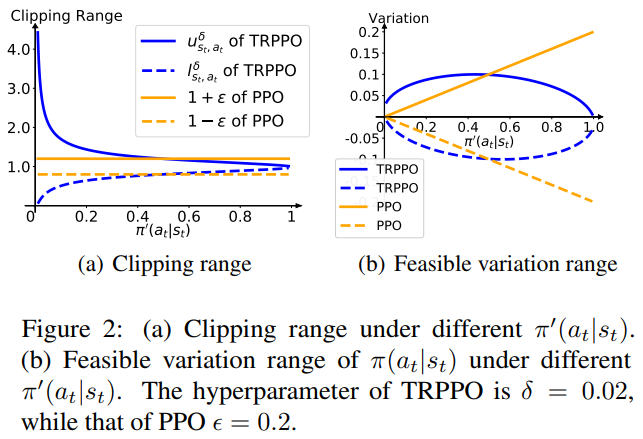
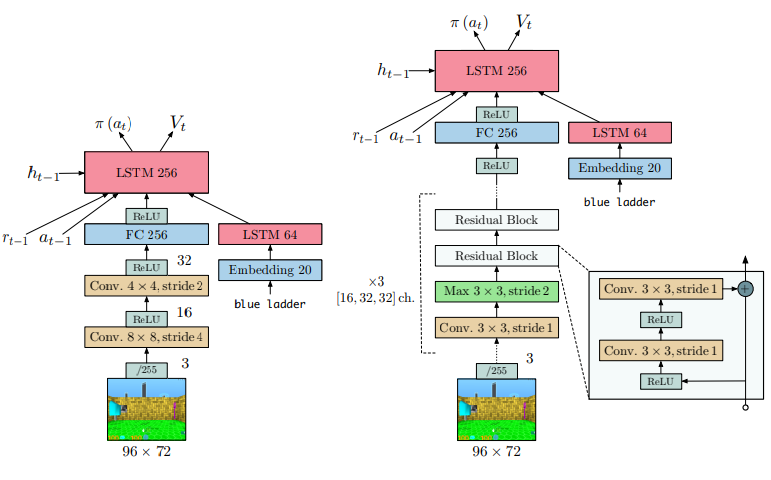
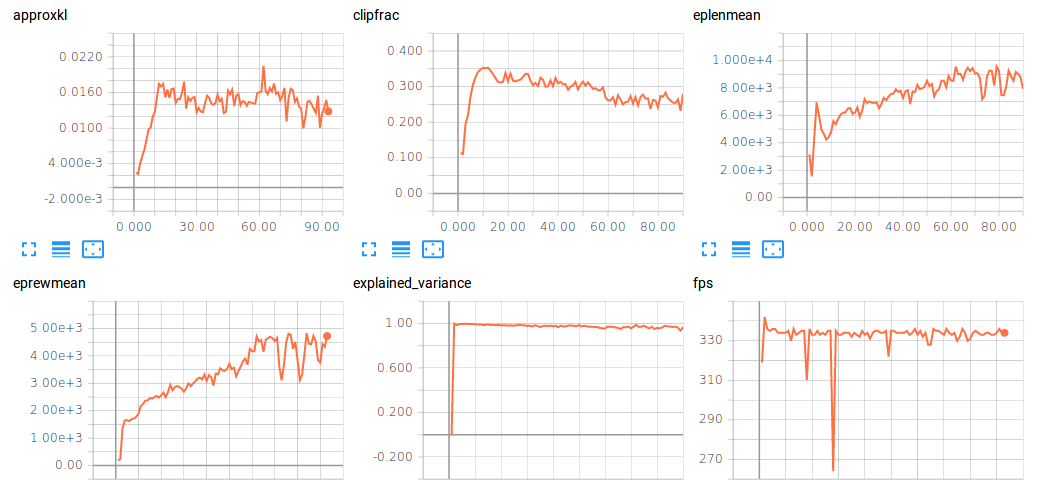
OpenAI Baselines and Unity Machine Learning have TensorBoard integration for their Proximal…
A short summary and code example followed by explanations.
When I’m looking for new research papers to read, it’s often hard to tell what is worth reading. How reproducible are the results? Will this paper actually have a lasting impact in the field of Reinforcement Learning (RL)? With those…
Joint PPO is a modification of Proximal Policy Optimization (PPO). Joint PPO was used by the winner of OpenAI’s Retro Contest. Joint PPO in a few lines:
During meta-training, we train a single policy to play every level in the training set. Specifically, we…