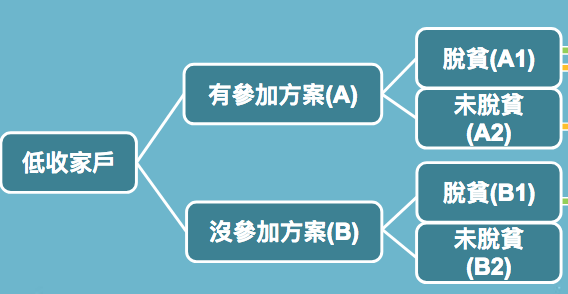
在現有的低收家戶資料中,有參加方案的實驗組(A)以及沒有參加方案的對照組(B),均有一定比例的家戶脫貧(A1, B1)。而此專案的主要目的之一是欲藉著資料的分析,找出未來適合參與脫貧方案的家戶,把資源做更有效地分配,讓更多家庭有機會脫離貧窮。
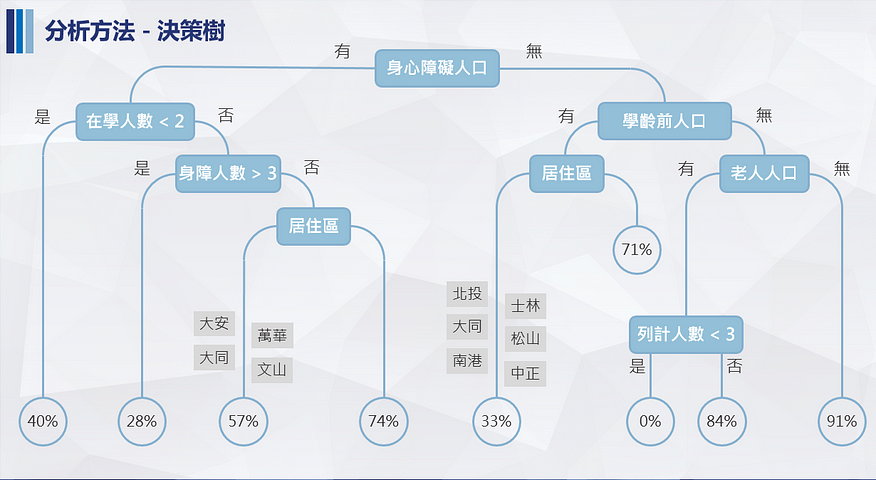
將資料屬性由多個決策點區分成數個群組,目標使群組內樣本的應變數盡量相同,藉由決策樹的路徑觀察各屬性與應變數的關聯,並達到預測的效果。
社會局社會救助科作為提案單位,其中面臨的一個業務困境就是:每年花費很多資源和人力執行各種脫貧方案,但這些方案的成效難以評估。不管有無參加方案,這些家戶中都有一定比例可以脫貧,要如何得知這是方案的效果還是其他原因造成的,也就是方案是否能真正幫助到中低收入家戶改善他們的生活水平?
資料清理(Data Cleaning)指的是一個檢測資料品質的過程,在這個過程中去檢查、校正、轉換,甚至移除錯誤資料。資料清理不僅僅是一個修正錯誤的過程,同時它也是在確保資料的一致性,避免不同的資料科學家在分析的過程中使用到不同的資料,進而導致結果的分歧。
一開始提案單位所提供的原始資料集是從資料庫中的不同的資料表所撈出來的系統資料,而系統資料有可能會因為當初設計時沒有驗證使用者輸入的資料,抑或是沒有強制要求輸入時一定要填行政流程中的必填欄位,導致原始資料集中會有重複資料、資料缺陷及格式錯誤等等的問題。另外,再依據分析的過程中的需要進行資料格式的轉…
台北市社會局推行多個項目希望能幫助更多中低收入戶脫貧,此次針對定期儲蓄型項目作資料分析研究,透過資料英雄成員三個月的協作努力,在此分享模型及處理資料的技術及技巧。
台北市社會局提供參加定期儲蓄型方案去識別化的家庭特徵及未參加方案去識別化的家庭特徵,資料英雄嘗試回答 1. 參加方案且脫貧者具何種家庭特徵。2.成功脫貧家戶有何家庭特徵