Machine Learning 101
In the previous part — Part 7: Ensemble Learning & Random Forest, we learned about the different Ensemble Learning techniques, the Random Forest algorithm, and their working using examples.
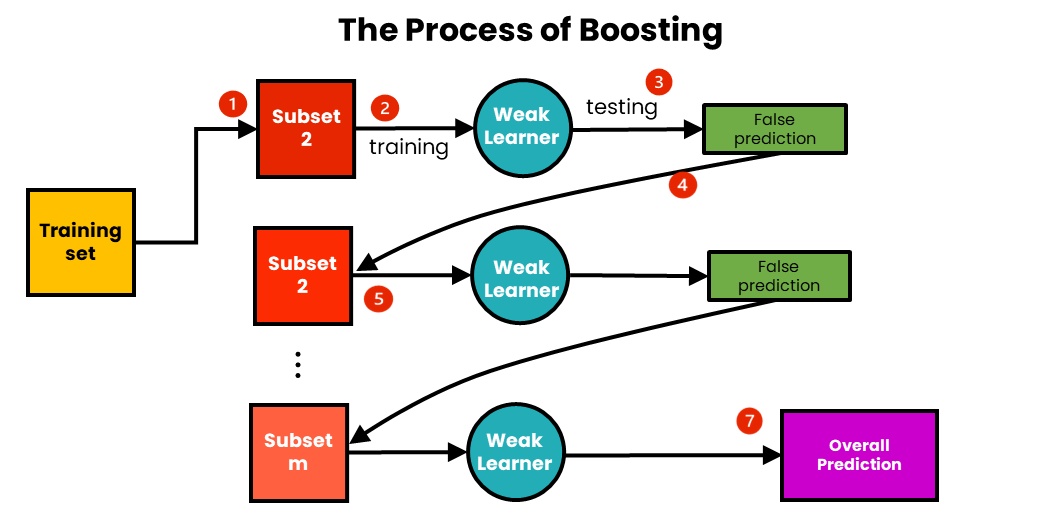
Boosting is one of the important Ensemble Learning techniques. Let’s try to understand it using an example —

{kind=link}
Suppose, there is a study group, where each student is good in one subject but struggles in another. The study group takes one subject at a time for understanding. In the first round, they selected mathematics and the student who was an expert in mathematics helped the rest of the group understand it.
Next, the student who is weak in mathematics is given more assistance and guidance. In every round, the subject expert helps the study group to understand a subject, and the student with weaknesses in the subject is given more attention. As a result, the performance of the overall study group is improved.
The Boosting technique is a sequential technique where each base model acts as a weak learner that learns from the mistakes and errors made by the previous models. As a result, it improves the model’s overall performance.
Here, the students act as the base models or weak learners, where one student's weakness is improved by another student’s expertise sequentially.
Different algorithms that use Ensemble Learning techniques —
1) Gradient Boosting
Let’s imagine that we want to create a strong Football team. We hired a player and now we have one player in our team. We evaluate the “team's performance”. After evaluation, we identify the weaknesses or areas where the team didn’t perform well.
Then, we hired a second football player and evaluated the team’s performance. We see that the second player improves the shortcomings of the first player, but there are still some areas of weakness visible for the overall team.
In every iteration, we hire a player, evaluate the overall team’s performance, and identify the team’s weaknesses. The process continues until we get a strong Football team.
Here,
- The players act as the base model or weak learners.
- Evaluating the performance and identifying the weakness is similar to calculating the prediction errors or residuals.
- Adding new players to the team refers to adding new weak learners to the entire Boosting model to improve the overall model’s performance.
It is called Gradient Boosting because it uses the Gradient Descent Optimization technique to calculate the prediction errors and improve the model’s performance. We are going to talk about the Optimization techniques in detail in the future parts.
2) AdaBoost (Adaptive Boosting)

{kind=link}
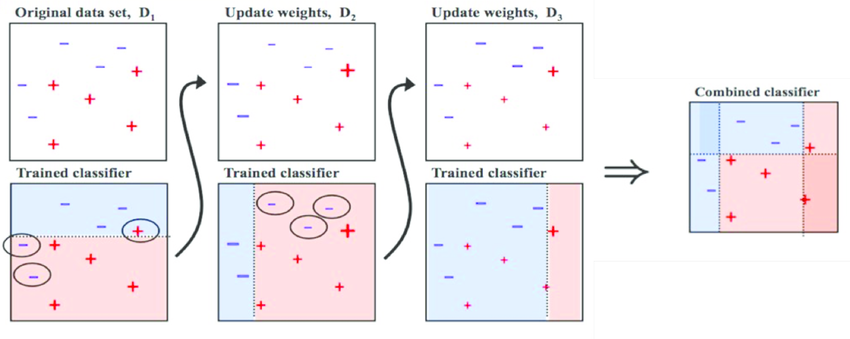
Let’s take the example of the study group consisting of nursery kids. Every kid is good at identifying something — birds, animals, insects, fish from a picture book.
Initially, the first kid tries to identify the pictures in a picture book. The second kid tries to identify the same pictures. This time, the kid also tries to identify the misclassified pictures and correct the first kid’s mistake.
Similarly, in every round, the kids try identifying the pictures from the picture book and correct the misclassified pictures. In the end, the overall performance of the study group is improved.
Here, the students represent the base models or weak learners. Each weak learner identifies the previous weak learner's misclassified predictions, gives higher weight to those predictions, and then tries correcting the predictions at the end. As a result, the entire Boosting model’s performance and accuracy is improved.
3) XGBoost (eXtreme Gradient Boosting)

Let’s understand this using a competitive examination example. We might be aware of competitive examinations like JEE, GRE, CAT, SAT, etc. The scores from these exams act as a deciding factor in whether a student is qualified for higher studies at a specific university.
These examinations have a similar format which is questions with multiple choices. One of the choices is the correct answer. Like other exams, if the answer is correct, marks are added to the overall score. However, some examinations have a negative marking system to penalize incorrect answers.
Similarly, each weak learner in XGBoost not only corrects the errors from the previous weak learner but also uses Regularization techniques to penalize the overfitting of the model.
4) LightGBM (Light Gradient Boosting Machine)

{kind=link}
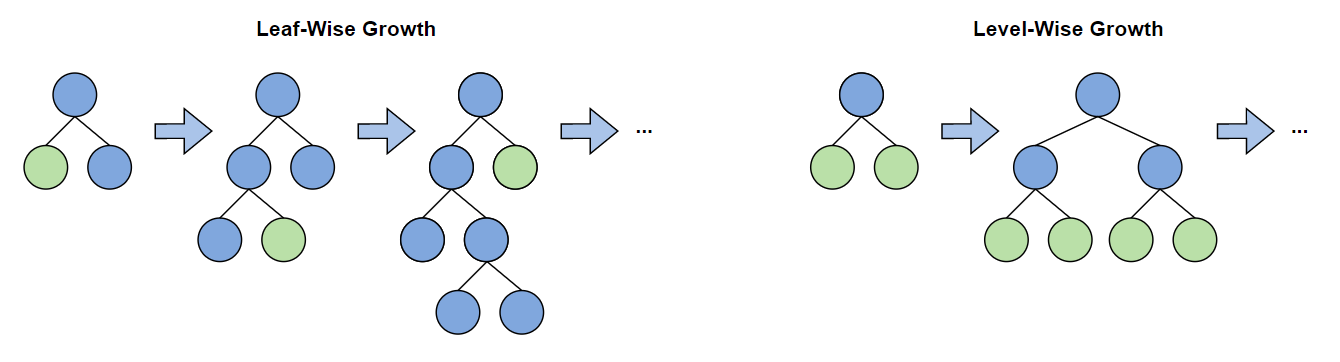
Here, the Decision Trees act as the weak learners. It is similar to Gradient Boosting. It uses the leaf-wise strategy to create the Decision Trees, which makes it faster than other Gradient Boosting algorithms.
In the traditional level-wise approach, we used to select the feature node for the best split and grow the tree horizontally. In the leaf-wise approach, after selecting the root node, we select the leaf node that helps in the reduction of prediction error or loss of the model. Then, we determine the best split by selecting the child or feature nodes and growing the tree vertically.
5) CatBoost
It is a Gradient Boosting algorithm that is used mostly for classification problems but can be used for regression as well. In Machine Learning, we cannot use any categorical feature or target columns in the text format for training the model. We need to first encode them in some numerical format, such as Yes as 1, and No as 0. In CatBoost, this pre-processing of the categorical columns and missing values is handled by the model itself, rather than handling it manually.

The weak learners are symmetric Decision Trees. The symmetric trees are also called the mirror trees because the left subtree is the mirror reflection of the right subtree. As we can see in the above diagram, these trees are not large and complex leading to overfitting. They are rather simple to interpret and understand, making the prediction speed faster for the entire CatBoost model. Like XGBoost, CatBoost uses the Regularization techniques to penalize overfitting.
6) Stochastic Gradient Boosting
It is an extension of the Gradient Boosting algorithm. Here, the weak learners are created by randomly selecting subsets of features and samples from the entire dataset. This makes the weak learners more diverse and the overall model is less prone to overfitting.
Conclusion:
- In Gradient Boosting, the weak learner calculates the prediction errors of the previous weak learners using Gradient Descent.
- In AdaBoost, the weak learner identifies misclassified predictions of the previous weak learners and corrects them.
- In XGBoost, the weak learner calculates the prediction errors of the previous weak learners and penalizes overfitting using Regularization techniques.
- LightGBM uses Decision Trees as weak learners. It creates the weak learner using a leaf-wise strategy making it a faster Gradient Boosting algorithm.
- CatBoost uses symmetric Decision Trees as weak learners making them simpler and less prone to overfitting.
- Stochastic Boosting uses a random subset of features and samples to create weak learners, making the weak learners more diverse.
Stay tuned, in the next part we will understand, What is KNN and how it works. Please share your views, thoughts, and comments below. Feel free to ask any queries.
References: