PinnedThink DataTune your Spark!Spark tuning involves finely adjusting Apache Spark to maximize its efficiency and effectiveness for specific applications or workflows…Dec 20, 2023Dec 20, 2023
PinnedThink DataIntricacies of Data Shuffling in Apache SparkApache Spark stands tall as a powerful framework, and at the heart of its operations lies the concept of data shuffling. This process…Dec 20, 2023Dec 20, 2023
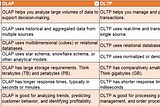
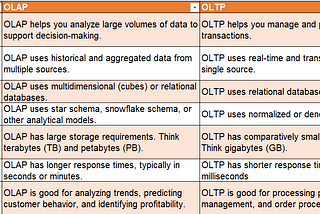
PinnedThink DataOLAP vs. OLTP in Data ManagementIn the realm of data management, two crucial systems, Online Analytical Processing (OLAP) and Online Transaction Processing (OLTP), play…Dec 23, 2023Dec 23, 2023
PinnedThink DataAvoid these at any cost in PySpark:As a Data Engineer, my day to day work life revolves around buildling robsut ETL and ELT applications using PySpark. A Robust data pipeline…Aug 18, 20232Aug 18, 20232
Think DataLearn Apache Kafka withTop-Down Learning Approach:Hello happy readers and curious engineers, I’m going to start a new series of articles on Apache Kafka. This is the first of the series…3d ago3d ago
Think DataLevels of Data Engineering: Roles and ResponsibilitiesClimbing the Data Engineering Ladder: From Junior to Lead in Healthcare6d ago6d ago
Think DataGame-changing reads that boosted my journey to Tech LeadIn the journey to grow in your job, you often explore different ways to learn, like watching talks and tutorials or diving into books…Dec 25, 20231Dec 25, 20231
Think DataGCP-BigQuery Interview Questions:Explain the process of optimizing BigQuery performance for complex analytical queries involving massive datasets.Dec 18, 2023Dec 18, 2023