performance counter 和logman 都是Microsoft 上收集系統效能計數器的方式, 只是logman 是命令行,performance counter 是UI, 2個的效用相同, 用performance counter 也可以收集, 需要逐一的點選。
報錯和緩慢, 是用戶最經常抱怨的問題。
利用大數據分析,提升維運服務品質
用戶響應速度緩慢, 是常見效能問題的症狀。
效能問題, 不是一個單純一個工具就可以解決的問題!更不要期待找一個武林高手來解決一切, 從此江湖就此平靜了,沒有風波了。
統一收集iT 系統的運行日誌、通過大數據分析、交叉比對,預先告訴現場工作人員,哪些系統可能快要故障,可早一步進行檢修。
即使系統真的發生故障,工程師也不用花費大把時間去撈數據,而可以把心力放在分析數據、判斷問題、尋求解方。
全世界server 平均200多天,才發現有人到此一遊。不知道被入侵, 不知道retry 多久了。
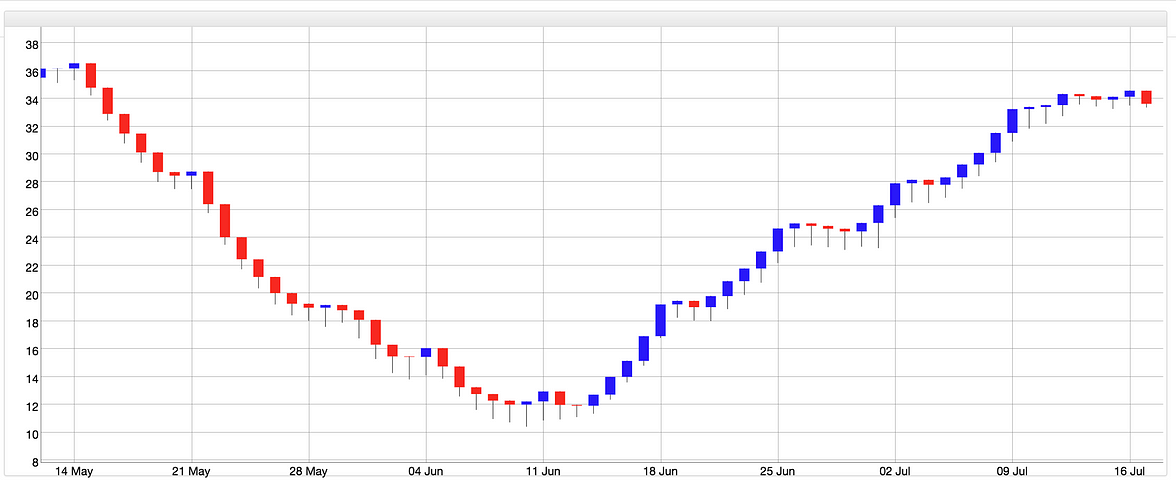
Disk_D 容量,從36GB, 容量一路持續下降, 最低點到達10GB,在6月11日後, 開始持續上升,回到34GB, 這個是三個月的磁碟負載模型。這個圖和股票的K 線圖, 就有點相似了, 如果再加上7日平均值和30日平均值, 就更像了。
再持續觀察3個月,看磁碟容量的變化。