A Deep Dive into AI Art — Generative Art (Part 1)
As inferred from Prof. Philip Galanter’s paper from 2003, the term ‘Generative Art’ refers to the kind of art where the artist uses a system, like a set of natural language rules, a computer program, a machine, or other procedural invention, set into motion with some degree of autonomy contributing or resulting in a finished work of art. An autonomous system in the context of generative art is a system that is non-human and can independently determine features of an artwork that would otherwise require decisions made directly by the artist.
One of the first known examples of generative art is a musical game called Musikalisches Würfelspiel in which dice were rolled to randomly select already-composed fragments of music, which were strung together to form a finished piece. This game was played in Berlin in 1792 and has been attributed to the famous composer Wolfgang Amadeus Mozart.
Another example of generative art is the set of Italian Medieval town designs created by an architect named Celestino Soddu in 1987. He created a set of conditions where a random computer process could be set in motion to create a model of a town. The conditions were such that the final result would always be a town identifiable in the Italian Medieval style. Despite there being enough constraints on the models to keep them in this style, an essentially infinite number of models could be created.
As shown in the above example, the beauty of generative art is that the possibilities for creation are limitless. A process with certain conditions created by the user is set into motion and the element of chance creates the most intriguing piece of digital art.
During the 1960s, when generative art became quite popular, famous digital artist Harold Cohen became interested in work by computer scientists at the University of San Diego. Programmers created a system on punched cards, fed those cards into a machine which would then return results via a set of newly punched cards, or prints. He applied this technology to computer-controlled drawing machines, which he called “turtles”. Cohen programmed the “turtles” to follow a set of processes which would lead to a piece of art being formed on canvas. His system, AARON, is one of the longest running, continually maintained AI systems in history.

However, Cohen has further explained in his paper — The further exploits of AARON, Painter regarding the artistic legitimacy and functions of what his system is exactly doing, and whether it’s justified to call it ‘creative’.
Another prominent artist named Vera Molnar, during the same time as Cohen, had been experimenting with creating images using “machine imaginaire”, as she called it. She created a set of rules to paint a series of geometric images, allowing her to explore endless shapes and lines.
Deep Learning Models
In order to attain accuracy that surpasses that of humans, deep learning models learn to execute categorization tasks directly from images, text, or sound. Deep learning models are trained using an objective function, but how that function is constructed reveals a lot about the model’s intended use.
Deep neural networks, which are used to process data in complicated ways using extensive mathematical modelling, are far more complex than the simple neural networks utilized in the majority of machine learning techniques. Deep neural networks take advantage of the hidden layer component that is included in ANNs by stacking an increasing number of those layers in order to assess the importance of the input to the output and create new associations between various input combinations.

