How Object Detection Evolved (Part 4)
From Region Proposals and Haar Cascades to Zero-Shot Techniques
Object detection algorithms have advanced from early computer vision to deep learning, utilizing various methods in modern systems for accurate detection.
This blog post serves as a subsequent installment in my ongoing series titled “The Evolution of Object Detection: From Region Proposals and Haar Cascades to Zero-Shot Techniques.”
For a comprehensive understanding of the subject, I highly recommend exploring the preceding and next sections of this story, which can be accessed through the following links:
Without further ado, let us resume our expedition through the realm of object detection.
(Zero | One | Few) — Shot Object Detection
In the development of algorithms for object detection, we are slowly moving toward the topic of Few, One, Zero—Shot Object Detection. In this section, we will focus less on technical details and more on a higher level, providing a simple description of the idea of how zero-shot object detection can be performed.
Multimodality

The key concept in this context is multimodality, which means that a neural network can understand several types of data simultaneously. For example, it can be a combination of image and text, image and sound, text and sound, or even image, text, and sound at the same time.
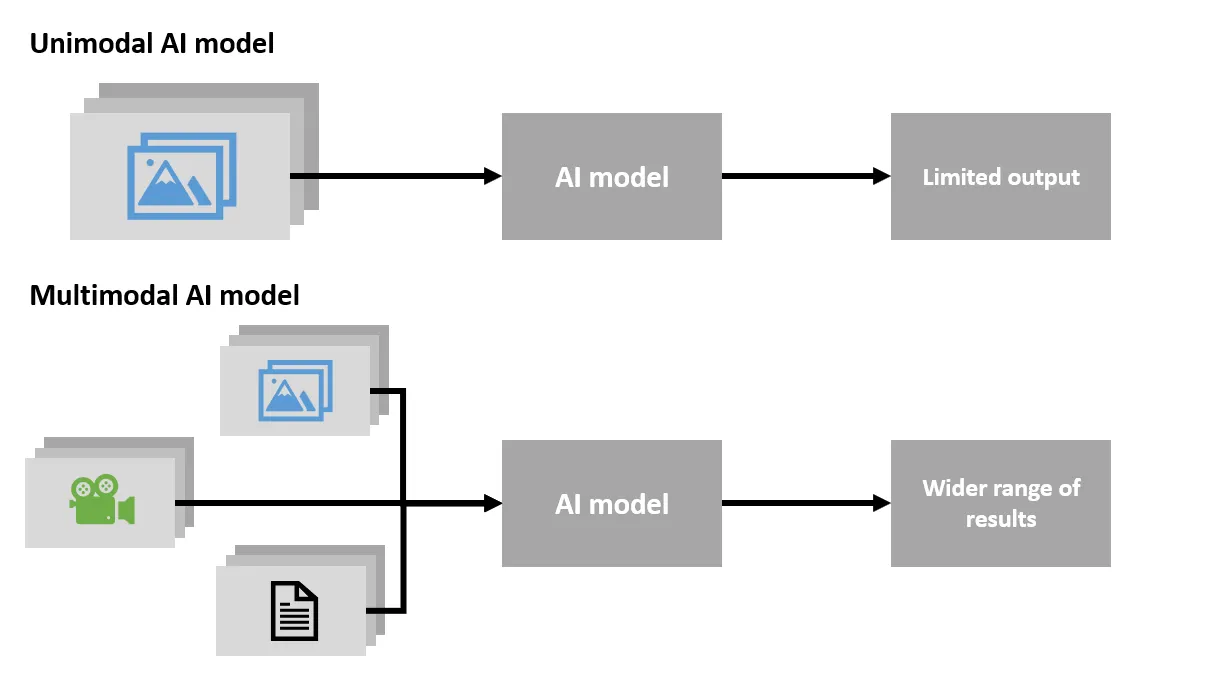
In this approach, we have several input signals, each of which is processed by a corresponding module. In our case, this includes a separate module for text processing, a separate module for image processing, and a separate module for audio processing. These modules form one single neural network that works from start to finish, which is called end-to-end architecture.
Next, fusion modules are used. They may have different names, but they perform the same function — they combine image, text, and audio features and perform certain operations on them. For example, perhaps they look for the most similar image feature vector to a text feature vector. This is similar to the principle of CLIP architecture, which we’ll talk about later.
CLIP (2021)
CLIP adds an image-text connection to understand the content of the image.

CLIP is a revolutionary development. The main idea behind CLIP is that it creates a connection between images and texts to better understand the context of the image. CLIP uses two models — TextEncoder and ImageEncoder. Each of these models converts data into a vector format.
CLIP is trained on a dataset consisting of text-image pairs, with each pair containing a text description and a corresponding image. During training, the model tries to find the TextEncoder and ImageEncoder parameters so that the vectors obtained for the text and image are similar to each other. The goal is to have the vectors of other text descriptions be different from the target image vector.
When using CLIP for Zero-Shot Object Detection, we can feed an image and a list of words or phrases related to the objects we want to find in the image. For example, if we have an image of a dog, we can use TextEncoder to create a vector with the text “A photo of a dog”. Then we compare this vector with the vectors obtained for each text in the list of words or phrases. The text with the smallest distance to the image vector indicates the object corresponding to the image.
Thus, we can use CLIP to classify objects in images even without separately training the model on a specific dataset with objects. This approach opens up a wide range of possibilities for applying CLIP in the field of Object Detection, where we can utilize the relationships between texts and images to find objects in images.
OWL-ViT (2022)
OWL-ViT adds image-level patches to understand the location of the objects.

