Gregory ZExplaining the Mixture-of-Experts (MoE) Architecture in Simple TermsDemystifying Mixture of Experts (MoE) on the Large Language Models: Simplifying the Complex World of MoE Models for Everyone.Jan 9Jan 9
Gregory ZDPO Explained: Quick and EasyDPO simplifies and accelerates the process of fine-tuning language models, much like how learning to cook directly from an expert chef.Jan 21Jan 21
Gregory ZThe Impact of Quantization on Large Language Models: Decline in Benchmark ScoresLet’s calculate the approximate performance drop for quantized large language models based on well-established benchmarks.Dec 29, 20231Dec 29, 20231
Gregory ZHow to Quickly Find the Best Local Model that Suits Your NeedsAn efficient method for selecting optimal local LLMs for specific tasks, presenting a superior alternative to traditional HF Leaderboard.Dec 3, 2023Dec 3, 2023
Gregory ZExperience Mind-Blowing In-Context Text Processing on MacOS Using Automator and ChatGPTNow you could utilize ChatGPT to process text in any MacOS application with a single keystroke. And it is all set in 5 min only!Nov 26, 20231Nov 26, 20231
Gregory ZRun Mistral 7B Model on MacBook M1 Pro with 16GB RAM using llama.cppOct 7, 20232Oct 7, 20232
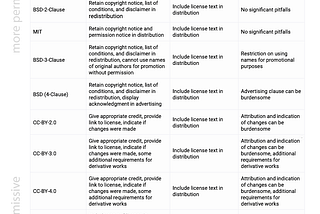
Gregory ZUnderstanding Permissive Licenses for Large Language Models (LLMs)Unravel the complex world of Large Language Models (LLMs) licensing. Explore how permissive licenses can impact your AI innovation journey.Jul 11, 2023Jul 11, 2023
Gregory ZHow to Choose the Ideal Large Language Model for Local InferenceNavigating the maze of Large Language Models (LLMs) for local inference on personal computing hardware or private servers can be a…Jul 6, 2023Jul 6, 2023