Image identification, speech recognition, natural language processing, and many more applications all heavily rely on deep learning models. Deep learning is also the foundation for the great majority of Machine Reading Comprehension (MRC) models now being used.
Machine learning’s branch of deep learning models differs from other branches for a variety of reasons:
- The majority of deep learning models are very sophisticated. Artificial neural networks (ANN), on which deep learning is based, have the property that their model size can be controlled. This means that even with a fixed input dimension, the number of model parameters can be controlled by varying the number of network layers, the number of connections, and the layer size. Deep learning makes it simple to expand model complexity as a result, enabling more effective utilization of enormous amounts of data. A higher amount of data can also boost the accuracy of deep learning models. Deep learning has been the most popular machine learning architecture for reading comprehension as the area of MRC continues to develop and new datasets are created.
- Feature learning is a strong quality of deep learning. In machine learning, a model’s performance is heavily influenced by representation learning — the process by which a model learns a good representation of the data. The extraction of task-specific characteristics is an established process for traditional machine learning models. Prior to the development of deep learning, feature extraction was frequently manual and called for subject-matter expertise. Deep learning, on the other hand, uses neural networks to automatically learn useful feature representations by performing a nonlinear transformation on the basic input features, such as word vectors and image pixels. To put it another way, deep learning successfully acquires salient features that are helpful to the target task without requiring the model designers to have specialized domain expertise, which considerably improves the efficiency of creating deep learning models for tasks from many applications.
- End-to-end learning is achieved by deep learning. In the past, many machine learning models suggested pipelines for multistep solutions. To simultaneously optimize the entire system to increase performance, however, is challenging because each phase can only be addressed independently. The efficiency is also considerably decreased if any step in the model is altered because it is likely that all subsequent phases will need to be modified as well. The featurization ability of neural networks end-to-end learning, which feeds in the raw data as input and outputs the needed result, can overcome this problem by optimizing all parameters in an organized fashion to increase accuracy. For instance, in MRC, the model inputs the text of the article and the question and outputs the text of the response. It is very simple to use and deploy, substantially simplifying the optimization process.
- Deep learning frequently makes advantage of enhanced hardware, particularly the Graphics Processing Unit (GPU). Because deep learning models are typically big, computational efficiency has become a key driver of deep learning advancement. The computation has been significantly expedited by the GPU’s better design. The floating-point computational capability, read/write speed, and parallelism of the GPU are all higher than those of the CPU. The exponential growth of computational power and device complexity over time is known as Moore’s law, and the development of GPUs over the past ten years has followed this trend. Deep learning-specific GPUs are still being developed by the GPU industry, which is comprised of companies like NVIDIA, Intel, and Google. This activity contributes to the advancement and use of the deep learning field as a whole.
- The emergence and prosperity of deep learning frameworks and community immensely help prompt the booming of deep learning. With the advent of frameworks, such as TensorFlow, , and , neural networks can be automatically optimized and the most commonly used network modules are predefined, making deep learning development much simpler. Meanwhile, deep learning communities quickly thrive. Every time a new research result appears, there will be developers who immediately implement, validate, and open-source models, making the popularization of new technologies to be at an unprecedented level. Academic paper repositories like and open-source code platforms like greatly facilitate the communication between researchers and developers, and considerably lower the threshold for participation in deep learning research.
- Deep learning has greatly benefited from the creation and growth of deep learning frameworks and communities. With the introduction of frameworks like TensorFlow, PyTorch and Keras, neural networks can now be automatically tuned, and the most popular network modules are predefined, greatly simplifying the building of deep learning systems. Deep learning groups, meanwhile, grow swiftly. Developers build, validate, and contribute to open-source models as soon as a new study finding is published, causing the adoption of new technology to reach previously unheard-of levels. A repository for academic papers called arXiv, and GitHub, a platform for open-source code, both significantly lower the entry barrier for participation in deep learning research and vastly facilitate communication between academicians and developers.
Convolutional Neural Networks
The breakthroughs in the field of computer vision with deep learning have been built and polished with focus on one particular algorithm — a Convolutional Neural Network.
A Convolutional Neural Network (ConvNet/CNN) is a Deep Learning system that can take in an input image, give importance (learnable weights and biases) to various characteristics and objects in the image, and distinguish between them. In comparison to other classification methods, a ConvNet requires substantially less pre-processing. ConvNets can learn these filters and attributes with enough training, unlike basic approaches where filters must be hand-engineered.
In their individual contributions from 1980 and 1989, Kunihiko Fukushima and Yann LeCun laid the groundwork for current research on convolutional neural networks.
The structure of a ConvNet was influenced by the way the Visual Cortex is organized and is similar to the connectivity pattern of neurons in the human brain. Only in this constrained area of the visual field, known as the Receptive Field, do individual neurons react to stimuli. The entire visual area is covered by a series of such fields that overlap.

{kind=link}
Backpropagation was successfully used by Yann LeCun to train neural networks to find and recognize patterns in a collection of handwritten zip codes. He and his colleagues achieved their research goals in the 1990s by using “LeNet-5”, which utilized the same concepts as earlier work for document recognition.
Utilizing concepts from linear algebra, notably matrix multiplication, convolutional neural networks offer a scalable method for completing picture classification and object recognition tasks. However, they can be computationally taxing, necessitating the use of graphics processing units (GPUs) when modelling them. The ConvNet’s job is to condense the images into a format that is simpler to analyze without sacrificing elements that are essential for obtaining an accurate forecast.
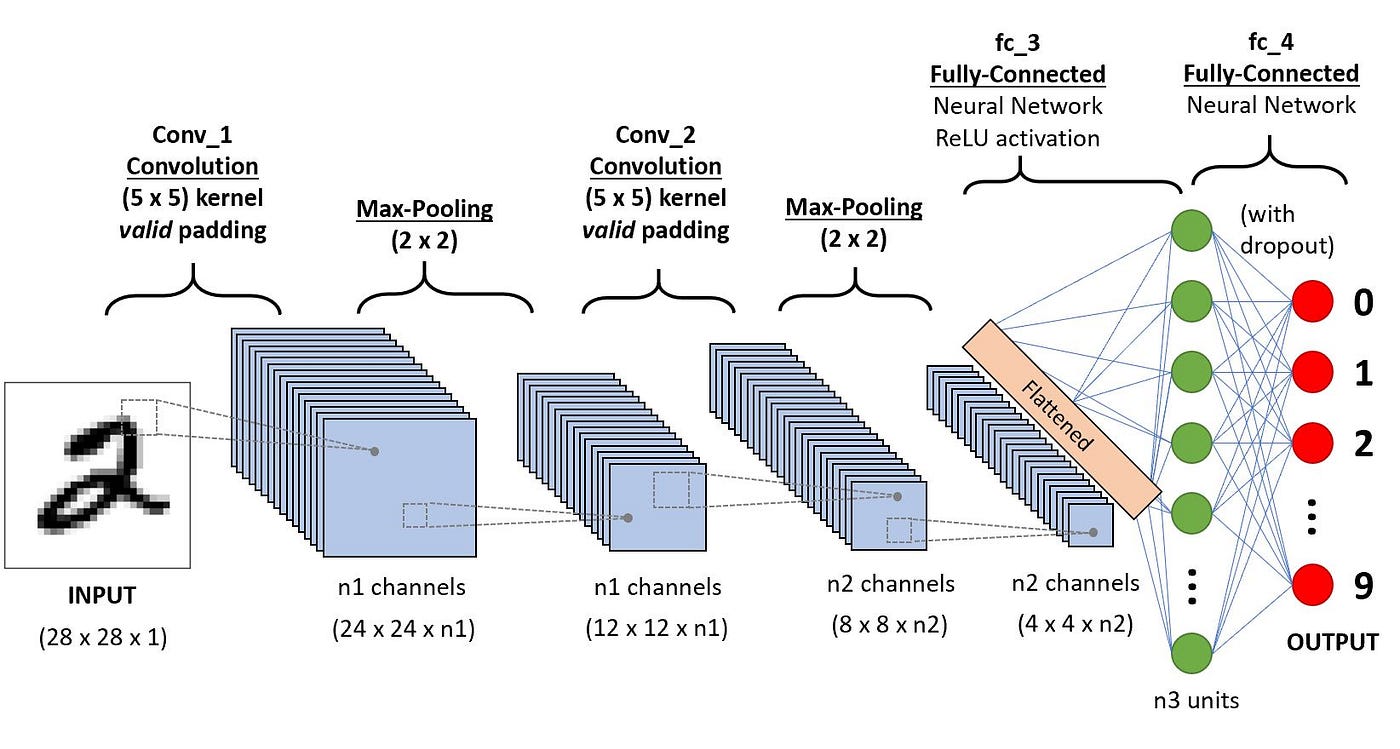
They have three main types of layers, which are:
- Convolutional layer — A convolutional network’s first layer is the convolutional layer. It is the central component of a CNN and the location of most computation. It needs input data, a filter, and a feature map, among other things. It is implied that the input will contain three dimensions — a height, a width, and a depth — which equate to RGB in an image if the input is a color image, which is composed of a matrix of pixels in three dimensions. Additionally, there is a feature detector, also referred to as a kernel or filter, which will move through the image’s receptive fields and determine whether the feature is there. This is what is called convolution.
- A two-dimensional (2-D) array of weights serving as the feature detector represents a portion of the image. The filter size, which also controls the size of the receptive field, is normally a 3x3 matrix, however it can vary in size. Following the application of the filter to a portion of the image, the dot product between the input pixels and the filter is determined. The output array is then fed with this dot product. Once the kernel has swept through the entire image, the filter shifts by a stride and repeats the operation. A feature map, activation map, or convolved feature is the ultimate result of the series of dot products from the input and the filter.

