet ready to sip on the future of data pipelines — because your next cup of code is brewing right now!Jan 21Jan 21
Bibhusha OjhaA Beginner’s Guide to Apache Spark: Introduction and Key ConceptsBig data, bigger dreams!Dec 28, 2023Dec 28, 2023
Bibhusha OjhaBuilding a Serverless Streaming ETL Architecture on AWS LambdaIn today’s data-driven landscape, organizations grapple with continuous streams of real-time data, requiring agile Extract, Transform, Load…Dec 25, 2023Dec 25, 2023
Bibhusha OjhaLoading Parquet files into Redshift from Amazon S3Parquet is a columnar storage format that optimizes data for analytics workloads, while Amazon Redshift is a high-performance, fully…Dec 1, 2023Dec 1, 2023
Bibhusha OjhaLoad Nested JSON data into Redshift using AWS GlueAWS Glue is a fully managed ETL (Extract, Transform, Load) service that streamlines the data integration process. It offers a…Nov 22, 2023Nov 22, 2023
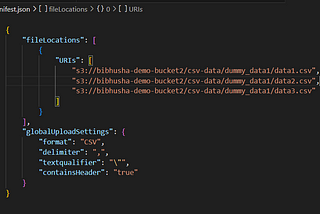
Bibhusha OjhaLoad CSV into Redshift using AWS GlueAmazon Redshift is a cloud data warehouse that uses SQL to analyze structured and semi-structured data. In this tutorial, we will go…Nov 8, 2023Nov 8, 2023
Bibhusha OjhaKafka vs Kinesis: A Tale of Two StreamsWhich one is right for your organization?Oct 1, 2023Oct 1, 2023
Bibhusha OjhaStreaming Data Pipeline: Kafka, Spark, S3, Lambda, Glue, Redshift, and Quicksight IntegrationAs organizations struggle with ever-growing volumes of data, the need for a well-orchestrated pipeline becomes paramount. The efficiency…Sep 18, 2023Sep 18, 2023