In 2022, a new multimodal architecture, OWL-ViT, was introduced for object detection. This network, which is available on the Hugging Face platform, has gained considerable interest in the research and practice community. Let me tell you more about it.
The basic idea is to create embeddings of an image and text, and then compare these embeddings. The image is processed through a Vision Transformer, which generates a set of embeddings. Then, the Vision Transformer applies self-attention and feed-forward networks to these embeddings. Although some of the steps may seem confusing, in practice they help to improve the quality of the model.
Finally, during the training phase, a contrastive loss function is used to encourage corresponding image-text pairs to have similar embeddings and non-corresponding pairs to have distinct embeddings. The model predicts a bounding box and the probability that a certain text embedding applies to a particular object.
It should be noted that the accuracy of object detection may be limited. The authors of the original model used a process of fine-tuning the pre-trained model with object detection datasets using a bipartite matching loss. This process assists in improving the quality of the detected bounding boxes. More information about this process is shown in the diagrams below.

Now let’s look at an additional feature of this multimodal model. In addition to text, you can use an image as a template. For example, if you have a photo of a butterfly, you can use it as a search query and find similar images. The model is able to analyze both text and images based on common properties.

GLIP (2022)
GLIP adds word-level understanding to find the objects by the semantics of the prompt.

GLIP (2022) goes further by providing insight into images to distinguish their semantics. Let’s illustrate this with an example. Suppose we have a sentence about a woman holding a hair dryer and wearing glasses. At the same time, we see an image showing this woman with a hairdryer and glasses. GLIP reformulates object detection as phrase grounding. By accepting both an image and a text prompt as inputs, it can identify entities such as a person, a hairdryer, and others.

This technology offers a new approach to finding objects in an image based on their semantic correspondence with a text prompt. Now, we are not just identifying objects, but also associating parts of the text with components of the image.
Even if you only provide the name of the object, such as “Stingray”, GLIP will be able to find it, but perhaps with low accuracy. However, if you add a description, such as “flat fish”, it will provide additional context and understanding of what you are looking for. It is important to note that “Prompt Engineering” is of great importance when using ChatGPT and modern Zero-Shot Object Detection methods.

Segment Anything (2023)
Segment Anything (SAM) adds masks to see the pixel-level location of the objects.
This algorithm, introduced in 2023, allows not only to detect objects in images but also to segment them by applying masks at the pixel level.

One of the main features of Segment Anything is its usage of image and prompt encoders to create an overall image embedding, which can be used to segment images based on prompts. These prompts can be spatial, textual, or a combination of both. For instance, you could input “person” as a text prompt, and the algorithm would strive to segment all objects in the image related to a person.
This not only allows you to segment different areas in images but also to understand the layout and content of the scene. Using the segmentation masks produced by the algorithm, one could potentially perform tasks such as counting the number of instances of an object, given the appropriate post-processing steps.

Good Visual Tokenizers (2023)
Good Visual Tokenizers (GVT) is a new Multimodal Large Language Model (MLLM) that involves a visual tokenizer, which has been optimized through proper pre-training methods. This tokenizer aids in understanding both the semantic and fine-grained aspects of visual data.
GVT adds usage of the Large Language Model to investigate the image with the text.

GVT introduces an optimized visual tokenizer within a Large Language Model, enabling a more comprehensive investigation of images along with the associated text. While the application of these algorithms to specific domains such as medical imagery might require additional research, GVT has already demonstrated superior performance on tasks involving visual question answering, image captioning, and fine-grained visual understanding tasks such as object counting and multi-class identification.

Integrating text and images into one model allows you to expand your data understanding and processing capabilities. By using algorithms like the ones above, significant advances can be made in solving a variety of tasks that previously required complex algorithms and large amounts of data.
To sum up Zero-Shot Object Detection:
- CLIP adds an image-text connection to understand the content of the image.
- OWL-ViT adds image-level patches to understand the location of the objects.
- GLIP adds word-level understanding to find the objects by the semantics of the prompt.
- SAM adds masks to see the pixel-level location of the objects.
- GVT adds usage of the Large Language Model to investigate the image with the text.
Conclusion
In conclusion, the evolution of object detection algorithms has been a remarkable journey, from the early days of computer vision to the current state-of-the-art deep learning techniques. We’ve transitioned from traditional methods like Viola-Jones Detectors and HOG Detectors to more advanced approaches such as RCNN, YOLO, SSD, and CenterNet, which introduced end-to-end architectures for improved adaptability. However, the most groundbreaking leap came with Zero-Shot object detection methods like OWL-ViT, GLIP, Segment Anything, and GVT. These innovative techniques enable us to detect objects in images without the need for extensive neural network training, opening up a new era of possibilities in the field of object detection.
Thank you for taking the time to read this article. If you found it informative and engaging, feel free to connect with me through my social media channels.
If you have any questions or feedback, please feel free to leave a comment below or contact me directly via any of my communication channels.
I look forward to sharing more insights and knowledge with you in the future!