- It is not necessary for every output value in the feature map to correspond to every pixel value in the input image. Only the receptive field, where the filter is being used, needs to be connected. Convolutional (and pooling) layers are frequently referred to as “partially connected” layers, which can alternatively be described as local connectivity, because the output array does not have to map exactly to each input value.
- A technique known as parameter sharing, involves keeping the feature detector’s weights constant while it traverses over the image. Some parameters, like as weight values, change during training via the backpropagation and gradient descent processes. Prior to starting the neural network’s training, three hyperparameters that determine the output’s volume size must be established. These include:
- The depth of the output is influenced by the number of filters. Three distinct filters, for instance, would result in three different feature maps, giving a depth of three.
- The kernel’s stride is how many pixels or how far it travels across the input matrix. Despite the rarity of stride values of two or higher, a longer stride results in a lesser output.
- The process of symmetrically adding zeroes to the input matrix is known as zero-padding. It is a widely used modification that enables the input size to be changed to meet the needs. It’s typically utilized when the filters don’t work with the input image. This results in a larger or equally sized output by setting any elements that are not part of the input matrix to zero. There are three different kinds of padding:
Valid padding: This is sometimes referred to as no padding. In this situation, if dimensions do not line up, the final convolution is dropped.
Same padding: By using this padding, the output layer is guaranteed to be the same size as the input layer.
Full padding: This kind of padding enlarges the output by padding the input border with zeros.
- The first convolution layer may be followed by another. When this occurs, the CNN’s structure may become hierarchical because the later layers will be able to view the pixels in the earlier layers’ receptive fields. Example of whether an image includes bicycles or not can be taken into consideration. The bicycle can be thought of as a collection of parts. It has a frame, handlebars, wheels, pedals, and other parts. A feature hierarchy is created within the CNN by the bicycle’s component pieces, each of which represents a lower-level pattern in the neural network and the bicycle as a whole a higher-level pattern.

- The convolutional layer ultimately transforms the image into numerical data, enabling the neural network to understand and extract pertinent patterns.
- Pooling layer — also referred to as downsampling, the pooling layer does dimensionality reduction, which lowers the number of factors in the input. The pooling process sweeps a filter across the entire input, much like the convolutional layer does, however this filter doesn’t contain any weights. Instead, the kernel fills the output array with values from the receptive field using an aggregation function. There are two main types of pooling:
Max pooling: The filter chooses the input pixel with the highest value to send to the output array as it advances across the input. This method is applied more frequently than average pooling.
Average pooling: The average value inside the receptive field is determined as the filter advances over the input, and it is then sent to the output array. - The pooling layer loses a lot of information, but it also offers the CNN a number of advantages. It lessens complexity, increases effectiveness, and lowers the risk of overfitting.
- Fully-connected (FC) layer — The full-connected layer is exactly what its name implies. As was already established, with partially linked layers, the input image’s pixel values are not connected directly to the output layer. In contrast, every node in the output layer of the fully connected layer is directly connected to a node in the layer above it.
- This layer conducts the classification operation using the features that were extracted using the various filters and preceding layers. While convolutional and pooling layers frequently utilize ReLu functions to categorize inputs, FC layers typically use a softmax activation function to do so, resulting in a probability ranging from 0 to 1.
With the release of fresh datasets like MNIST and CIFAR-10 and contests like the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), a variety of variant CNN designs have arisen. Other architectures include:
Recurrent Neural Networks
An artificial neural network that employs sequential data or time series data is called a Recurrent Neural Network (RNN). These deep learning algorithms are included into well-known programs like Siri, Voice Search, and Google Translate. They are frequently employed for ordinal or temporal problems, including language translation, natural language processing (NLP), speech recognition, and image captioning. Recurrent neural networks (RNNs) use training data to learn, just like feed-forward and convolutional neural networks (CNNs) do. They stand out due to their “memory,” which allows them to affect the current input and output by using data from previous inputs. Recurrent neural networks’ outputs are dependent on the previous parts in the sequence, unlike typical deep neural networks, which presume that inputs and outputs are independent of one another. Unidirectional recurrent neural networks are unable to take into account future events in their forecasts, despite the fact that they would be useful in deciding the output of a particular sequence.
The way that RNNs and feed-forward neural networks channel information gives them their names. The only direction in which information can go in a feed-forward neural network is from the input layer to the output layer via the hidden layers. Without ever touching a node twice, the information travels straight through the network. Having no memory of the input they receive, feed-forward neural networks do poorly at making predictions about the future. A feed-forward network lacks any understanding of chronological order because it solely takes the current input into account. Simply said, it is just capable of recalling the training and nothing else from the past. Information is cycled around a loop in an RNN. It considers both the current input and the lessons learnt from the inputs it has already received while making decisions.

