
OSeeR: I C What You Did There
Born from altruistic roots to a recent progression into unethical practices
This blog takes you through OCR’s journey from humble beginnings as a Morse code converter, to a globally adopted ‘next-gen’ business tool, used to provide an innovative edge over competitors.
Index
What’s An OCR?☍
Who Do You Think You Are: OCR Edition☍
Software Fights Back☍
Benefits Of OCR ☍
Accessibility ☍
Challenges ☍
Who’s OCR’ing ☍
OCR In The Wild ☍
Bibliography ☍
What‘s An OCR?
Optical Character Recognition or OCR is a piece of software that interprets blobs of colours and shapes in a digital image as text or not — think of it as the patient doing an optician’s eye chart test.

Who Do You Think You Are: OCR Edition
OCR can be traced back as far as 1809 when the first patents were handed out around OCR in research. However, its first physical entity comes around the time of the First World War, sprouting off telegraphy — its earliest ancestor if you like — when physicist Emanuel Goldberg invented a machine that could read characters and convert them into telegraph code. He later used pattern recognition embedded in a photoelectric cell to retrieve information from film where information at the time was stored.¹

Although this machine was revolutionary in its time, it repurposed existing hardware such as movie reels which worked in the short term but was less adequate as time progressed and information began to no longer be stored on film. Step forward inventor David Shepard who developed a Gismo, or rather the Gismo in 1951. This machine translated printed messages into a form understood by machines. Gismo only recognised simple, open fonts and as such Shepard invented a font that met these conditions. Can you guess which font Shepard invented? If you thought, “Comic Sans” then I encourage you to leave, but for the norms, it was the font used on credit cards today.³
These font limitations restricted early machines’ usability as they were only able to interpret select messages. However, in the 1970s, Ray Kurzwell invented omni-font OCR which was capable of processing printed documents in almost any font¹ — keep in mind the number of fonts available at this time were fewer than today, for example, Comic Sans was not developed for another 20 years — how lucky they were!
OCR today is widely adopted and used commercially in a host of sectors including medical, financial and commercial.
Continuing to look at the OCR ancestral family tree, we arrive at its closest cousin, Optical Mark Recognition or OMR. A similar recogniser of physical marks, OMR more simply looks for the presence, or lack of presence, of a mark made from pen ink, pencil graphite or alike. Due to its simplicity OMR predominantly uses hardware scanners to process documents and companies such as DRS specialise in making these. It’s worth noting that it is somewhat moving into the digital era due to the plethora of advantages outlined in this blog.

OCR also recognises the presence of marks but then performs the added task of determining what alphanumeric character that smuggle is. This additional task is far more complex than simply determining whether something is there and as such OCR predominantly uses software. However, earlier adaptations were restricted to using hardware or, when early software was combined with hardware scanners, outperformed its hybrid counterparts as this 1996 article describes.
Software Fights Back
Today, however, software takes back its crown. Machine learning (ML) is such a diverse area of computing that solves a wide spectrum of problems. One of these problems revolves around computer vision and a subset of that, OCR. There are a plethora of clever techniques used to solve this problem some of which are outlined in this blog but the new and cool term is deep-learning. Deep learning can be applied to OCR in what some are calling, ‘next-gen OCR’ like Tim and Abhinav. A relatively new form of this is CapNets.

In addition to raw text extraction, text structure and content awareness pose additional problems. Deep-learning can again be applied to understand document’s structure. This combination of models working in harmony can create very powerful applications for text extraction, combine that with pipelines to automate monotonous tasks and you have a very useful business tool.
Benefits Of OCR
OCR brings many advantages:
- Increased accuracy; documents text are more accurate than those manually transcribed
- Throughput; using computers to transcribe documents rather than humans reduces variation in productivity and quality allowing for more accurate workload estimates to be made
- Automation; digital business models which receive and process data can incorporate OCR into pipelines relatively simply
- Editable documents; documents can be cropped, re-ordered and highlighted to suit users’ needs
- Searchable documents; documents can be stored in huge data warehouses to allow for searching, as you’d see for historical texts
- Accessibility; documents can be made useable for screen readers
Accessibility
OCR’s initial purpose was to provide a service for disadvantaged users; visually impaired: partial to complete blindness or mentally impaired: dyslexia, autism, etc.
Around the same time of Mr. Goldberg’s telegraphy translation invention, scientist Edmund Edward Fournier d’Albe developed the Optophone. This was a device that transformed text into sound to allow deaf people to ‘read’.

In the United States of America alone, an estimated 7,675,600 can be categorised as being visually impaired.⁴ This means that they require use of specialist software known as screen readers to access websites and digital documents or PDFs. The problem with these is that they are not accessible to people with visual difficulties from the get-go. Accessibility has to be added after. To add this, PDFs requires OCR software to ‘read’ the document and produce hidden PDF tags which provide structure to the document for screen readers⁵. These tags — which represent the individual elements on the page — are stored in a hierarchical tree.⁶ There are many different applications that enable these features including Read&Write for Windows and Mac or Google Chrome’s Texthelp Snapverter which uses documents in Google Drive.⁷
WCAG 2.0 Guidelines:
Guideline 1.4.5 “If the technologies being used can achieve the visual presentation, text is used to convey information rather than images of text except for the following: (Level AA)
Customizable: The image of text can be visually customized to the user’s requirements;
Essential: A particular presentation of text is essential to the information being conveyed.” (W3C)
This guideline⁸ states that text from an image should be editable by a user to suit their needs. OCR enables this by enabling software to perform a whole host of features including:
- Text highlighting
- Text colour and font changing and resizing
- Ability to use digital dictionaries, thesauruses and translators
These features amongst others other can help in use-cases such as individuals with dyslexia as this article explains.
Challenges
The ability to detect text on a page can, of course, be influenced extensively by the quality of the page in which it is trying to be read. Creases, smudges and tears can make it more challenging for us to read information from a page and when this is fed into a computer system these difficulties can be amplified, not to mention the issues of blurs, flashes, rotations, etc added when you scan them.
The previous examples of OCR processing focussed only on raw text extraction, however for many documents the text present has no meaning without context. Think of your driving licence, it has fields against which your details are stored. This relationship between field and value is lost with brute-force OCR and as such the document type needs to be considered to derive value from it. This classification of document type requires a further form of ML.⁹ However, this has problems, many of which are outlined in this article.

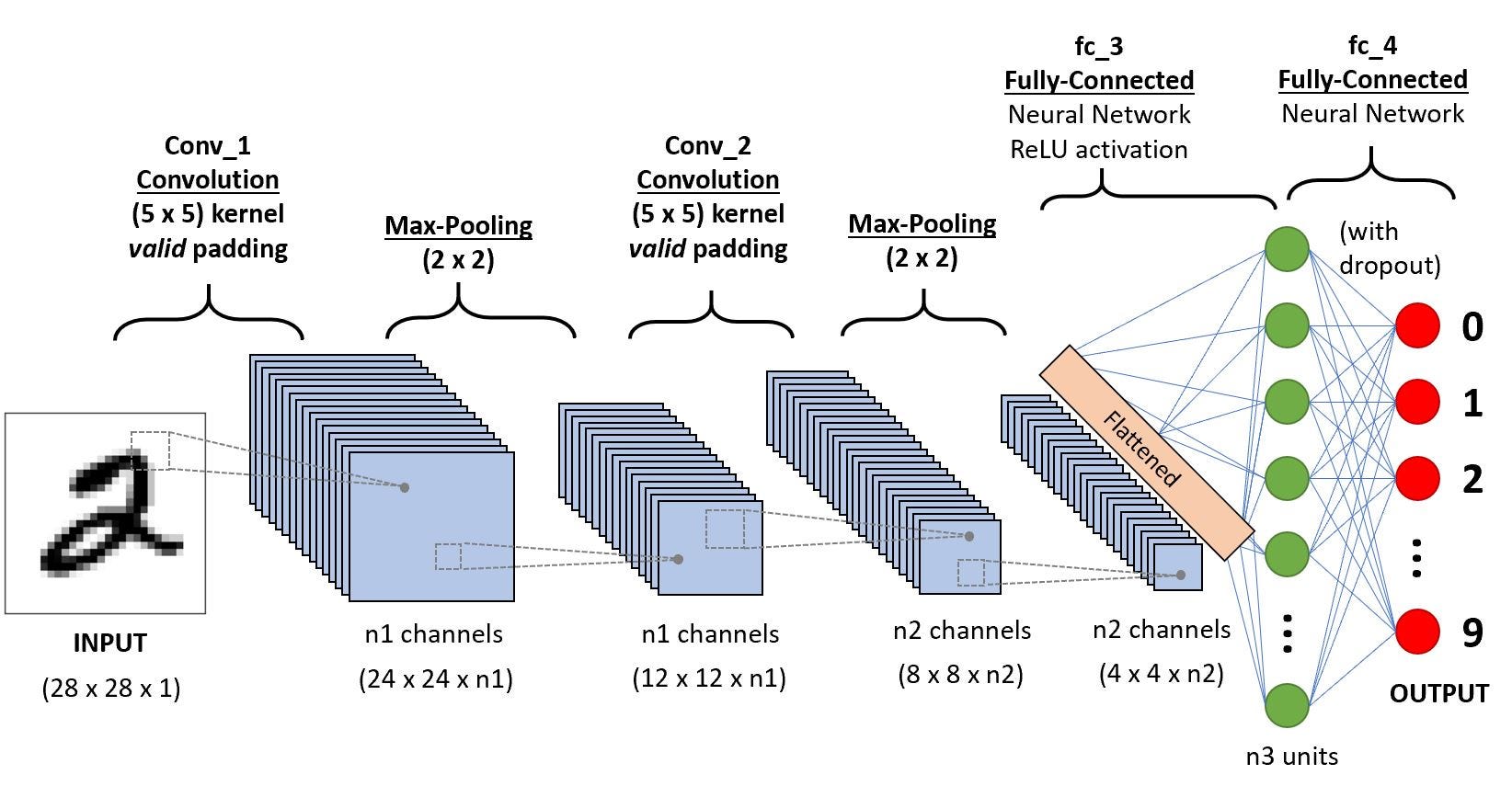
One stumbling block for translators, however, has always been handwriting. ML techniques have produced fantastic results on the MNIST dataset (single digit handwritten letters) with Convolution Neural Network (CNN) being notable. This blog provides more details on this. However, thinking of handwriting as words, sentences and paragraphs this idea of modelling it as merely individual letters is naïve; developing a model capable of detecting handwriting in all forms, is extremely difficult.
The issues defined above highlight that attaining 100% accurate transcriptions is unreasonable and near impossible even with the advances in ML. However, there are online communities who scan, alter and upload corrected translation documents for others to use to online libraries. Libraries such as Bookshare and Learning Ally contain accessible documents and audio books.
Who’s OCR’ing?
There are many different OCR services on offer today.



