Backpropagation for Dummies
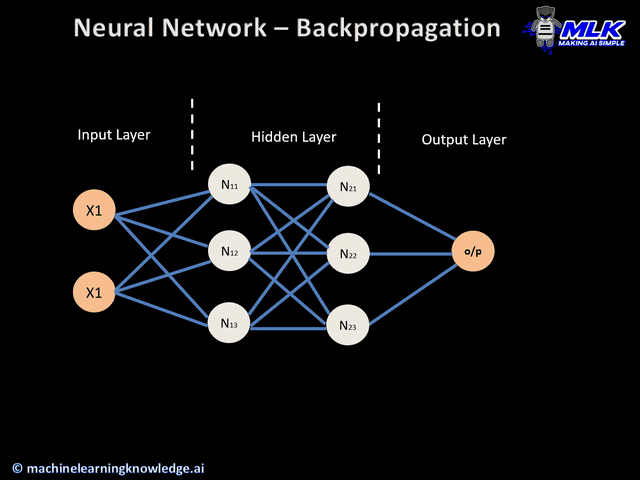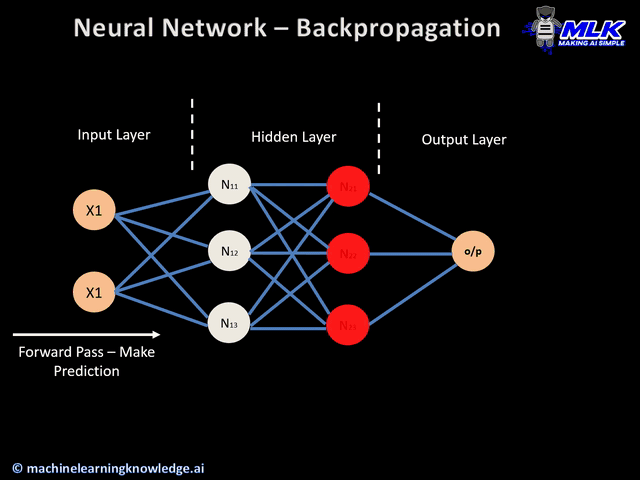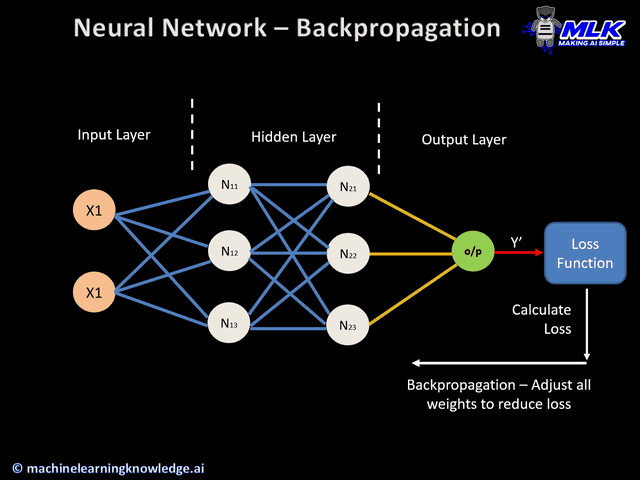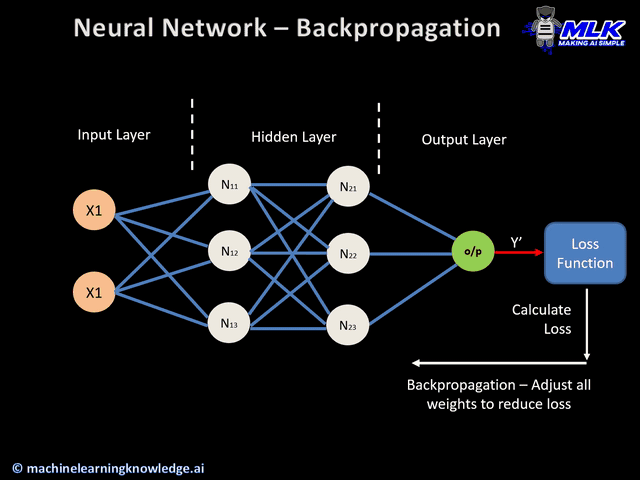
Table of content:
- Introduction and motivations
- Premises
- Algorithm
- Computation for a single unit
- Computation for a generic unit
- Summary and interpretation
- Conclusions
- Code snippet
- References
- Other useful sources
1. Introduction and motivations
Backpropagation algorithm already existed in the seventies, but its importance wasn’t fully appreciated until a famous paper by David Rumelhart, Ronald Williams and (guess who?) Geoffrey Hinton was published in 1986.
Today backpropagation algorithm is a milestone in ML: it is the workhorse of learning in neural models.
I strongly think it is useful and interesting to understand the mathematics behind this algorithm for many reasons: first of all, it is useful to stop approaching neural network learning as a mere “black box”, which is unfortunately a very common approach given the existence of quick and easy libraries that perform calculations for us. A lot of people stop at their application, few people read the documentation and hardly anyone is interested in the derivational calculus behind (unless they have an exam to pass at Uni!). Another reason is that “while the expression is somewhat complex, it also has a beauty to it, with each element having a natural, intuitive interpretation”. Most of the math steps have a specific interpretation and meaning, which are extremely interesting and useful for better understanding neural models: they actually gives us detailed insights into how changing the weights and biases changes the overall behavior of the network.
I hope I offered sufficient motivations, but if you need others I suggest reading this article by A. Karpathy.
In this article I will go over the mathematical process behind backpropagation algorithm and I will show you all the derivations and computations step by step in the easiest way possible.
I hope this will help you overcome the fear of “backprop math’s hell” by convincing you that simply… it doesn’t exist.
2. Premises
2.1 Notation and context

