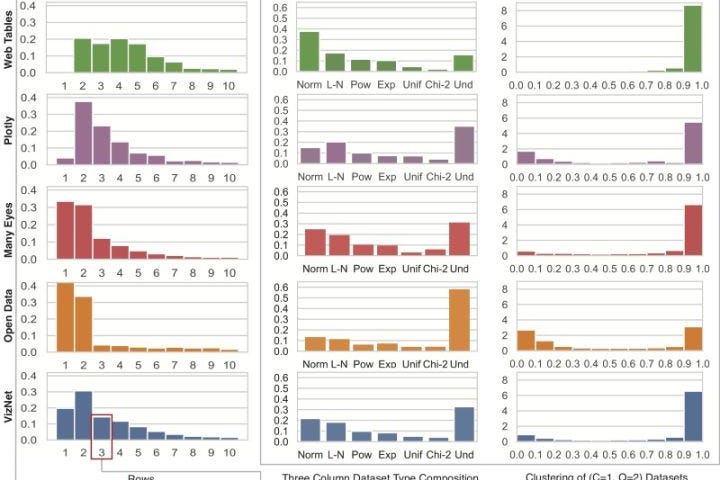
中文词向量可视化流程
文本,尤其是中文文本,是一个高度抽象的对象,极为复杂且难以量化,这对大数据分析中发现文本中的关联性造成了阻碍,也是挖掘文本大数据中潜在价值所必须跨越的难题。而中文文本的可视化可以使普通人也能通过简单的交互体验从而发现文本中蕴藏的价值。本文结合互联网以及论文上相关知识,总结了一下中文文本可视化的一套可行方案与实施流程,共勉学习。
与英文文本不同,在进行文本处理的第一步时不得不面对的是中文文本分词技术,所谓分词是将完整的句子划分成若干独立的词汇。比如“我喜欢你“会被分词为“我”“喜欢”“你”。常采用的中文分词库为jieba,可以有效通过几种模式(最大概率法、隐式马尔…