Clustering and PM2: Multitasking in NodeJS
Deep Dive in Cluster and PM2

This article is the sixth article of my Advanced NodeJS for Senior Engineers Series. In this article, I’m going to explain what, why and how child processes works in detail, and how to get the best performance using child processes. Official documentation present at NodeJS Cluster.
You can find the other articles of the Advanced NodeJS for Senior Engineers series below:
Post Series Roadmap
* The V8 JavaScript Engine
* Async IO in NodeJS
* Event Loop in NodeJS
* Worker Threads : Multitasking in NodeJS
* Child Processes: Multitasking in NodeJS
* Clustering & PM2: Multitasking in NodeJS (This Article)
* Debunking Common NodeJS MisconceptionsTable of Content
* What & Why is Clustering was needed?
* What goes on under the hood?
* What happens at very low level?
* How does it effectively distribute the workload among these processes?
* What’s all there is to work with?
* Scaling with the cluster module
* Recovering from untimely worker termination
* So which one is better worker threads or clusters?
* PM2 cluster mode with Node.jsWhat & Why is Clustering was needed?
We are well aware that NodeJS is not specifically built for CPU-intensive tasks because of its single-threaded architecture. However, this doesn’t mean that we can’t make use of it for such tasks. In fact, NodeJS offers a couple of options to handle CPU-intensive work, like utilizing worker threads to take advantage of a multi-threaded architecture and using child processes for multi-processing. While worker threads are great for CPU-intensive tasks, they may not be the best choice when it comes to process isolation. On the other hand, creating child processes is an option worth considering, although it doesn’t provide default load balancing across multiple processes. But fear not, because here comes the hero: Clustering!

Clustering comes to the rescue by providing a solution for load balancing within multiple child-processes. Clusters of Node.js processes can be used to run multiple instances of Node.js that can distribute workloads among their application threads.
The cluster module allows easy creation of child processes that all share server ports.
What goes on under the hood?
Well its really simple, the worker processes are spawned using the child_process.fork() method, so that they can communicate with the parent via IPC and pass server handles back and forth.
In any operating system, a process can utilize a port to establish communication with other systems. This implies that the assigned port can only be utilized by that specific process. Now, you might be wondering how all these processes can share the same port. Well, let me explain. The primary process acts as a listener, constantly monitoring incoming requests and delegating them to worker or forked processes.
Workers in a program are independent processes, which means they can be terminated or restarted without any impact on other workers. As long as there are active workers, the server will keep accepting connections. However, if all workers are inactive, existing connections will be terminated and new connections will be denied. It’s important to note that Node.js doesn’t handle the management of workers automatically. Instead, it’s the application’s duty to handle the worker pool according to its specific requirements.
What happens at very low level?
If you happen to be a system programmer, this might ring a bell. The behaviour of fork() is something that C programmers are quite familiar with. Essentially, when the fork() system call is invoked, the current process is duplicated. The child processes inherit open files, network connections, and memory data structures from the parent process. To ensure efficiency, a technique called copy on write is employed. This means that the same memory locations are shared until a write operation occurs, at which point each forked process gets its own copy. Once the processes are forked, they become isolated from each other.
How does it effectively distribute the workload among these processes?
There are actually two methods to achieve this.
The first approach, which is the default on all platforms except Windows, is known as the round-robin approach. In this method, the primary process listens on a port, accepts new connections, and evenly distributes them among the workers in a round-robin fashion. It also incorporates intelligent mechanisms to prevent overloading any particular worker process.
The second approach involves the primary process creating the listen socket and then passing it on to interested workers. These workers can then directly accept incoming connections. Essentially, the master process takes charge of creating the listen socket and passing it to the workers, who handle the incoming connections directly.
Doesn’t the second approach sound better in theory? However, reality can be far from the truth. You see, the main process simply forks the worker threads, leaving it up to the operating system to distribute and hand off these network requests to the processes. The operating system is not designed for distributing network load; its main purpose is to schedule the execution of processes. As a result, the majority of the load ends up being handled by the same fraction of processes. This behaviour may make sense for the operating system scheduler, as it aims to minimize context switches between different processes. However, it doesn’t make sense when it comes to balancing the load for network requests. That’s why the Round Robin approach was introduced.
The first approach is enabled by default on all platforms except Windows. It can be globally modified by setting the variable cluster.schedulingPolicy, using the constants cluster.SCHED_RR (round robin) or cluster.SCHED_NONE(handled by the operating system).
So, in summary, while each process has its own assigned port, the primary process efficiently manages the sharing of this port among multiple workers, ensuring smooth communication and load balancing.
What’s all there is to work with?
Usually the pattern followed in many program is as follows:
if(cluster.isPrimary) {
// fork()
} else {
//do work
}It’s interesting to notice that the usage of the cluster module is based on a recurring pattern, which makes it very easy to run multiple instances of an application.
Lets take a simple example, which creates a master process that retrieves the number of CPUs and forks a worker process for each CPU, and each child process prints a message in console and exit.
in index.js
const cluster = require('node:cluster');
const http = require('node:http');
const numCPUs = require('node:os').availableParallelism();
const process = require('node:process');
if (cluster.isPrimary) {
console.log(`Primary ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
// In this case it is an HTTP server
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}$ node index.js
Primary 3596 is running
Worker 4324 started
Worker 4520 started
Worker 6056 started
Worker 5644 startedYe should notice that each request will return a message with a different PID, which means that these requests have been handled by different workers, confirming that the load is being distributed among them.
If you are following my previous articles this is just like worker threads. When we run the program as main process is the first one to get run the isPrimary property is true, so in if block we we create sub-processes with cluster.fork as same number as that of the cpus. Subsequently these sub-processes runs the same files but the isPrimary will be false, this gives us separation to write the logic for the sub-processes.
isPrimary , isWorker
There are flags such as isPrimary , isWorker that can help us identify what kinda process the current process is.
cluster.schedulingPolicy
Along with that cluster.schedulingPolicy can let us set what kind of scheduling policy the current process should have. The scheduling policy, either cluster.SCHED_RR for round-robin or cluster.SCHED_NONE to leave it to the operating system.
disconnect, error, exit, listening, message, online events
The cluster module is event-based, so the master can listen for events like disconnect, error, exit, listening, message, online , events we can attach handlers on with workers processes. These events are present on both cluster and the worker processes that we create via cluster.
Scaling with the cluster module
If we take the previous example, all the worker processes are listening to the same port. The cluster module offers a convenient method for executing multiple worker processes that can collectively access file handles and sockets. This allows you to encapsulate a Node application within a master process that manages the worker processes. In scenarios where worker processes need to access user sessions stored in a database, there is no need to establish communication between them. Since all workers have access to the same database connection, they can seamlessly interact with user sessions without any additional setup.
Recovering from untimely worker termination
Starting multiple instances of the same application creates a redundant system, ensuring that even if one instance goes down for any reason, we still have other instances readily available to handle incoming requests. If in any case any of the worker processes crashes it wont take the server down with it. Rest of the workers as well as the main process will be as is.
If in any case if a worker process exits we should be able create a new one and exit comes in handy here as below
cluster.on('exit', (worker, code, signal) => {
console.log('worker %d died (%s). restarting...',
worker.process.pid, signal || code);
cluster.fork();
}); Have you wondered what occurs when the master process itself ceases to exist? Despite the fact that the master process is designed to be simple and prevent such scenarios, there is still a possibility of a crash. To ensure minimal downtime, it is advisable to oversee your clustered applications using a process manager such as the
forevermodule orUpstart.
So which one is better worker threads or clusters?
Each worker thread in Node.js has its own main loop, such as libuv. Similarly, each cloned Node.js process in clustering also has its own main loop.
Clustering is a technique used to distribute incoming requests to multiple copies of a Node.js server, allowing for load balancing.
Worker threads, on the other hand, allow a single Node.js process to delegate long-running functions to separate threads, preventing them from blocking the main loop.
Determining which approach is better depends on the specific problem you are trying to solve. Worker threads are suitable for handling long-running functions, while clustering enables a server to handle more requests by processing them in parallel. If necessary, you can utilize both methods by assigning a worker thread to each Node.js cluster process for long-running functions.

PM2 cluster mode with Node.js
Despite the presence of a cluster module, we are still responsible for managing various tasks like auto-restart and load balancing. However, PM2 eliminates the need for us to be concerned about these specific details.
PM2 has several important features:
1. Automatic Restart: If a Node.js application crashes or encounters an error, PM2 will automatically restart it.
2. Process Monitoring: PM2 keeps track of application health by storing logs, monitoring resource usage, and tracking the status of Node.js processes.
3. Load Balancing: PM2 simplifies load balancing with its built-in module.
4. Zero-Downtime Deployment: PM2 can reload your application, ensuring zero downtime during deployments.
5. Auto-start: PM2 saves the status of running processes and can automatically start them upon system reboot.
6. Multiple Application Management: With PM2, you can run different Node.js processes and optimize your server resources.
PM2 is not installed by default so we have to install it separatelynpm install pm2 -g
If we take the previous example, and shrunk it to non cluster way it would look somewhat like this,
const http = require('http');
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);Now we just have to run sudo pm2 start index.js -i 4Here, index.js is your application name, and -i represents the number of workers. Four workers are created using PM2, utilizing all four CPU cores.
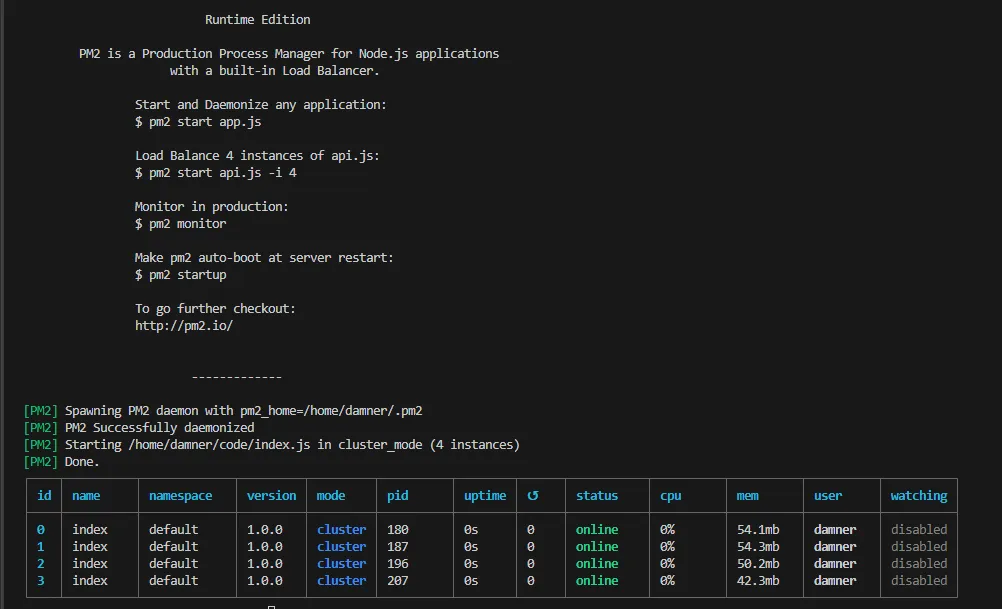
You can use the “max” option with PM2, which automatically detects the number of available CPUs and runs the maximum possible number of processes on the system.sudo pm2 start index.js -i max
OR
sudo pm2 start index.js -i 0
Also if you need to add the workers to your existing running cluster following can be used sudo pm2 scale index.js +1
Before you go!
- Stay tuned for more insights! Follow and subscribe.
- Did you see what happens when you click and hold the clap 👏 button?