The fact that recurrent networks share parameters among all of their layers makes them stand out from other types of networks. In contrast to feed-forward networks, which use separate weights for each node, recurrent neural networks use a single weight parameter for all of the network’s layers. Nevertheless, to aid with reinforcement learning, these weights are still modified using processes of backpropagation and gradient descent.
In order to calculate the gradients, recurrent neural networks use the Backpropagation Through Time (BPTT) algorithm, which differs slightly from conventional backpropagation because it is designed for sequence data. BPTT works on the same principles as conventional backpropagation, in which the model learns by computing errors from its output layer to its input layer. The model’s parameters can be modified and properly fit thanks to these calculations. In contrast to the conventional method, BPTT adds errors at each time step. This is because feed-forward networks do not share parameters within layers, whereas BPTT does.

RNNs frequently experience the two issues of “exploding gradients” and “vanishing gradients” throughout this process. The gradient’s size, or the slope of the loss function along the error curve, is what categorizes these problems. The weight parameters are updated until they are no longer significant, or zero, when the gradient is too small. The algorithm stops learning when something happens. When the gradient is too great, exploding gradients happen, which makes the model unstable. In this scenario, the model weights will eventually become too enormous and be represented as NaN. Getting rid of some of the complexity in the RNN model by reducing the number of hidden layers in the neural network is one way to address these problems.
Different varieties of RNNs are employed for various use cases since the lengths of their inputs and outputs might differ. As depicted in the image, there are various kinds of RNNs:

Long Short-Term Memory
Recurrent neural networks (RNNs) can extend their memory by using Long short-term memory networks (LSTMs). As a result, they are well adapted to draw lessons from significant events with significant gaps in time. They were developed as a remedy for the disappearing gradient issue by Sepp Hochreiter and Juergen Schmidhuber. Long-term dependencies are a concern that they attempt to address in their study. To put it another way, the RNN model might not be able to predict the present state accurately if the previous state that is influencing the prediction is not recent.
In the neural network’s hidden layers, LSTMs have “cells” that have three gates: an input gate, an output gate, and a forget gate. These gates regulate the information flow required to predict the network’s output, deciding whether to allow fresh input (input gate), discard the information because it is unimportant (forget gate), or allow it to affect the output at the current timestep (output gate).