Abbyy’s FineReader provides a hardcore OCR engine built on Azure’s architecture, ample features suited for business uses and a mobile equivalence. In addition to a desktop application, they also provide a cloud solution which is accessed through an SDK. The software performs well in this comparison article, however, the service is costly at roughly 7 pence per page.
The offerings from Microsoft, Google and Amazon rectify this expense barrier with cost-effective cloud-based solutions interacted with via SDKs and API calls, costing a fraction of a pence per transaction. These solutions also provide text location within an image in pixels and relationship between text, e.g. line, word, letter. Amazon’s Textract also provides relationships in forms and invoices between text field and value. The performance of these services differ significantly and if you’d like to these 3 titans go head-to-head-to-head in a performance showdown, then check out my other blog!
Tesseract (from Google) and Kraken (a nice wrapper for OCRopus) provide some open-sauciness into the mix. These packages require more development to integrate them with a system. For an in-depth comparison analysis check out this blog.
OCR In The Wild
Within the medical sector, OCR is used to transform patient documents and invoices to digital copies in order to comply with HIPAA protocols but also with the overall goal of being totally paperless. In addition, these digital documents can be shared with other personnel but they are also compatible to communicate with robotic process automation platforms.¹⁰
This GitHub repository provides a stripped down version of Abbyy’s FineReader to extract tabular data from documents.
Digitising historical paper documents allow for them to be searchable.

In 2011 approximately 1,700 ports globally installed OCR software to automate process and manage shipping containers’ conditions.
Circling back to accessibility, OCR can be used to test mobile applications during their ever-decreasing release times, and subsequent user-acceptance testing phase.
OCR is also used to scan voucher codes, meter readings and hotel check-ins or festival ticket scanning.

Licence plate recognition is one of the most widely adopted use of OCR, scanning millions of cars per month.
The criminal prevention department has jumped on board with utilising it but there is a concern with data retention policies and unethical data sharing.
This use extends into other sectors with fast-food restaurants looking to create custom menus for returning customers and keep card information for ‘leave your wallet at home’ payment.

Mathematical and scientific equations and notation can be extracted using this GitHub repository.
For more OCR related software and literature, check out this repository.

If you’re interested in reading up on all things techy from virtual immersion to quantum computing check out the Applied Innovation team’s series of blogs!

{kind=link}