IoT Learning Algorithms and Predictive Maintenance — Part III: Few-shot Learning
Author: Dr. Taşkın Deniz, Data Scientist at Record Evolution GmbH

Summary
The article tackles smart data processing of the Internet of Things (IoT) in a predictive maintenance context and relates this to recent developments in semi-supervised learning. While written with an eye towards a non-expert audience, the article references recent scientific publications. We leave it to the curious and technically oriented reader to expand their knowledge on the ideas we have sketched out (see References). We aim to be informative and open minds to stimulating discussions on IoT and data analytics.
We cover the topic of IoT Learning Algorithms and Predictive Maintenance in a series of three articles. In PART I, we present a simple case study in detail and discuss some learning algorithms related to it. In PART II, we focus on IoT data analytics and applications to IoT design for predictive maintenance. In PART III (the current article), we review recent literature on semi-supervised learning and compare the foundations of different methods. We introduce real-life cases in which few-shot learning may provide an efficient technique for smart IoT analytics and data streaming. At the end of this article, you will find a glossary of terms and suggestions for further reading.
1. Rare Events and Anomalies
Before diving into techniques to deal with rare events and anomalies, let’s define them. A rare event is an event in time with marginal statistics, that is, an event occurring too few times with respect to the norm (the norm being the average time scale of the background). A good example is an earthquake. An anomaly is a rare event that has different features than the events in the norm distribution, meaning that an anomaly is generated by a process different from the processes attributable to the norm. An anomaly is often seen as the analog of an outlier, defined by Hawkins as follows: “An outlier is an observation which deviates so much from the other observations as to arouse suspicions that it was generated by a different mechanism”. In other words, an outlier is a data point that has many different properties compared to the natural state of the dataset.

Rare events often refer to catastrophes or breakdowns. So the cost of a rare event often is huge. On the other hand, it is tricky to predict a rare event. Straightforward methods fail in cases of extreme imbalance and …..the training data will often have imbalanced data (the number of normal data will be much larger than the number of abnormal data). We need to find a way to deal with imbalanced data. One easy solution is sampling (sampling up the number of abnormal data and sampling down the number of normal data). Another solution to be taken into consideration is applying weights to labels.
In Part I, we presented a hypothetical hierarchical solution to the anomaly detection problem, in which case one also runs into imbalance issues.

2. Anomaly Detection: IoT Network and Security
Anomaly detection is a vast topic. The following chart demonstrates a plethora of models:

Here we consider a case where we have large amounts of training data with rare anomalies hidden in them. We are trying to approach a new case with supervised learning. Later, we will also include updating the set of labels on the fly using semi-supervised techniques.
We touched upon the topic of anomalies and dealt with a concrete example in Part I of this article series. Anomalies can be detected by hand via a simple statistical criterion (as they can be conceptualized as outliers). On the other hand, the goal is to automate the detection process using evolving machine intelligence and the learning structure of certain anomalies.
In Part II of this article series, we talked about network security. There we presented security protocols and mechanisms. Here we want to enter the discussion of smart security in an industrial context. A comprehensive list of anomaly detection algorithms is provided in the following table [12]:

We want to indicate that in the referenced publication [12], the authors have presented a complete review of classical anomaly detection results. Here we only cover algorithms related to network security. Below we introduce details from Table 1:
- Missing data prediction: In real-world examples, data quality is an issue. Missing data is part of an automated process as one can’t always guarantee data quality on the fly.
- Distributed/Centralized: The result of the predictor can be distributed or centralized.
- Complexity: This is about how difficult the problem is computationally, or how important regarding computational resources.
- The mechanism: Outlier detection; can also be adaptive or distributed.
Below we sketch out some classical methods of anomaly detection and their properties:
- Distributed Outlier Detection Using Bayesian Belief Networks: … Deciding whether an observation is an outlier or not depends on the behavior of the neighbors’ readings as well as the readings of the sensor itself. This can be done by capturing the spatio-temporal correlations that exist among the observations of the sensor nodes. By using naive Bayesian networks for classification, we can estimate whether an observation belongs to a class or not. If an observation falls beyond the range of the class, then it can be detected as an outlier. https://minerva-access.unimelb.edu.au/bitstream/handle/11343/34872/67630_00004013_01_issnip07.pdf?sequence=1&isAllowed=y
- Outlier Detection Using k-NN: …using an Indegree Number (ODIN) algorithm that utilizes the k-nearest neighbor graph. To address the problem of unsupervised outlier detection in wireless sensor networks, we develop an algorithm that (1) is flexible with respect to the outlier definition, (2) works in-network with communication load proportional to the outcome, (3) reveals its outcome to all of the sensors. http://cs.joensuu.fi/~villeh/icpr2004.pdf http://www.cs.technion.ac.il/~ranw/papers/wolff06icdcs.pdf
- Detecting Selective Forwarding Attacks Using SVM: …In selective forwarding attacks, malicious nodes behave like normal nodes and selectively drop packets. The authors propose a centralized intrusion detection scheme based on Support Vector Machines (SVMs) and sliding windows. https://minerva-access.unimelb.edu.au/bitstream/handle/11343/34872/67630_00004013_01_issnip07.pdf?sequence=1&isAllowed=y
- Distributed Outlier Detection Using SVMs: …uses distributed, one-class quarter-sphere support vector machines to identify anomalous measurements in the data. https://ieeexplore.ieee.org/document/4289308
- Online Outlier Detection: …an online outlier detection technique with low computational complexity and memory usage based on an unsupervised centered quarter-sphere support vector machine for real-time environmental monitoring applications of wireless sensor networks. The proposed approach is completely local and thus saves communication overhead and scales well with an increase of nodes deployed. https://ieeexplore.ieee.org/document/4761978
- Intrusion Detection System: An intrusion detection system is a device or software application that monitors a network or system for malicious activity or policy violations. To improve the whole performance of the network intrusion detection system (IDS), the paper analyzes the characteristics of data used in IDS to present an approach in which intruders are recognized. The approach is based on an immune algorithm (IA) and a support vector machine (SVM). https://link.springer.com/chapter/10.1007/978-3-642-19853-3_54
- Linear Outlier Detection takes into account the correlation between sensor data attributes and proposes two distributed online outlier detection techniques based on a hyperellipsoidal one-class support vector machine (SVM).
- Analyzing attacks with SOM: The proposed detection system monitors network traffic on each node and analyzes collected data by self-organizing maps to extract statistical regularities from the input data vectors and encode them into the weights without supervision. We evaluate our approach to detect network attacks on AODV and DSR protocols using OPNET. https://ieeexplore.ieee.org/document/4215510
As mentioned above, one important aspect of anomalies is that they are rare compared to mainstream behavior. Thus, we need to come up with strategies to overcome the data imbalance in samples. In this sense, one-shot learning is a powerful semi-supervised learning method that can be adapted to IoT analytics. The main idea is that we have a central network model that copies itself to given devices and identifies a new category. The central model will be updated by singular examples detected by the edge device and will be reused in newly installed IoT devices. In summary, we have four steps:
- Central model in the cloud or a central fog resource: Long training history, mid-term fine-tuning time scale.
- Copy of the central model run in the local device: The replica of the central model will be sent to the edge devices.
- Edge or fog computing will be performed and the device will send the evaluated new information to the central model after the evaluation.
- All new info will be integrated into the model via few-shot learning.
This workflow can be optimized by increasing the number of training examples (meaning with given experience) for available resources at a given moment. In general, inheritance or transfer of knowledge is important for such smart IoT settings to work efficiently. Unfiltered data reported continuously wouldn’t just consume storage resources and consume redundant energy but will also create noise in the model where one needs the data to train a new model. The message is that Big Data collected randomly doesn’t necessarily lead to knowledge. Thus, we need smart local IoT analytics. Specifically, this can be accomplished by few-shot learning because the decision to report or act must only sometimes involve very very few examples.
3. Inductive Semi-supervised Learning
Here we suggest a selection of models that implement semi-supervised learning. The few-shot problem has been studied from multiple perspectives, including the similarity-matching [17], optimization [3], metric learning [14, 16,18], and hierarchical graphical models [15].
A survey by Tassilo Klein classifies the Semi-supervised Deep Learning algorithms. Below we present this classification and the corresponding references:
A. Data Level Approach:
- Employ external resources: collecting more data from external resources and evaluating them. [10]
- Generate new data: data augmentation or generative networks. [1]
B. Parameter Level Approach:
- Avoid overfitting, parameter space is constrained: Network pruning by output activity correlation measures, etc. [2]
- Guide the optimization algorithm: in general, several examples of meta-learning [3,5,7,11].
C. Combining both:
- Leveraged to fix the imbalance between parameter space and dataset size. [4]
3.1. Learning Relations: A Note on Metric Learning
The need for similarity of data as a way of evaluation is ubiquitous to machine learning. However, this is no longer feasible in complex cases that involve hand-crafted metrics. This is why one can train a metric with given parameters to represent this proximity. Such a metric is crucial for implementing clustering algorithms such as k-nearest neighbors or k-means [18]. General-purpose metrics such as Euclidean metrics can be applied to structural numerical data. Nevertheless, a good metric that captures the peculiarities of a given dataset is essential as generic metrics usually fail in this task.
Apart from the examples above, there are neural network-independent methods such as the Metric or Kernel Learning using prototypical networks [6], metric learning [16].