We consider a very basic architecture, the so called Multilayer Perceptron, i.e. a Feed-Forward fully connected Neural Network with just one hidden layer.
- i = refers to a generic input unit (so that input units are i_1, …, i_i).
- j = refers to a generic hidden unit (so that hidden units are h_1, …, h_j).
- k = refers to a generic output unit (so that hidden units are o_1, …, o_k).
- w_ji = the weight referred to the connection that associates the input unit i to the hidden unit j.
- w_kj = the weight referred to the connection that associates the hidden unit j to the output unit k.
- d = target value associated to each output unit.
- We are in a supervised learning setting.
- The training set is defined as {(x_1, d_1), …, (x_l, d_l)} so it contains all the couples (input, target) from 1 to l.
2.2 Cost function
What emerges from the 1986 paper is that backpropagation aims to minimize the so-called cost function by adjusting network’s weights and biases (basically, we can control this function by changing w and b). The level of adjustment is determined by the gradients of the cost function with respect to those parameters.
Hence, the goal of backpropagation is to compute the partial derivatives of the cost function with respect to any weight w or bias b in the network.
For backpropagation to work we need to make two main assumptions about the form of the cost function. Before stating those assumptions, though, it’s useful to have an example cost function in mind, as well as the definition of cost function itself.
Although we are taking for granted, in this article, that the reader has some basic knowledge of ML, we provide a very quick definition of cost function (also called “metric”). It is a function that: (i) measures the performance of a model for given data,(ii) quantifies the error between predicted values and expected values (iii) and presents it in the form of a single real number.
Depending on the problem, a cost function can be formed in many different ways. In our context, the purpose of the cost function is that of minimization, i.e. the returned value is usually called cost, or error, and the goal is to find the values of model parameters for which the function itself returns as small number as possible. Hence, when training our network, the goal will be to get the value of this cost function as low as possible.
Here we will use one of the most commonly used metric, that is the Mean Squared Error, i.e. the average squared difference between the predictions and expected results (in other words, an alteration of MAE where, instead of taking the absolute value of differences, they are squared).
Why do we choose MSE? Well, you should know that differential calculus using MAE is problematic. MSE instead has good mathematical properties which make the computation of it’s derivative easier, and this is is relevant when using a model that relies on the Gradient Descent algorithm.
MSE can be written in Python in this way.
So what assumptions do we need to make about our cost function, in order for backpropagation to be applied?
The first assumption we need is that the cost function can be written as an average over cost functions for individual training examples, which we call “patterns” p. With this assumption in mind, we’ll suppose the pattern p has been fixed, and sometimes drop the p subscript, writing the cost E_p as E.
The second assumption we make about the cost is that it can be written as a function of the outputs from the neural network. The MSE perfectly satisfies this assumption by its definition.
Given these premises, the error function we will use is defined as follow:
- The error for each single pattern p is defined as:

i.e. for pattern p compute the sum of the difference between the real target d and the produced output o, w.r.t all the k output units (as specified before, to simplify the notation p will be eventually omitted).
- The (total) error — for all patterns — is defined as the sum of the errors for each pattern:

Based on this error function’s value, the model “knows” how much to adjust its parameters in order to get closer to the expected output d. This happens exactly using the backpropagation algorithm.
If you’d like to have an overview of other existing cost functions commonly used in Neural Networks, I suggest reading this article. Moreover, for backpropagation derivatives computation made by using more complex cost functions than MSE, like Cross Entropy Likelihood, I suggest reading this article and also this one.
2.3 Differential calculus basis needed
These are the differentiation rules that we need to know in order to solve all the following computations.
As you can see, they’re just three! They will strongly help us step by step in dealing with the gradient calculation.

3. Algorithm
3.1 Gradient Descent
We recall that our aim is to find the w parameters values that minimize the total error E_tot.
SPOILER! For doing this we use the Least Mean Square (LMS) approach i.e. the minimization of the mean square error (MSE) through successive iterations.
How can we actually minimize the cost function during the training process to find a set of weights that work the best for our objective?
To do this we look at a class of algorithms, called iterative optimization algorithms, that progressively work their way towards the optimal solution. The most basic of these algorithms is gradient descent, which follows the derivatives to essentially “roll” down the slope until it finds its way to the (global) minimum.
One question may arise: why computing gradients? To answer this, we first need to revisit some calculus terminology:
- Gradient of a function in point x is a vector of the partial derivatives of the function in x.
- The derivative of a function measures the sensitivity to change of the function value (output value) with respect to a change in its argument x (input value). In other words, the derivative tells us the direction in which the function is going.
- The gradient shows how much the parameter x needs to change (in positive or negative direction) to minimize the function.
Hence our aim is to compute the gradient of the error and than take its opposite in order to have the descent direction on the surface of E_tot (Gradient Descent Method for minimization). If we repeat the process enough (iteratively), we soon find ourselves nearly at the bottom of our curve and much closer to the optimal weight configuration for our network.

N.B. For algorithms relying on Gradient Descent to optimize model parameters, every function has to be differentiable! (and, generally speaking, it should also be more or less convex — in reality, it’s almost impossible for any network or cost function to be truly convex — ).
3.2 Upgrade rule
More formally, gradient descent looks something like this:

This is the gradient descent update rule (aka delta rule). It tells us how to update the weights of our network to get us closer to the minimum we’re looking for.
I’ll not dwell here on learning rate, momentum, regularization and other techniques and hyperparameters of a neural network. I will instead put some interesting link to other articles in the final references section, just in case you want to learn more about them! (or maybe I’ll write another medium story on parameter tuning… who knows?). The same is for considerations about optimality and complexity of backpropagation algorithm, and for other options to choose an iterative optimization algorithm (Adagrad, Adam, …).
The basic principle remains the same throughout — gradually update the weights to get them closer to the minimum. But regardless of which optimization algorithm you use, we still need to be able to compute the gradient of the cost function w.r.t. each weight.
In our context, the change of the weights is defined as the sum over all the patterns of the error for each pattern w.r.t. its weight.

3.3 Pseudocode
THE PROBLEM: compute the gradient of the cost function to build up the so-called generalized delta rule.
THE IDEA: compute the loss function (E_tot) → compute the gradient → update all the weights w in the network. Then repeat until convergence or until other stopping criteria.


Step (1) represents the proper gradient computation. We will focus exactly on this point.
Step (2) is the upgrade rule for w — see “delta rule” above.
4. Computation for a single unit
As a preliminary exercise, I suggest we start with a simpler calculation, just to get familiar with mathematical steps and tricks that we will need in Section 5. In addition, with this exercise we obtain a result that will be needed later on. If you are pretty confident with differential calculus yet, you can skip this section and then come back here to get that step you will need, already computed for you.
As I was saying, as a preliminary exercise I propose to start by considering just a single neuron i.
What we are going to do: computing the derivative of the error w.r.t. one single unit i, i.e. computing

We start by writing the error function as defined above, outlining the role of the output o as function of the net:

Here there is highlighted in bold the scalar product between the input vector and the respective weights, i.e. the net.

For simplicity, as already mentioned before, we consider just the error E_p, so w.r.t. a single pattern p, and then we sum everything up at the end.
Now we apply the chain rule and so we decompose w.r.t. the net.

where the function f corresponds to the error, the function g corresponds to the net, and both are functions of the variable x, which corresponds to weights w associated to the unit i we are considering.
So we obtain:

We are going to solve separately the two components in (4).
- First, we focus on the second term and we extend the dot product with the sum of all the components:

This because the term is equal to zero for every component except for the i-th component. For better comprehension we show the summation of all the possible terms:

- Now we focus on the first term in (4): we use again the chain rule in (3) but now we consider as function g the output o, for which we use the notation out.

where f is the activation function.
So we obtain:

By making explicit out and net definitions, respectively (2) and (5), we obtain:

Now we consider again the two terms separately.
- For the first term in (6), by recalling (1), we have:

This because, for the formula

we have that

in which

- For the second term in (6) we have:

By putting everything together, we have the result of (6):

and we can write the final result of (4):

where

so we can write the result in this way

This is the new delta rule.
5. Computation for a generic unit.
Do you know the chain rule? Then you know the neural network backpropagation algorithm!
Now, differently from the previous simple case, we have not just one unit but many ones, so we need to introduce the index t to denote a unit among the many.
What changes now is that we don’t know the position of the unit t in the network architecture (that’s why it is generic), so we must consider and distinguish both the cases whether it is an hidden unit or an output one.
WHAT WE ARE GOING TO DO: assuming a specific pattern p, computing the derivative of the error w.r.t. a generic unit t, i.e. computing

which, recalling “gradient computation formula” in section 3.2, we can rewrite as

where t is a generic unit in the network and i the input from a generic unit out_i to the unit t.
This holds because, as already explained,

N.B. remember that, as always, for the purpose of our computations we are considering a single pattern p.
We start by applying the chain rule (3) w.r.t. the net in the formula (10), and we obtain:

As in section 4, we proceed by considering the two terms separately.
- For the second term in(11) we have that

This because, recalling the definition of net (2) and out (5)

where a is used as generic index for the internal sum.
Since we don’t know were we are in the network, it is better to use the out to indicate the fact that it is the output for another unit.
All the components of (12) are zero, except for the case in which j=i. So we have

(which denotes the input i from a generic unit out_i to the unit t).
- Now we consider the first term in (11) and we introduce a new variable to denote it. Then we apply the chain rule w.r.t. the out to compute this quantity

Meanwhile, we rewrite the (10) with the results we got in order to summarize what we did until now:

Now, in order to solve the remaining term in (13), which is

we have to distinguish to cases on the basis of where could be located in the network.
- Is the unit t an output unit?
- Is the unit t an hidden unit?
This because the two contributions over the error E are different. As a matter of fact, since we are computing the partial derivative of the error w.r.t. the unit t, this influence takes a completely different shape in case 1 and 2, so we must consider and distinguish both the situations.
HINT: Use the network graph below to localize the unit t in each case!

Let’s drill-down each one case at a time.
Case 1
Generic unit t is an output unit k.
In this case:

Note that, in the following, we distinguish between indexes k and k’. In particular, k’ is the one that we use just for internal summing, while k is a fixed value denoting the out w.r.t. which we are deriving.
So, by applying the formulas (8) and (14), we obtain

This because, when making the sum explicit, all the terms are zero except for the one in which k’=k. So the ∑ symbol vanishes.

The final result is:

By putting together (13) and (15) we got the derivative of the output unit k:

This is precisely an error signal, because it contains the difference between the output produced and the desired target (remember that we are in a Supervised Learning setting).
(Now you can appreciate the utility of the preliminary exercise!)
Case 2
Generic unit t is an hidden unit j.
HINT: again as further help, try to figure out where we are located in the network structure at each step of the computation by exploiting the image above.
This is a much more interesting case because it is exactly the point from which the problem of defining a Learning Algorithm for MLP arose: it is not easy for the model to assign the corresponding credit to hidden units (credit assignment problem — CAP) because the error signal is not directly measurable. We don’t know the error or the desired answer for the hidden units (information that is absolutely necessary to update their weights!). So it is exactly from this context that the need for backpropagation algorithm arose.

So we have t=j and now we focus on solving the term:

We apply again the chain rule but exploiting the knowledge we have about the structure of out network: we know that the hidden units are connected with all the output units (i.e. for each k there exist a connection with j). So we will sum up the contributions on all the units k in the output layer because we do not know which of them will be interested, while the influence of hidden units j is on the whole output layer.
Considering all these contributions of the hidden units over all the output units (and summing them up) is the key point of backpropagation algorithm.

In this way we have decomposed considering the influence of the net of output layer k over the error, and the influence of all the output units j on the net of k.
In particular, note that the first term in (17) has already been solved previously! The solution is exactly (16) in case 1.
So we focus on solving just the second term of(17).

As in the previous cases, all the partial derivatives are zero, except when k’=j. So we put together (16) and (18), and the final solution of (17) is

hence, for case 2, we can write the error signal for the hidden units.

Note that, if you prefer, you can alternatively derive the (19) in a direct way, as described in the picture below.

Now that we have a partial derivative both for the output (16) and the hidden (20) units, we can finally upgrade the weight (if needed, go back to section 3.2).
Any weight in the network has a generalized delta rule (10) in which the ∆t term takes the form of (16) or (20), depending on which kind of unit is considered (output or hidden, respectively — case 1 or 2).
What is interesting to note in (20) is the presence of the weight w_kj. It means that we are retropropagating the ∆k from the output layer to the hidden layer, exactly through this weight that connects them. So we are propagating back the error signal (hence the name backpropagation) through the entire network, in a way that is proportional to the weight of the connection between output and hidden units.
N.B. Of course we always have to take into account the shape of the network. In this case we are assuming the presence of a connection between units j and k (we considered as reference model a fully connected feed-forward neural network).
In general, depending on the connections you have on your network architecture, you can change the propagation of the delta by modifying the respective mathematical steps in the previous computation of partial derivatives.
Math follows the net’s architecture.
6. Summary and interpretation
For a generic unit t, with input from out_i, we derived:

- If t = k (i.e. t is an output unit)

- If t = j (i.e. t is an hidden unit)

IMPLEMENTATION TIP: For each pattern p this computation can be used directly for the on-line form or summing them for the batch form.
In order to understand and visualize even better the retropropagation of the error signal from output layer (that is the crucial part of the algorithm), represented by the connection w_kj, we focus on the sum in (22) and we give a graphical representation of it in the picture below.

The image shows the contribution of delta at each output unit k, summed up, weighted with the respective connection weight w_kj, and passed to the hidden unit j. Of course this process stands for each hidden unit j. In some sense, we can say that the associated weight w_kj represents how much the unit k is responsible of its error. In this scenario, the general responsibility for the total error will be distributed through the network according to weights w_kj (here we have computed only local values: however the change of weights have a global effect on the network).
The beauty in backpropagation is that through this “delta idea” it is able to decompose the effect of the error, and the influence of each weight on it, over the entire network structure.
This process of retropropagation of can be generalized and applied to a deeper model with many hidden layers. In this scenario, the deltas do not come just from the output layer but also from any generic layer above the current one (a generic upper layer K).
Hence, for each pattern p:

where δt is the delta at that layer for unit t, and o_i is the input from unit i to unit t through the connections w_ti.
So the backpropagation algorithm does not work just for MLP but, in general, with any neural model (with the proper modifications and adaptations to the structure of the model itself). It is fundamental for training Recurrent NN, Deep Learning models, etc…
Coming back to the image at the very beginning of this article, we can observe again the process but now fully understanding it. The back arrow in the animation shows how the error is propagated in the backward direction to the front layers till the end, while the neurons across the network start adjusting their weights.
7. Conclusions
The “secret” in the functioning of the algorithm is that each of the derivatives we computed can be simplified, once we choose an activation and error function, such that the entire result would represent a numerical value. At that point, any abstraction has been removed, and the error derivatives w.r.t. any weight in the network can be used in a gradient descent approach (as discussed earlier) to iteratively improve upon the weight.
STUDY HINT: Read the derivation at 3 levels: (i) singular math steps (ii) interpretation of the (local) changes of a quantity with respect to the others (due to the partial derivatives) (iii) general framework of the meaning of the provided decomposition, i.e. to find delta values for each level decomposing the delta error ON THE NETWORK at hand.
8. Code snippet
If you need some ready-to-use code as starting point for your implementation or as reference to fully understand the scope of this article, check this GitHub repository.
I strongly recommend to try your own different implementations as a further mean to grasp the backpropagation functioning, to explore different behaviors, and have fun with this algorithm!
9. References
- Rumelhart, D. E., Hinton, G. E., and Williams, R. J., “Parallel Distributed Processing” MIT Press, Cambridge, MA (1986) Chapter 8.
- Mitchell, Tom M., “Machine learning”. McGraw Hill (1996) Chapter 4.
- Haykin, S., “Neural Networks”, 2nd Edition. Prentice Hall (1998).
- “Derivation of the Back-propagation based learning algorithm”, A. Micheli, Department of Computer Science, University of Pisa, (LaTeX version by F. Errica)
- Nielesen, M. “Neural Networks and Deep Learning”, chapter 2, URL: neuralnetworksanddeeplearning.com
- Kamil Krzyk, “Coding Deep Learning for Beginners — Linear Regression (Part 2): Cost Function”, in medium.com
- Simeon Kostadinov, “Understanding Backpropagation Algorithm”, 2019, in towardsdatascience.com
- “Animated Explanation of Feed Forward Neural Network Architecture”, in machinelearningknowledge.ai
- Kapur, R., “Neural Networks & The Backpropagation Algorithm, Explained”, 2016, in medium.com
10. Other useful sources
I hope this article manages to throw some light on the math behind backpropagation. To further enhance your knowledge, I suggest here some other useful sources to read. Enjoy!
- My Youtube playlist about backpropagation
- “Dummies guide to Cost Functions in Machine Learning”, in machinelearningknowledge.ai
- Prakash Jay, “Back-Propagation is very simple. Who made it Complicated?”, medium.com
- Tushar Gupta, “Deep Learning: Back Propagation”, towardsdatascience.com
- Bernard Widrow and Eugene Walach, “Thirty Years of Adaptive Neural Networks: Perceptron, Madaline, and Backpropagation”, in “Adaptive Inverse Control: A Signal Processing Approach”, Reissue Edition, 2008
If you like this article, please recommend it and share it. Thank you.
