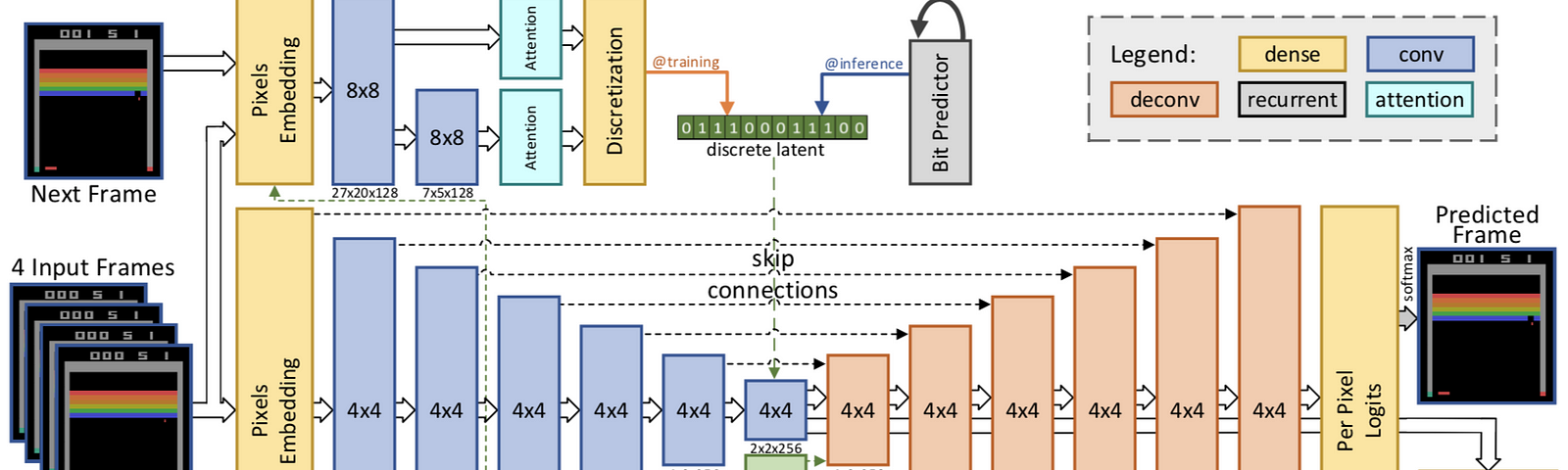
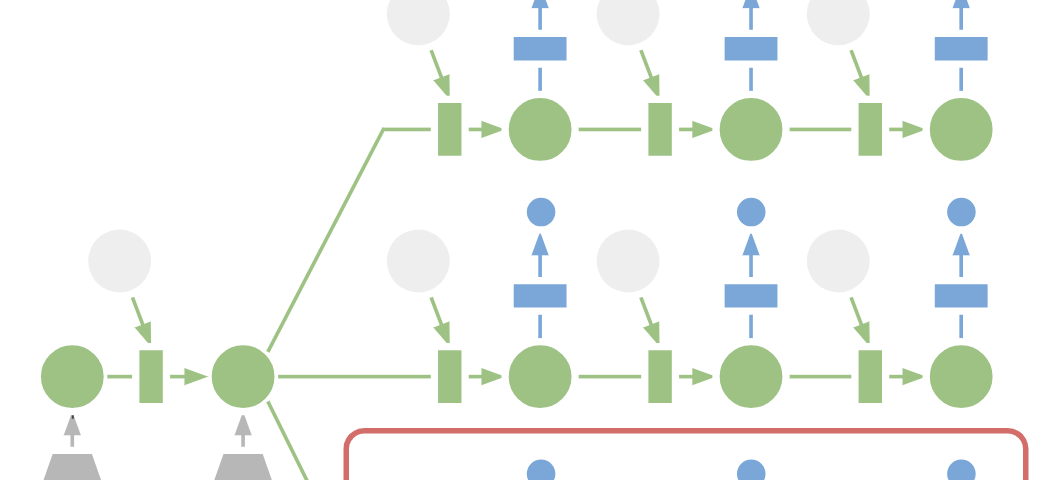
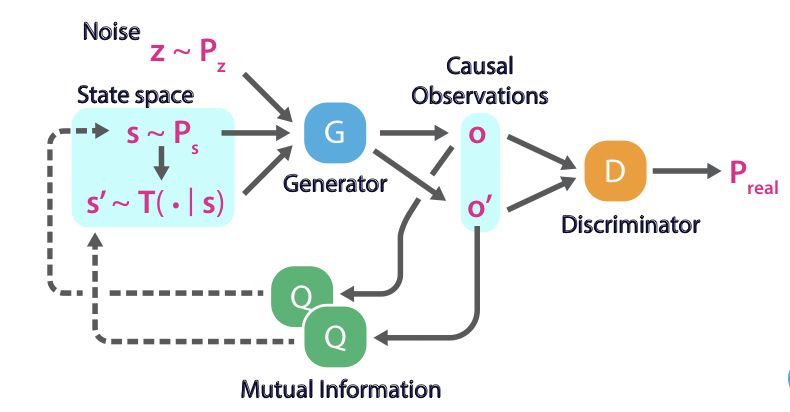
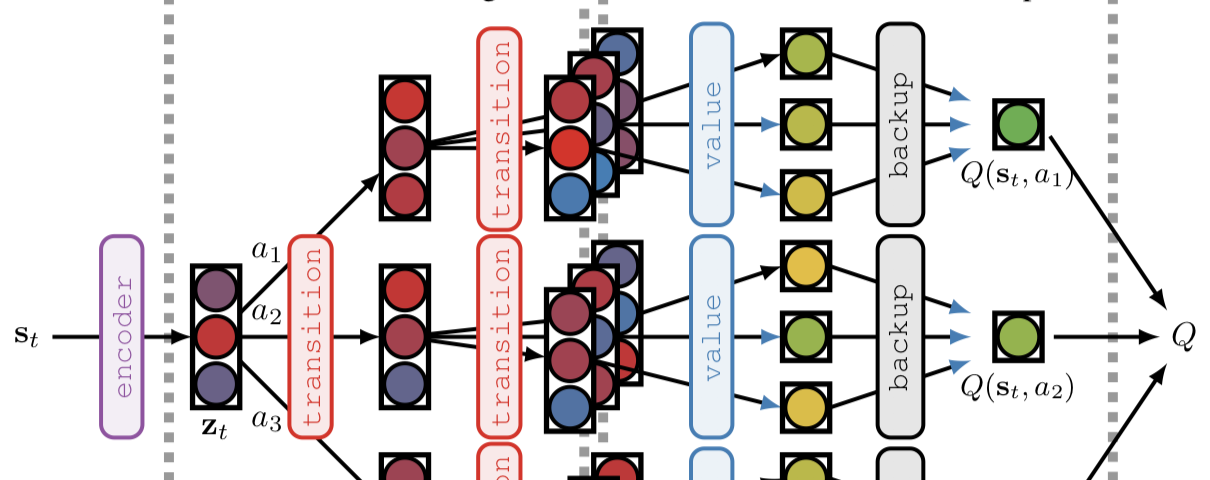
Summary: Conservative Policy Iteration
Conservative Policy Iteration has 3 goals: (1) an iterative procedure guaranteed to improve a performance metric, (2) terminate in a “small” number of steps, and (3) find an “approximate” optimal policy. These three goals are hit by relying on a few assumptions…