3.2. Generate Samples with GANs
With GANs, you can create additional samples from existing data that resemble the given samples but are not the same. Using this method, you can generate more anomaly data starting from a small set of anomalies.
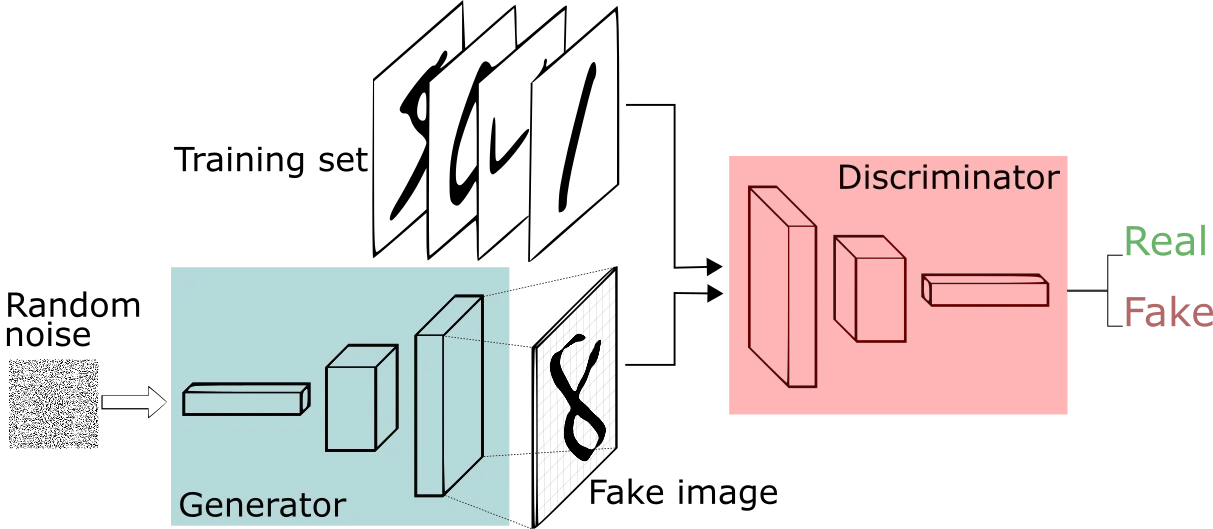
https://arxiv.org/abs/1810.01392
3.3. A Note on Meta-Learning
Why do we need meta-learning a.k.a learning of learning? There seem to be two main reasons why gradient-based optimization fails in the face of a few labeled examples:
- First, the variants of gradient-based optimization algorithms have not been designed specifically to perform well under the constraints of a chosen number of updates. Specifically, when applied to non-convex optimization problems with a reasonable choice of hyperparameters, these algorithms don’t have strong guarantees of the speed of convergence — beyond that they will eventually converge to a good solution after what could be millions of iterations.[9]
- Second, for each separate dataset considered, the network would have to start from a random initialization of its parameters — which considerably hurts the network’s ability to converge to a good solution after a few updates. [9]
Meta-learning suggests framing the learning problem at two levels. The first is the quick acquisition of knowledge within each separate task presented. This process is guided by the second mechanism, which involves a slower extraction of information learned across all tasks. [9]
Meta-learning has been presented in simple charts in [19]. The reader can refer to relevant publications to study the technicalities of the two optimization mechanisms in meta-learning applied to neural networks.
First of all, conventional optimization with gradient descent and variants is simply minimizing the distance between predicted and true labels while satisfying a regularization scheme (to reduce the number of parameters). The parameters of the gradient descent, i.e. learning rate, are given and fixed for the whole process.
Learning: Minimize the distance between predicted and grand truth by using a loss-function metric.

