Machine Learning 101
In the previous part — Part 6: Decision Tree, we learned about the Decision Tree algorithm, its working, major problems, and techniques to overcome the problems using examples.
Let’s start by understanding Ensemble Learning —
Ensemble Learning is a technique that aggregates the conclusions or output from various base models such as Decision Trees, KNN, SVM, etc and gives a final output.
Ensemble Learning reduces bias and overfitting that may occur due to dependence on the output of one model. It improves the model’s performance making it fair and accurate.

In the above diagram, a weak learner represents any base model.
So, What is Bias and Overfitting in Machine Learning?
For example, a Machine Learning model is trained to predict employee performance based on historical employee data. If the training data consists of one gender or ethnicity, the model may develop a bias toward that specific group. Therefore, it might inaccurately predict employee performance, leading to discriminatory outputs.
Here, we can see that the bias comes from an imbalance in the training data, highlighting the importance of diverse and representative datasets to ensure fair and accurate Machine Learning models.
Note: When the dataset has more data for one category and fewer data for the other categories, it is considered an Imbalance dataset.
Overfitting occurs when there is less diverse training data. So, if the model learns too well for one specific group, it gives poor performance for other groups.
There are different Ensemble Learning techniques —
1) Stacking —

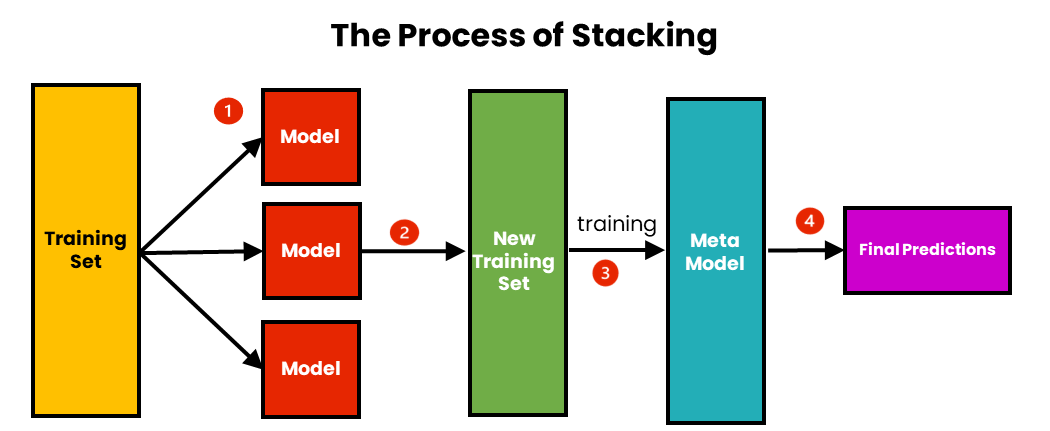{kind=link}
Suppose, you want to plan a vacation itinerary. You have 3 friends who are experts in planning vacations — Ross who is an expert in beach destinations, Rachel who is an expert in cultural destinations and Joey who is an expert in adventurous destinations.
Instead of relying on one person’s recommendation, you take recommendations from all your friends. We give weights to each of their recommendations as per their expertise. Combine these recommendations, and create a comprehensive vacation itinerary that includes the best of each recommendation.
Here, your friends represent the base models. Recommendations from your friends are predictions from the base models. The decision-making process is done by the meta-model, which is a secondary machine-learning model that learns how to make decisions. The final vacation itinerary is the final output.
2) Blending —

Let’s take an example of a popular show — Masterchef. In Masterchef, several home cooks and professionals compete to win the Masterchef title.
There are usually 3 judges in the show, each expert in a cuisine or type of food. Say, Thomas is a European cuisine expert, Jacky is an Asian cuisine expert and Peter is a desert expert. It’s the finale day, we have the top 3 contestants competing for the title. The contestants are asked to make one European, one Asian, and one desert dish for the finale.
For European cuisine, more weight is given to Thomas's judgment. For Asian cuisine, more weight is given to Jacky’s judgment. For dessert, more weight is given to Peter’s judgment. In the end, the decision from each judge is combined and, the home cook or professional that excels in the most number of dishes is declared a winner.
Here, judges represent the base models, their judgments are the predictions from the base models and the decision is combined using a function to give a final output.
The difference between Stacking and Blending is that, Stacking uses Cross Validation to create the training dataset for the meta-model.
3) Bagging —
In the above two techniques, the base models are trained mostly with the same datasets. So, the decrease in diversity might result in giving the same output. Aggregating such decisions is of no use.

Bagging or Bootstrap Aggregating is a technique that overcomes such problems. For example, several movie enthusiasts formed a committee for movie recommendations. Each committee member can be considered a movie critic who has diverse tastes, opinions, and biases in movies. Every member is given a different subset of movies to watch and give recommendations. The subsets are created using a method called Bootstraping, where the random samples with replacement are created from the entire dataset.
In the end, every individual committee member gives a recommendation based on their experiences and preferences. The recommendations are then combined to give final movie recommendations.
Combining the decisions in Ensemble Learning is done either by majority voting by the base models or by averaging the prediction values (eg. movie ratings).


Random Forest —
Random Forest is a Supervised Learning algorithm that follows the Bagging technique. It creates a forest of Decision Trees. Each Decision Tree acts as a base model, trained with randomly sampled subsets in parallel, and is created using a random set of features.
Using the above Bagging example, for each movie critic a Decision Tree is created where the recommendations given by the movie critics are the predictions from the Decision Trees. These predictions are then combined to give a final decision.
There is another algorithm that uses the Bagging technique called Bagging meta-estimator, where instead of using a random set of features it includes all the features while creating the base models.
Stay tuned, in the next part we will understand, What is Boosting, different Boosting algorithms, and how they work. Please share your views, thoughts, and comments below. Feel free to ask any queries.
References:
- A Comprehensive Guide to Ensemble Learning (with Python codes)
- A Gentle Introduction to Ensemble Learning Algorithms
- Understand Random Forest Algorithms With Examples (Updated 2024)