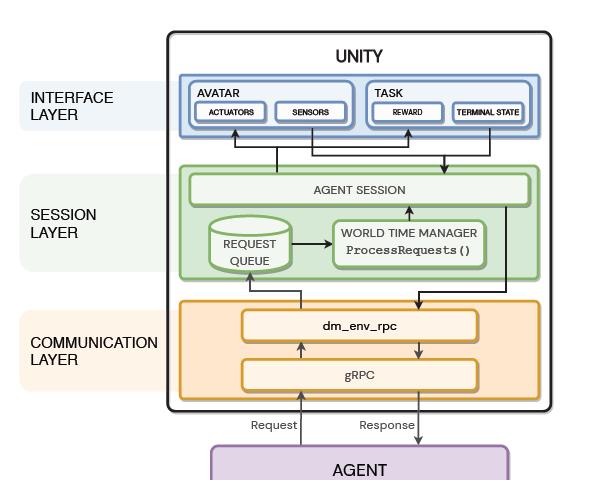
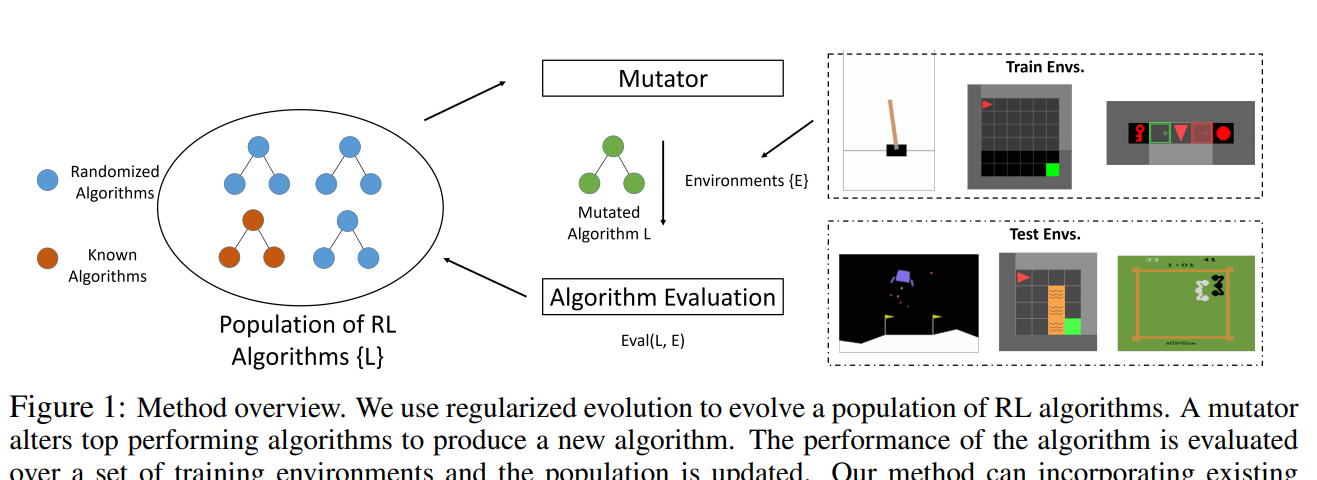
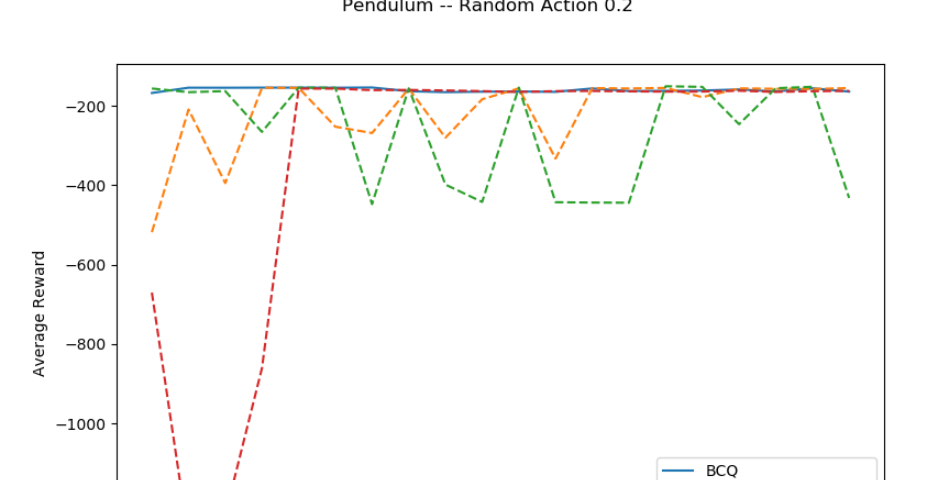
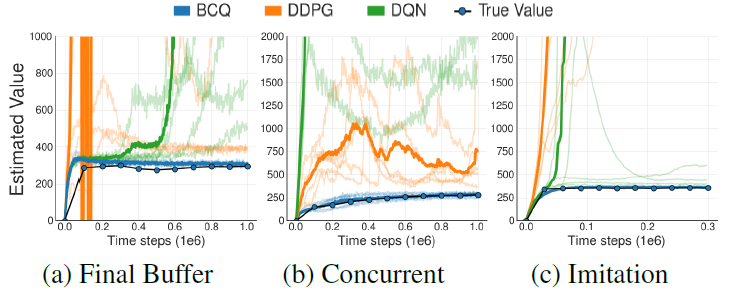
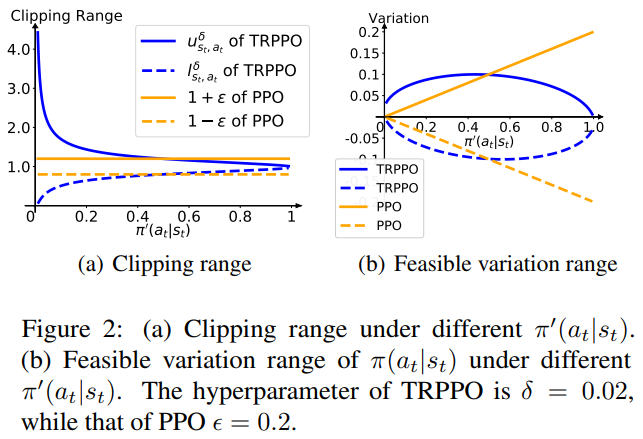
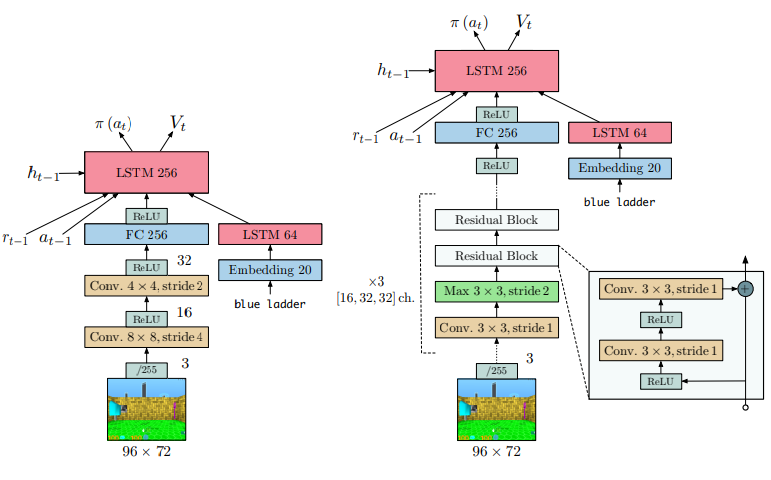
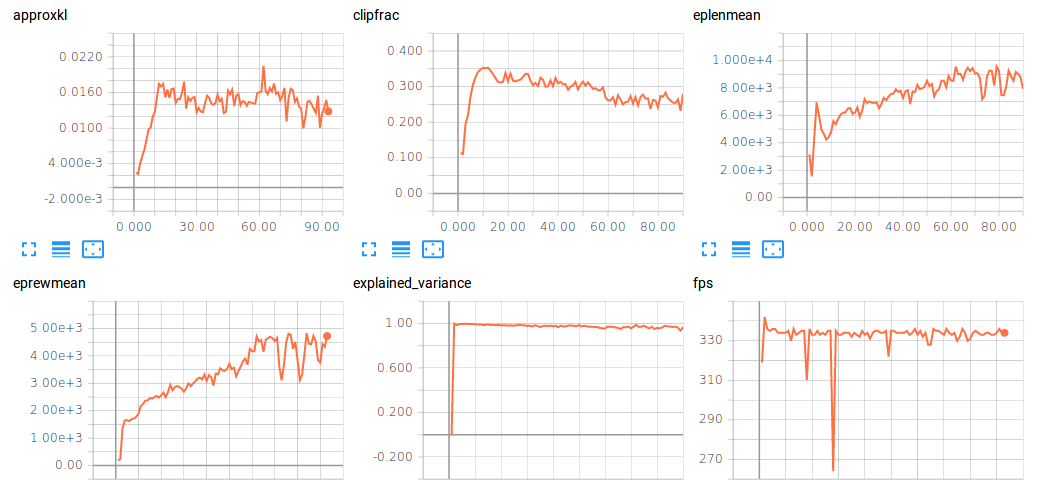
Reinforcement Learning Competitions — 12/1/2022 Update
Here is a list of upcoming, ongoing, and completed Reinforcement Learning competitions I have compiled:
https://docs.google.com/spreadsheets/d/1Rw_rWzI-8lfGKtHHFlSWqswyZrCRPuwmQbad1ZlYxIk/edit?usp=sharing