除了深度學習,也想再從機器學習相關的理論和實作中繼續深入,有些概念背後其實兩者是相通的。因此開啟這個系列,未來也會分享更多的模型和實作給大家。
承接筆記(1),原文為[1]。繼續整理論文的下半部分。
回顧一下目前為止在「二元分類」任務上,為了讓模型學得更好,有做過哪些調整:
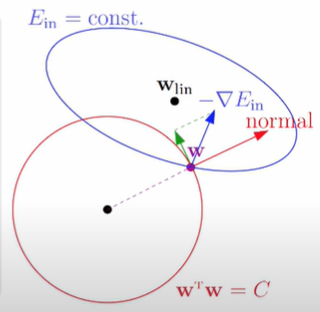
這裡的正規化(regularization)講的是針對模型的,是指在一票可以解決同一個問題的模型中找到最佳解。前面在介紹過度配適、非線性轉換時提到使用高次多項式,將資料投射到更高的維度可能可以解決問題,但隨之而來的模型複雜度有可能造成過度配適。因此挑選…
系列的第10篇,算是一個里程碑。本系列預計最後總共會有12~13篇。然後也可以來試試看自己根據數學式實作看看,之後有空的話會接在這個系列後面補完。
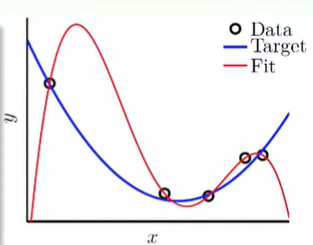
前面的系列文,討論的基本上是「資料線性可分」的大前提。意思是說資料基本上線性可分;即使有一些資料無法線性可分,那也可以當作雜訊,或者是誤差來處理,在最後歸納的分類上,是可以做出線性分割的趨勢的。
在本篇中,我們要來利用前面幾篇介紹過的線性模型解決分類問題。這些模型分別是:
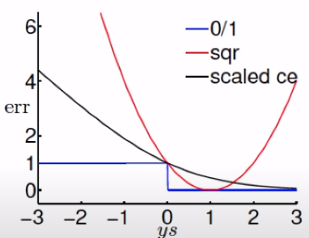
這篇是討論機器學習基石裡面舉的第二個線性模型 — 羅吉斯回歸(logistic…
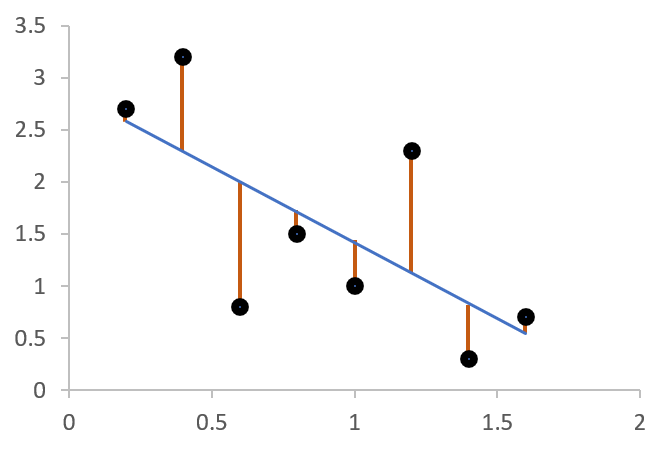
從本篇開始會陸續介紹幾個演算法,或許大家都耳熟能詳,甚至可以說是統計相關的基礎方法。不過,這次要從機器學習的角度來看它們。首先登場的是線性回歸。