Ideas from this summary are taken from the Prioritized Experience Replay Paper.
One of the core issues in Reinforcement Learning is sample complexity. Therefore it’s appealing to train RL agents in a…
Ideas from this summary are taken from the Proximal Policy Optimization paper.
PPO offers two key improvements to policy gradient methods:
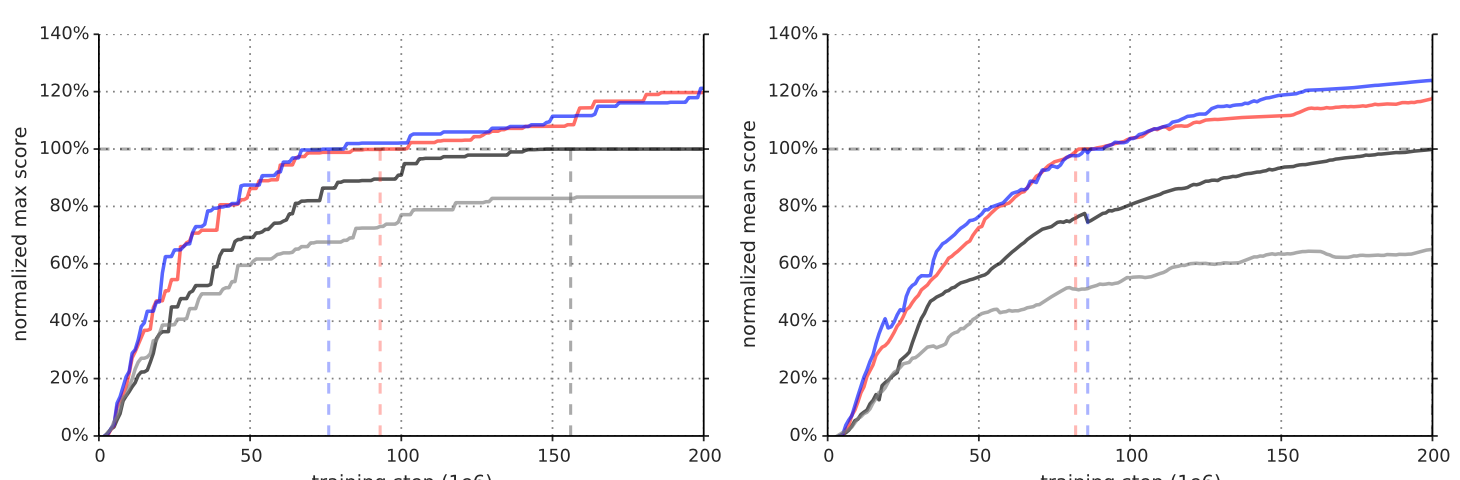
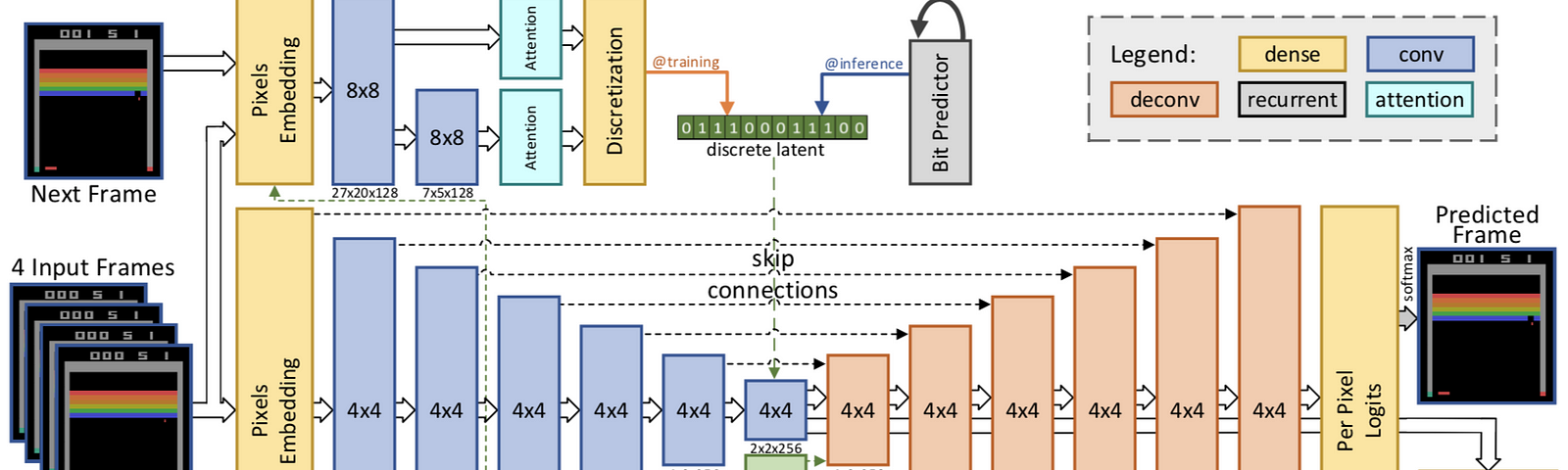
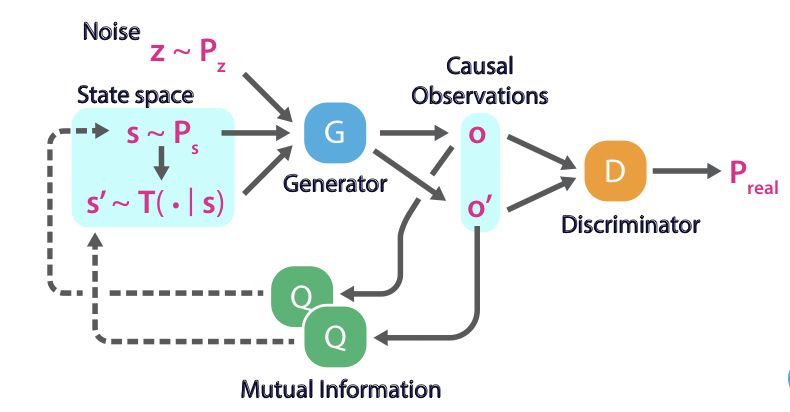
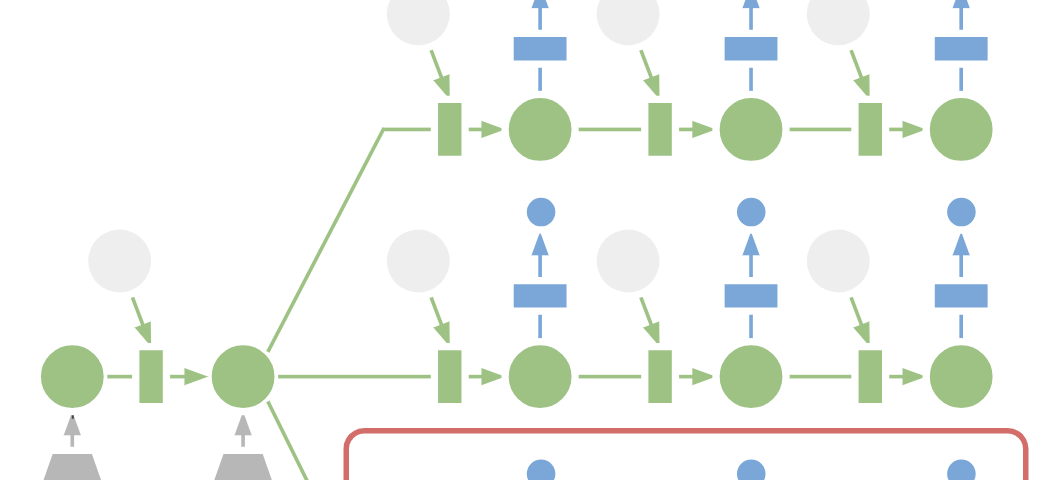
Ideas and figures from this summary are taken from Model-Based Reinforcement Learning for Atari(SimPLe).
This post is a summary of Continuous Control With Deep Reinforcement Learning.
This basic goal of this paper was to transfer the success from deep Q learning achieved in discrete action domain to a continuous action domain. In…