Generative Adversarial Networks
In order to model the distribution of training samples and characterize the phenomena in a particular dataset, a method of unsupervised machine learning known as Generative modelling is used. This approach increases the likelihood that predictions of all kinds of probability on a subject may be made from the modelled data. Generic modelling algorithms process massive amounts of training data in unsupervised machine learning and distil the data down to its digital core. These models often use neural networks and can learn to recognize the data’s unique natural characteristics. In order to represent data that is comparable to or identical to actual world data, neural networks use these simplified underlying understandings of real-world data.
Generative Adversarial Networks, or GANs, are a method of generative modelling and are a subset of generative models. Deep learning models like convolutional neural networks are utilized by GANs (CNN). In the 2015 publication titled “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”, Alec Radford established a standardized method known as Deep Convolutional Generative Adversarial Networks, or DCGAN, that produced more reliable models. It’s quite clever how generative models are trained using GANs because the problem is framed as a supervised machine learning problem with two sub-models: the generator model, which is trained to generate new examples, and the discriminator model, which tries to categorize examples as either real (from the domain) or fake (a generated one). Two models are combined for adversarial training in a zero-sum game until the discriminator model is tricked around half the time, indicating the generator model is producing credible examples.

Generative modelling offers a route to additional modelling training in difficult domains or areas with less data. In this use case, GANs have had a lot of success in fields like deep reinforcement learning.
The Generator Model
A fixed-length random vector is sent to the generator model, which then creates a sample within the domain. The vector is chosen at random from a Gaussian distribution and is used as the process’s seed. Following training, this multidimensional vector space’s points will match those in the issue domain, resulting in a compressed representation of the data distribution. Latent spaces, or vector spaces made up of latent variables, are what this particular vector space is known as. Latent variables, often known as hidden variables, are factors that are significant for a domain but cannot be observed directly. The observed raw data, such as the input data distribution, are compressed or presented in a high-level manner using a latent space. In the case of GANs, the generator model assigns meaning to points in a predetermined latent space, allowing fresh points selected from the latent space to be supplied to the generator model as input and utilized to generate brand-new, distinct output examples. The generator model is retained and used to create fresh samples after training.

The Discriminator Model
The discriminator model predicts a binary class label of real or fake (generated) based on an input example from the domain (either actual or fabricated). The training dataset contains the actual example. The generator model outputs the created examples. A normal classification model is used as the discriminator. The discriminator model is abandoned after training since the generator is the point of interest. The generator can occasionally be put to new uses since it has mastered the art of successfully extracting features from examples in the issue area. The same or similar input data can be used with some, or all of the feature extraction layers in transfer learning applications.

In this case, zero-sum implies that the discriminator is rewarded or no modification to the model parameters is required when it correctly distinguishes between real and false samples, however the generator is penalized with significant updates to the model parameters. As an alternative, if the generator manages to trick the discriminator, it is rewarded or the model parameters do not need to be changed, but the discriminator is penalized, and its model parameters are changed. At some point, the generator will always produce perfect copies of the input domain, rendering the discriminator unable to distinguish between the two and predicting “unsure” (e.g., 50% for real and fake) in every instance.
GANs and ConvNets
Convolutional Neural Networks, or CNNs, are frequently used by GANs as the generator and discriminator models when working with pictorial data. This is due to the fact that the technique was first described in the context of computer vision, where CNNs and image data were used, as well as the remarkable advancements made in recent years in the use of CNNs more generally to produce cutting-edge outcomes on a variety of computer vision tasks, including object detection and face recognition. When modelling image data, a compressed representation of the collection of images or photographs used to train the model is provided by the latent space, the generator’s input. Additionally, it implies that the generator creates fresh pictures or photos, producing a result that model creators or users can quickly view and evaluate. The focus of computer vision applications with CNNs and on the enormous improvements in capabilities of GANs as compared to other generative models has been driven by the ability to visually evaluate the quality of the generated output.
Conditional GANs
Using the GAN to conditionally generate an output is a significant development of the technology. When the input, a random vector drawn from the latent space, is given with (conditioned by) some extra input, the generative model can be trained to produce fresh examples from the input domain. In order to create images of handwritten numbers, the additional input may be a digit or a class value, such as male or female in the case of creating photos of individuals. Additionally, the discriminator is conditioned, which entails giving it both the additional input and an input image that can either be true or fake. When a conditional input of the classification label type is used, the discriminator will assume that the input belongs to that class, which will educate the generator to produce instances from that class in order to deceive the discriminator. A conditional GAN can produce examples from a domain of a specific kind in this manner. A step further is to condition the GAN models on a domain example, like an image. This enables the use of GANs for tasks like text-to-image translation or image-to-image translation. As a result, it is possible to use GANs for some of its more amazing applications, like style transfer, photo colorization, changing images from summer to winter or day to night, and so forth. The discriminator is given samples of real and created nighttime photos as well as (conditioned on) real daytime photos as input in the case of conditional GANs for image-to-image translation, such as converting day to night. In addition to actual daytime images, the generator is given a random vector from the latent space as input.