The idea of meta-learning is optimizing learning parameters as well as the network parameters via a second process. For example, the learning rate of the loss optimizer can be adapted in such a way that its learning slows down following the part of the network we are looking at. This can be achieved by additional dynamical variables (for details, please see [19] and the references therein).
Meta-learning: Training the hyperparameters or the optimizer. Optimize the optimizer!

Additional processes to follow are:
- Second-order derivatives: Back propagating the meta-loss through the model’s gradients involves computing derivatives of derivative, i.e. second derivatives. This is generally avoided to reduce complexity.
- Coordinate sharing: To optimize millions of parameters, we need to reduce the dimensionality, for instance via coordinate-sharing [7]. This means we design the optimizer for a single parameter of the model and duplicate it for all parameters (i.e. share its weights along the input dimension associated with the model parameters).
3.4. A Note on Semi-supervised Learning with SVMs
Despite the whole buzz about Deep Learning with its data-hungry training epochs and yet non-intuitive implicit mechanisms, one can simply ask if there is an easier way of doing semi-supervised learning. The answer is: yes and no! At the conceptual level, SVMs are really powerful tools to implement semi-supervised learning. In practice, however, they may lead to NP-hard problems.

“While deep neural networks have shown outstanding results in a wide range of applications, learning from a very limited number of examples is still a challenging task. Despite the difficulties of few-shot learning, metric-learning techniques showed the potential of the neural networks for this task. While these methods perform well, they don’t provide satisfactory results. In this work, the idea of metric-learning is extended with Support Vector Machines (SVM) working mechanism, which is well known for generalization capabilities on a small dataset.” [27]

3.5. Examples of Recent Methods:
In this section, we look at a few methods that have been introduced over the past years:
- From the paper:
2. Methods from recent articles:
3. Out-of-distribution Examples: “Several previous works seek to address these problems by giving deep neural network classifiers a means of assigning anomaly scores to inputs. These scores can then be used for detecting out-of-distribution (OOD) examples (Hendrycks & Gimpel, 2017; Lee et al., 2018; Liu et al., 2018)”
4. Outlier Exposure: “ We propose leveraging diverse, realistic datasets for this purpose, with a method we call Outlier Exposure (OE). OE provides a simple and effective way to consistently existing methods for OOD detection… Utilizing Auxiliary Datasets. Outlier Exposure uses an auxiliary dataset entirely disjoint from test-time data to teach the network better representations for anomaly detection.”
5. https://arxiv.org/abs/1805.09411
4. Online Learning
…..Having discussed the mechanism of one cycle of learning and deployment, we need to start thinking about building a flexible system to implement such cycles in a continuum in the long term.