Conservative Policy Iteration has 3 goals: (1) an iterative procedure guaranteed to improve a performance metric, (2) terminate in a “small” number of steps, and (3) find an “approximate” optimal policy. These three goals are hit by relying on a few assumptions…
Deep Planning Network (PlaNet), is a model-based agent that learns a latent state dynamics model from images and takes actions…
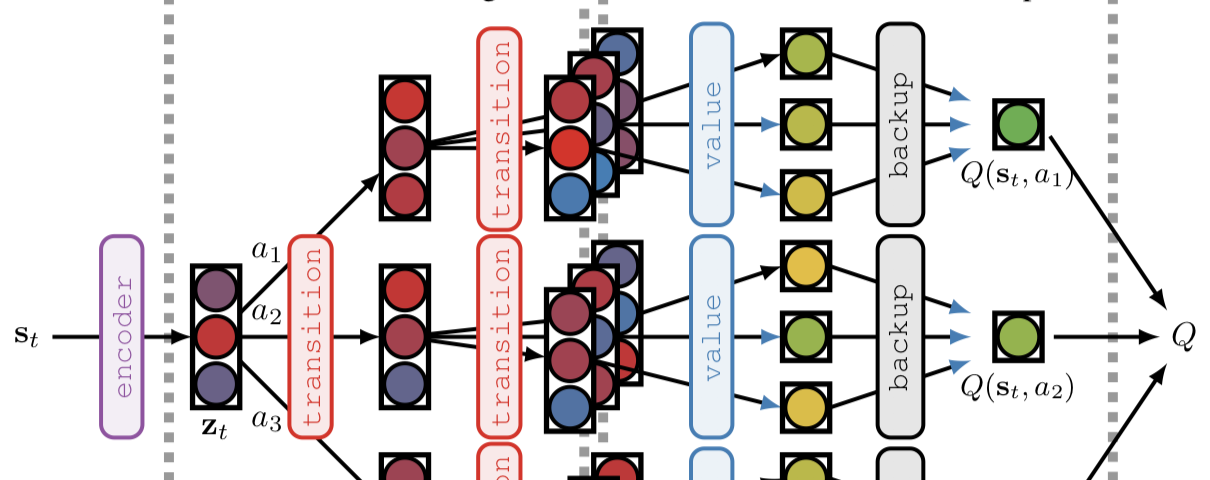
Ideas from this summary are taken from the TreeQN and ATreeC paper.
VPN is a deep reinforcement learning architecture that mixes ideas from both model free and model based methods. Generally model based methods learn environment dynamics so as to predict real observations, however, VPN attempts to learn a dynamics model that…
These were the top 10 stories published by Arxiv Bytes; you can also dive into yearly archives: 2017, 2018, 2019, and 2020.