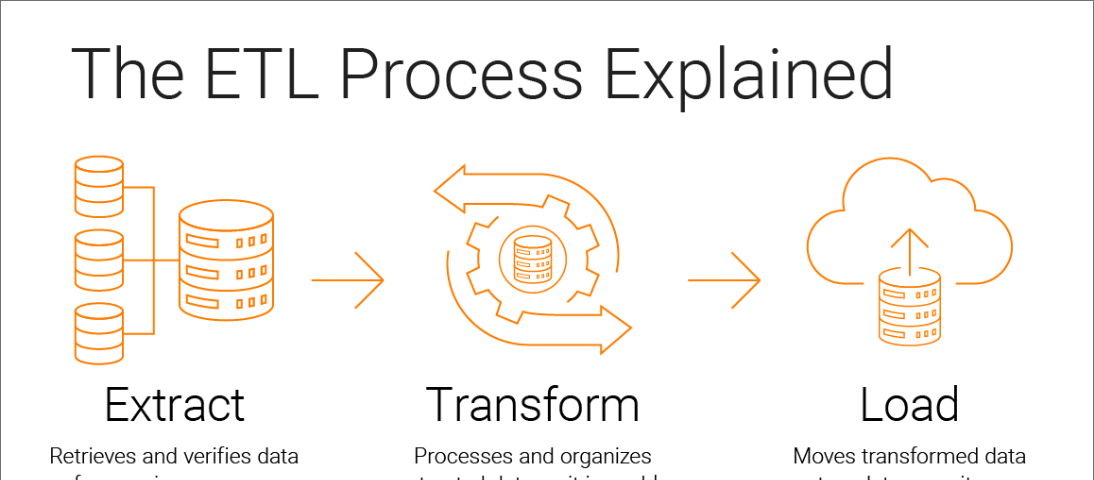
When it comes to managing and analyzing big data, two names often come up: Databricks and Snowflake. They’re both…
A pivot table in SQL is a technique used to transform data from rows into columns, or…
Apache Spark is a powerful distributed computing framework that processes large-scale data sets…
When it comes to working with data in Python, choosing the right data structure is key…
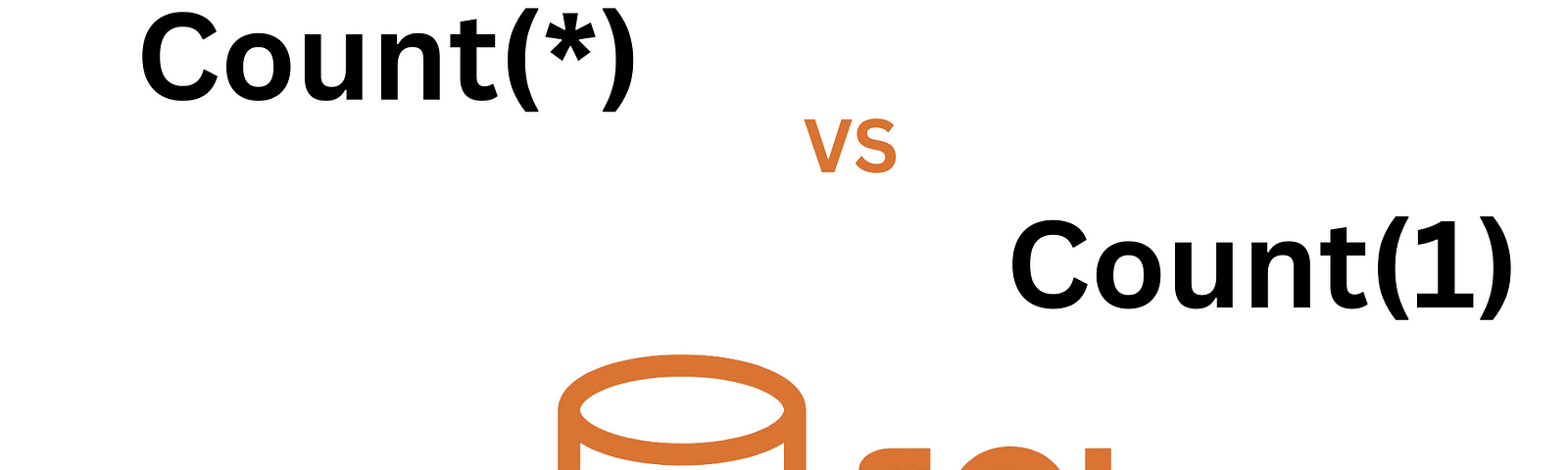
If you’ve spent any time writing SQL queries, you’ve probably seen both `COUNT(*)` and `COUNT(1)` used to…