You might have participated in some Kaggle competitions where the dataset was in…
A few weeks ago I was one of over 40,000 people who descended upon Dublin to be part of the Web…
Cleaning real life textual data is hard. Weather it’s convention inconsistencies, manual data entry mistakes, or a myriad of other reasons, reaching a consistent representation is essential. This…
The performance of a trained classification model can be measured in several ways. Accuracy is one important aspect that is…
As a data science startup, we write a lot of R scripts. Since we often work with very large amounts of data, our R scripts usually have high CPU and Memory usage. Moreover, these R scripts may take hours or even days to finish. It doesn’t, therefore, make sense to run them on our…
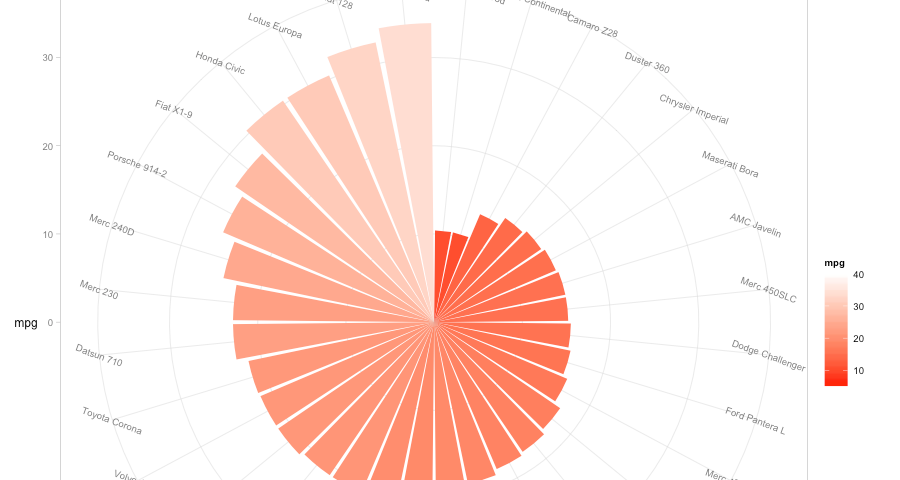
dplyr is awesome, like really awesome. The thing I like most about it is how readable it makes data processing code look. In short, there are two primary aspects that make dplyr great for readability (in addition to it’s great performance, data back-end agnosticism, and…
Say you are on your R console, writing some R code that will conquer the world! Let’s say you reached the point where you want to check the non-existence of the…
A typical process for training a supervised learning model looks like this: