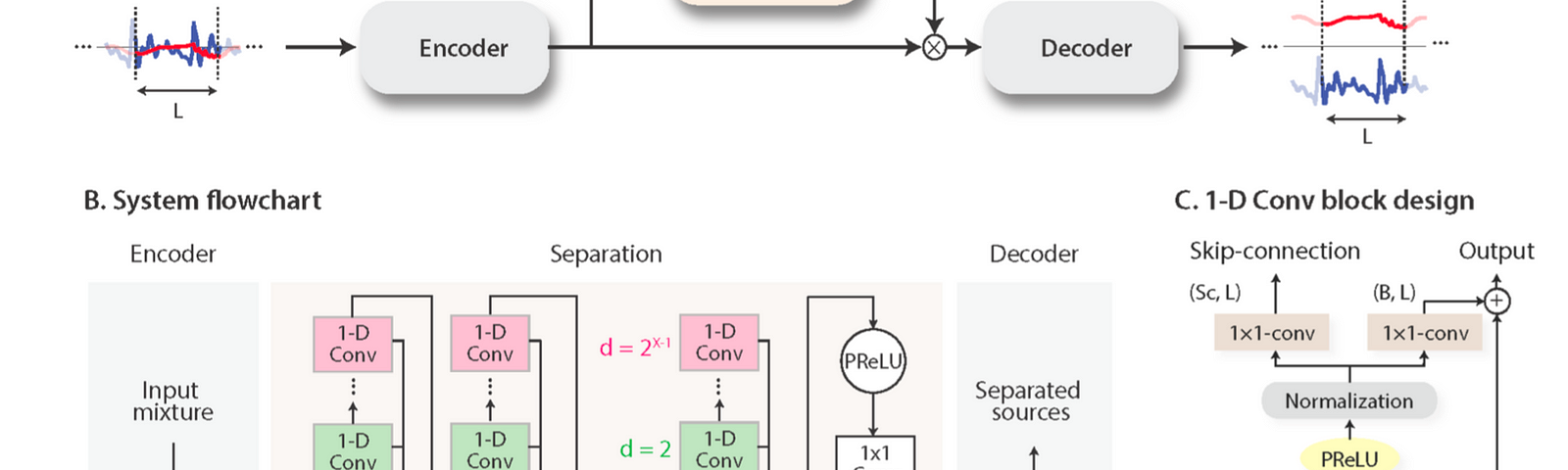
由 Nima & Yi Luo 在2017年左右提出的全新深度學習框架,應用處理於語音分離(語者分群)的議題。
本篇論文 通過在語音訊號的高維嵌入空間中(Embedding Space)創建吸引點(Attractor Points)來提出用於單聲道語音分離的新型深度學習框架,其對應於每個聲源的T-F bins合在一起(類似聚類但又不是)。
由Google團隊及其科學研究者Quan Wang所發布:VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking. 透過聲紋辨識技術的輔助,來提升人聲(語音)分離的效能。
此篇由IEEE Fellow, DeLiang Wang撰寫。
本文僅擷取部分我認為重要的部分,並參照其論文的Reference,附加於文末
Speech Separation 語音分離已經是一個被議論許久的議題,更是語音領域最具有挑戰性的領域,其應用涉及非常廣,Speech Enhancement, Speaker…