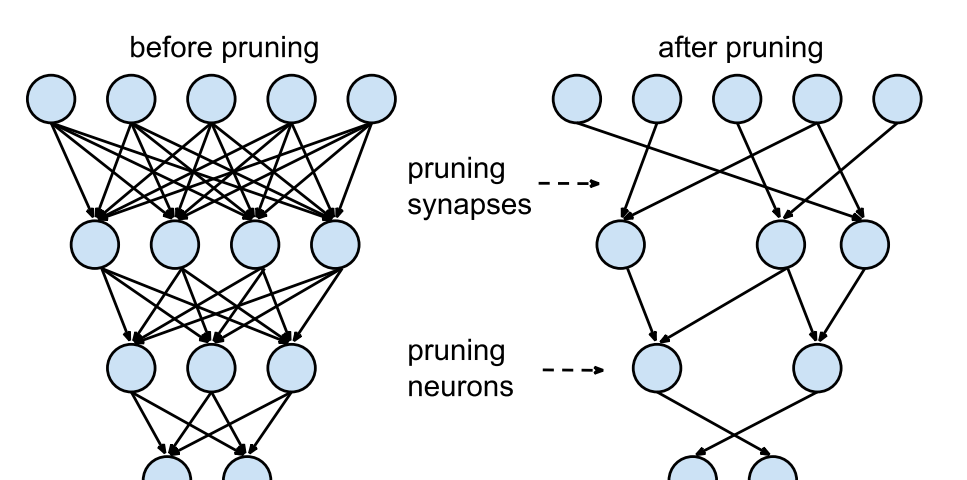
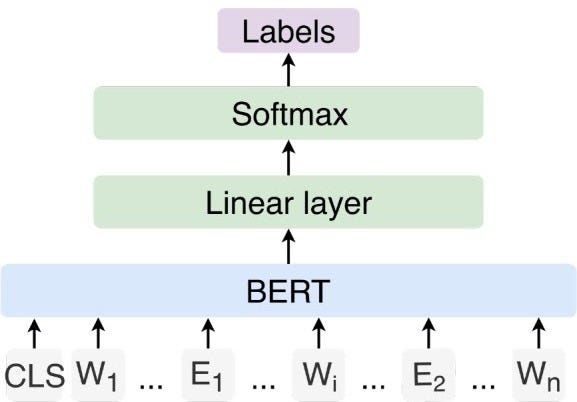
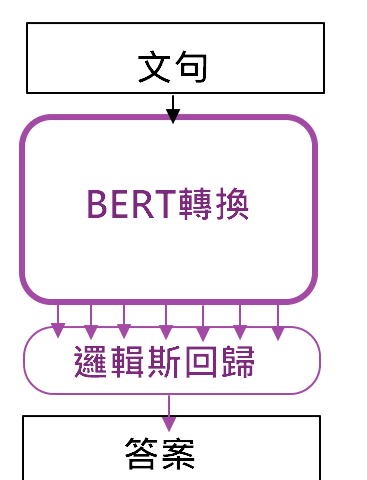
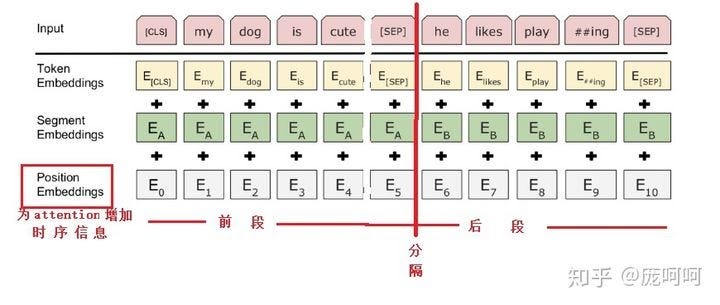
Bert之後,相關的模型可說是百花齊放,以下就會介紹主要的發展方向。
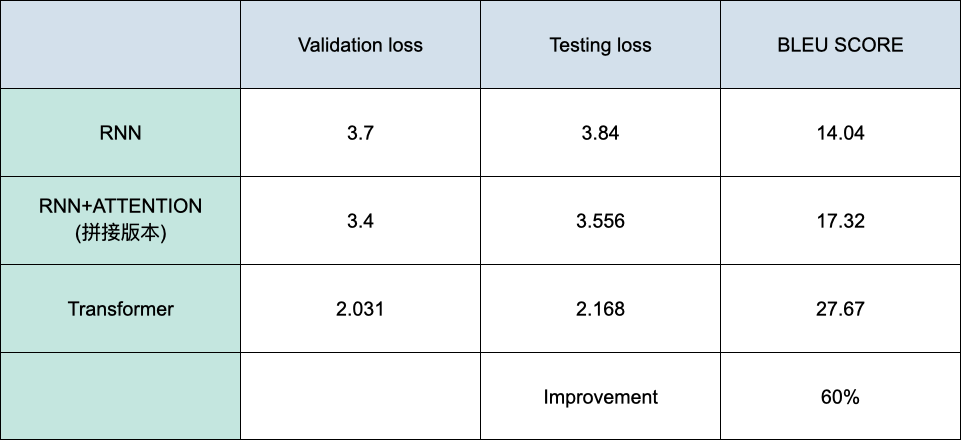
NLP 模型的應用上有兩大目標:改善預測指標以及計算速度,但很難同時達到,在Bert後的研究中,XLNet 和 RoBERTa 改善了性能,而 DistilBERT 提高了推理速度,會在本文介紹。
前面一章我們提到的 ELMo,於 2018 年上半年由獨立的研究團隊提出後,在 NLP 領域原本就有相當完整的研發與技術能量的 Google 團隊,馬上就將 ELMo 的預訓練結合原有的…
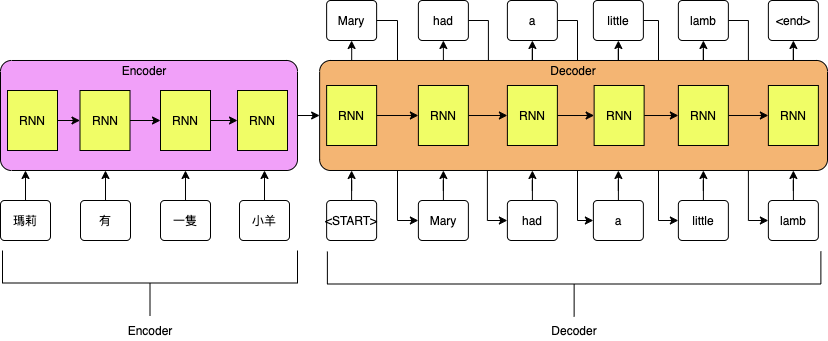
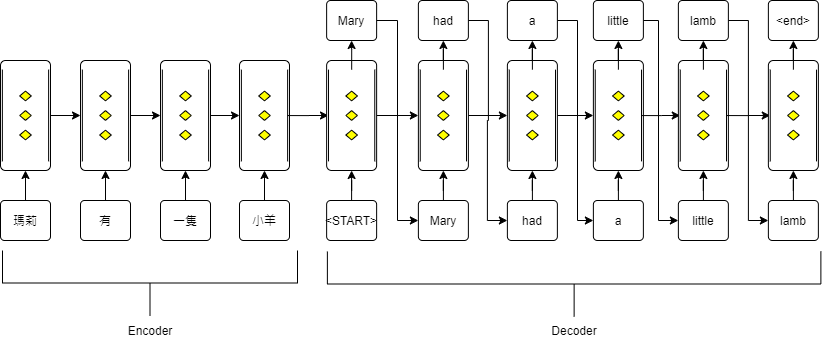
RNN 主要應用在序列數據資料的場景。尤其是自然語言處理的領域,如語言模型及機器翻譯等。 RNN 還可以對具有固定周期特徵的數據建立預測模型。
Transformer就是個 seq 2 seq model,將一個序列轉成另一個序列,就像是變壓器將一個電流轉成另一個電流。
注意力機制(Attention mechanism)跟下一章節會介紹到的Transformer都是NLP發展過程中很具有影響力的元素,而注意力機制(Attention…
之前的提到的SimplyRNN、RNN+LSTM、RNN+GRU都是單向遞迴神經網路,也就是說再預測字詞的模型中,神經網路只會考慮上文,並不會上下文同時考慮進去。