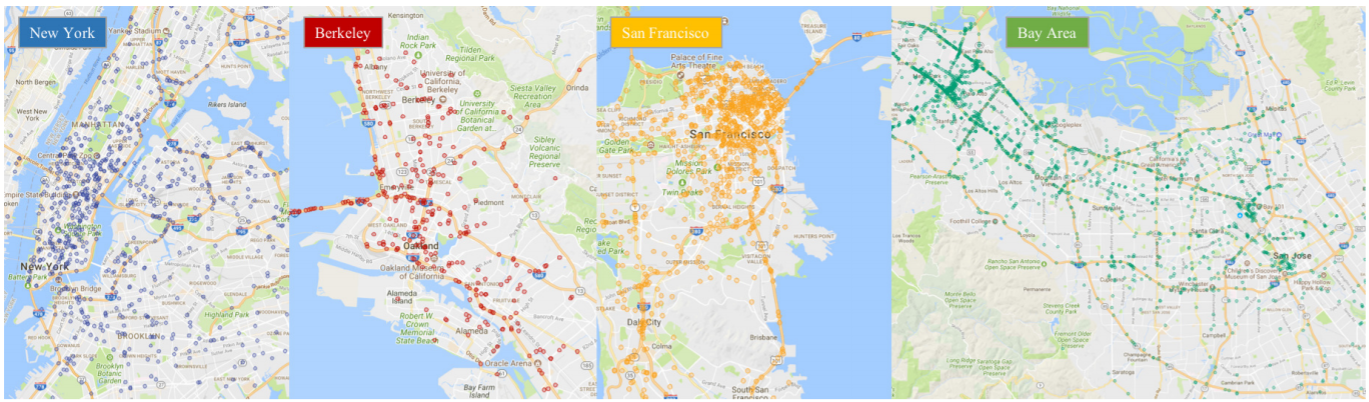
UC Berkeley釋出於2018年,目前來說最大規模也是最多樣化的駕駛視訊資料集,可評估自動駕駛圖像識別算法,具有地理,環境和天氣多樣性。這些資料具有四個主要特徵:大規模,多樣化,在真實的街道採集,並帶有時間資訊。
超參數調校順序,依吳恩達所建議,排列如下:
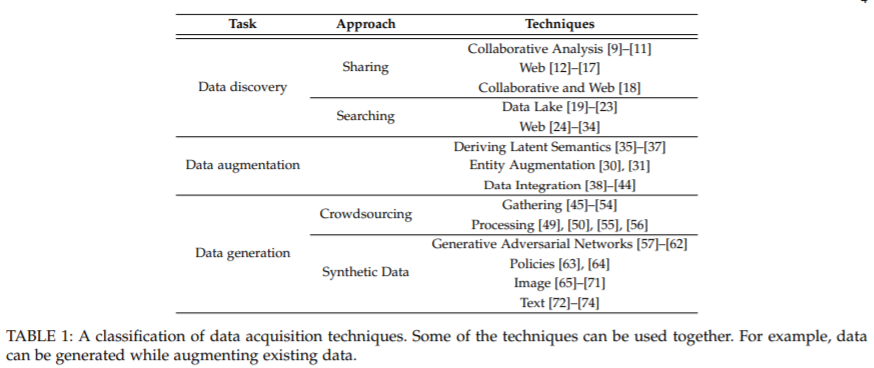
為了找到可用於訓練機器學習模型的數據集,主要有三種方法:
現在自學方式很多,以下是我覺得比較好的方式。
監督式機器學習(Supervised learning)是從已被標記的數據中學習。程序員不寫具體演算法來制定決策,而是對 "從標記數據中學習的模型"…
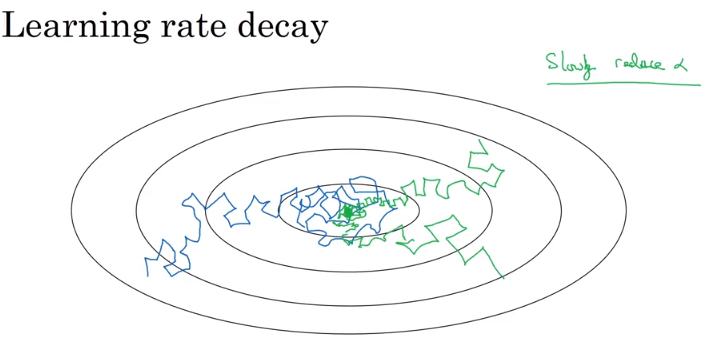
學習率衰減 (learning rate decay):簡言之,就是隨著時間慢慢降低訓練的學習率。
讀書會進行方式
由LeCun在1998年提出,來辨識手寫數字。 它定出CNN最基本的架構:卷積層(Convolution)、池化層(pooling)、全連接層( fully connected layers)。可參考此文了解更多。
現在常用的LeNet-5(5表示有5個層),和原始的不同在於:
這是為了預習學校此周的課程,學習吳恩達老師的序列模型心得,亦參考他人學習心得而做的筆記。
遞歸神經網絡或RNN這樣的模型,在 語音識別/音樂生成/DNA序列分析 非常有用。 這些問題都可視為監督式學習,但輸入x和輸出y不一定都是序列模型。若都是序列模型的話,模型長度也不一定完全一致。