PinnedDeepa VasanthkumarUnlocking the World of Data Engineering — Guide to Acing InterviewsIn today’s data-driven world, the demand for skilled data engineers is soaring. Companies are on the lookout for professionals who can…Jun 8Jun 8
Deepa VasanthkumarUnderstanding Coalesce function in SQL and SparkThe COALESCE function is a powerful and commonly used feature in both SQL and Apache Spark. It is instrumental in handling NULL values and…2d ago2d ago
Deepa VasanthkumarSpark Concepts and Questions1. How many types of join strategies are there in Spark?Jul 12Jul 12
Deepa VasanthkumarExploring Architectural Patterns in Data Engineering ProjectsData engineering is a critical component of any data-driven organization, enabling the collection, transformation, and management of data…Jul 1Jul 1
Deepa VasanthkumarCode Optimization in PySpark Leveraging Best PracticesApache Spark is a powerful framework for distributed data processing, but to fully leverage its capabilities, it’s essential to write…Jun 261Jun 261
Deepa VasanthkumarSpark Accumulators and Broadcast variablesIn Apache Spark, both accumulators and broadcast variables are used to share data among nodes in a distributed processing environment, but…Jun 12Jun 12
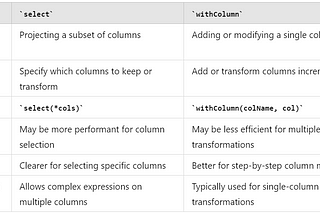
Deepa VasanthkumarSpark dataframes select vs withcolumn comparisonIn Apache Spark, both `select` and `withColumn` are methods used to manipulate DataFrames, but they serve different purposes and have…Jun 10Jun 10
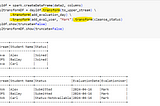
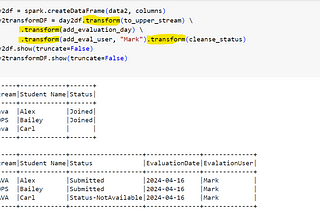
Deepa Vasanthkumarpyspark dataframe transform mThe `transform()` method in PySpark DataFrame API applies a user-defined function (UDF) to each row of the DataFrame. It takes a function…Apr 161Apr 161