Batch or offline learning algorithms take batches of training data to train a model. Batch learning is an approach whereby all the data is ingested at once to build a model. Online learning algorithms take an initial guess model and then pick up observations from the training population to recalibrate the weights on each input parameter. Below are several trade-offs in using the two algorithms:
- Computationally much faster and more space-efficient
- Usually easier to implement
- More difficult to maintain in production
- More difficult to evaluate online
- Usually more difficult to get “right”
In cases where we deal with huge data, we are left with no choice but to use online learning algorithms. The only other option is to do a batch learning on a smaller sample.
Conclusion. The Record Evolution Platform for IoT and AI
In this article series, we have outlined some challenges in dealing with a smart IoT environment. Our goal is to make IoT devices collaborative and to keep on improving their pseudo-perception of the world. To do so, however, we need an infrastructure for device and data management.
First, we need to build a swarm environment for IoT devices with a flexible setup, data, and meta-data collection mechanisms. The Record Evolution platform provides a frontend where one can manage IoT devices and deploy apps in them. Another crucial component is the data infrastructure needed to create pipes of data inflow and transmission to a learning mechanism. The platform’s data science studio is a transparent and user-friendly cloud data platform handling data acquisition, data transformation, and data visualization. The next step is using cloud resources and flexible semi-supervised algorithms to transfer the collected data into the intelligence. On top of this, we need to re-deploy and update according to the needs of the local IoT environment. The platform’s IoT development studio can handle this task.
In our analysis, semi-supervised anomaly detection is the way to go due to the structural properties of real IoT data sets (the imbalance between known and unknown). Unsupervised learning is always a solution when labeled data isn’t available. However, one should also exploit transfer learning [12, 13, 20] as a healthy state as it is rather stereotypical and is modeled by an abundance of data, meaning that we will have a plethora of labeled states. This can simply help detect less common states and characterize them. Later on, such new states can be learned, and hence the boundaries of the known anomaly universe can be extended. We believe few-shot learning is the method that captures the specifics of the problem at hand.
Closing Statement of the Series
In this three-piece article series, we covered the topic of an end-to-end IoT service and infrastructure. Our main focus was on how to implement smart IoT in a world of dynamic heterogeneous data. Overall, these 45 minutes of reading aim to reach both non-experts and a technically oriented readership.
I. IoT is crucial for predictive maintenance. To accomplish this, we need to refer to edge computing and smart algorithms.
II. IoT requires data and device management infrastructure. Deployment and update cycles are part of the intelligence inheritance process.
III. Inductive semi-supervised learning is a good candidate for a smart IoT algorithm. While there are various options when choosing the exact learning algorithm, we mostly presented Deep Neural Networks and Support Vector Machines.
References
1. Article: Generative Adversarial Residual Pairwise Networks for One-shot Learning
2. Article: Efficient K-shot Learning with Regularized Deep Networks
3. Article: Optimization as a Model for Few-shot Learning
4. Article: Low-shot Visual Recognition by Shrinking and Hallucinating Features
5. Article: Model-Agnostic Meta-learning for Fast Adaptation of Deep Networks
6. Article: Prototypical Networks for Few-shot Learning
7. Article: Meta-SGD: Learning to Learn Quickly for Few-shot Learning
8. Article: Deep Learning for IoT Big Data and Streaming Analytics: A Survey
9. Article: Meta-learning a Dynamical Language Model
10. Article: Low-shot Learning with Large-scale Diffusion
11. Article: Meta-learning for Semi-supervised Few-shot Classification
12. Article: Machine Learning in Wireless Sensor Networks: Algorithms, Strategies, and Applications
13. Article: Machine Learning for the Internet of Things Data Analysis: A Survey
14. Article: Matching Networks for One-shot Learning
15. Article: One-shot Learning with a Hierarchical Nonparametric Bayesian Model
16. Article: Metric Learning With Adaptive Density Discrimination
17. Article: Siamese Neural Networks for One-shot Image Recognition
18. Article: A Survey on Metric Learning for Feature Vectors and Structured Data
19. Blog by Thomas Wolf: Meta-learning
20. Blog by Tassilo Klein: Deep Few-shot Learning
21. Blog by Abhinav Khushraj: IoT-based Predictive Maintenance
22. Blog: The Value That IoT Brings
23. Book by Bishop: Pattern Recognition and Machine Learning
25. Article: Imitation Networks: Few-shot Learning of Neural Networks from Scratch
26. Article: Learning to Remeber Rare Events
27. Article: Make SVM Great Again With Siamese Kernel For Few-shot Learning (authors undisclosed)
28. Presentation: WAMP (Web Application Messaging Protocol)
29. Wiki: Anomalies in Statistics. The Definition Given by Wikipedia
30. Article: The Internet Of Things: New Interoperability, Management, and Security Challenges
31. Book: Foundations of Time-Frequency Analysis
32. Wiki: Intro to PID Controllers
34. Web: http://customerthink.com/top-5-surprising-facts-everyone-should-read-about-iot/
36. Blog: Record Evolution Platform
This article is part of a three-piece article series. See Part I and Part II here:
IoT Learning and Predictive Maintenance-I
IoT Learning and Predictive Maintenance-II

Appendix A: Glossary of Terms
This glossary only covers the concepts presented in our argument. This is not an exhaustive account of machine learning in an IoT setting. You can refer to reviews [13],[12], and [8] for a complete picture.
Learning:
- Supervised learning means that the model simply learns previously determined labels to predict labels by looking at examples.
- Unsupervised learning is that there are no labels and we need to create some labels via clustering, etc.
- Semi-supervised learning is deciding on new clusters via existing labeled classes.
- Meta-learning, in a way, is learning to learn. Hyperparameters such as learning rate are guided/leaned apart from parameters such as network connections.
- Few-shot learning: In a classification problem, a dataset can render some classes as relatively under-represented. Learning such classes or clustering a few examples is few-shot learning.
- Zero-shot learning: Zero-shot learning is having an abstract concept of exclusion before an example of a new class is generated.
Computing
- Cloud computing: This is computing in the cloud, or the practice of using a network of remote servers hosted on the Internet to store, manage, and process data, rather than a local server or a personal computer.
- Fog computing pushes intelligence down to the local area network level of network architecture, processing data in a fog node or IoT gateway.
- Edge computing pushes the intelligence, processing power, and communication capabilities of an edge gateway or appliance directly into devices such as programmable automation controllers (PACs).
Algorithms
- Deep Neural Networks: These are based on Artificial Neural Networks but constitute many feedforward layers. So here we have deep ‘hidden’ layers trained by backpropagation of error.
- LSTM: These are networks of long and short-term memory loops provided by synaptic activation variables. Short and Long are relative terms; this separation indicates different time scales.
- SVM: Support Vector Machine (SVM) is a gemometrical method that provides a surface with an optimal Lagrange function to classify or fit curves.
- One Class SVM: This is a special SVM technique for anomaly or outlier detection. It simply creates distance between the origin and the data set so that it classifies new data points as an outlier if they fall relatively far away from the bulk of data.
- PCA: Principal Component Analysis (PCA) is performed by using Singular Value Decomposition of the correlation matrix and thus applying a spectral cut-off to reduce the whole space to principal dimensions.
Data
- Big Data: A data science buzzword that describes the amount of data requiring more than conventional everyday memory and storage resources, such as laptops and hard disks.
- Data Streaming: Publishing data measured by devices to a server.
- Database: A structured set of data held in a server or a computer that is accessible in various ways.
Network
- IoT: The Internet of Things (IoT) is an interconnection, via the internet, of computing devices embedded in common objects to send, receive, and process data.
- Wireless Sensor Networks “are collections of motes.”
- Motes “are the individual computers that work together to form networks.”
- Network Communication Protocols IP, etc. “The protocol defines the rules syntax, semantics and synchronization of communication and possible error recovery methods.”
Applications
- Predictive maintenance: Maintenance modeling based on data.
- Fraud detection: Detection of fraud in trade, bank transactions, or credit card history.
- Business Analytics: Getting insights from data for business modeling.
- Smart: Smart is a tag often used to indicate the implementation of AI.