GANs and Images
One of the many significant developments in the application of deep learning techniques in fields like computer vision is a process known as data augmentation. Improved model performance is the outcome of data augmentation, which boosts model expertise and has a regularizing effect that lowers generalization error. It functions by generating brand-new, synthetic, but realistic instances from the input issue area on which the model is trained. For image data, the procedures are crude and involve cropping, flipping, zooming, and other straightforward transformations of the training dataset’s existing images. Generative modelling offers a way to increase modelling training in complex domains or areas with little data. In this use case, GANs have achieved great success in fields like deep reinforcement learning.
GANs are intriguing, significant, and demand additional investigation for a variety of reasons in the field of research. In his 2016 conference keynote and related technical report titled “NIPS 2016 Tutorial: Generative Adversarial Networks”, Ian Goodfellow lists a few of these. He emphasizes the success of GANs in modelling high-dimensional data, handling missing data, and the potential of GANs to produce multi-modal outputs or numerous plausible explanations.
Conditional GANs for tasks requiring the creation of fresh examples are where GANs are most effectively used. Goodfellow provides three key instances:
- Image Super-Resolution: Creating high-resolution copies of the input photos.
- Creating Art: The ability to create original, artistic drawings, paintings, and more.
- Image-to-Image Translation: The ability to convert images between different climes, including day and night, summer and winter, and more.
One of the major reasons that GANs are widely studied, developed, and used is because of their success. GANs have been able to generate photos so realistic that humans are unable to tell that they are of objects, scenes, and people that do not exist in real life.
The success of GANs is one of the main causes for the widespread study, creation, and application of these algorithms. Humans are unable to distinguish between people created by GANs and real people because they are so lifelike.

Diffusion Probabilistic Models
In the last few years, generative models called Diffusion Models have been increasingly popular. The world has seen what diffusion models are capable of, such as outperforming GANs on image synthesis, thanks to a select few landmark publications published in the 2020s. Practitioners most recently saw the usage of diffusion models in DALL-E 2, OpenAI’s image creation model that was released in the beginning of 2021. Due to their practical performance, the VAE, GAN, and Flow family of models have dominated the area for the past few years. Despite their commercial success, these generative models have theoretical and design flaws (intractable likelihood computation, constrained architecture, unstable training dynamics, etc.) that have led to the development of a new class of generative models known as “Diffusion Probabilistic Models” or DPMs. They were initially proposed by Sohl-Dickstein et al. 2015, and are based on the thermodynamics of the diffusion process. They learn a noise-to-data mapping in discrete steps, very much like Flow models.

Non-equilibrium thermodynamics serves as the basis for diffusion models. They learn to reverse the diffusion process to create desired data samples from the noise after defining a Markov chain of diffusion steps to gradually introduce random noise to data. Diffusion models, in contrast to VAE or flow models, are trained using a predefined technique, and the latent variable is highly dimensional (same as the original data).
In generative modelling, tractability and flexibility are two competing goals. Tractable models are amenable to analytical evaluation and low-cost data fitting (e.g., via a Gaussian or Laplace), but they struggle to capture the complexity of rich datasets. Flexible models can accommodate any type of data format, but they are typically expensive to evaluate, train, or sample from. Diffusion models are adaptable and analytically traceable. However, they rely on a lengthy Markov chain of diffusion stages to generate samples, which makes them quite time and computation intensive. Although new approaches have been put forth to speed up the procedure significantly, sampling is still slower than GANs.
Here’s the link to the next article: A Deep Dive into AI Art — Generative Art (Part 2)