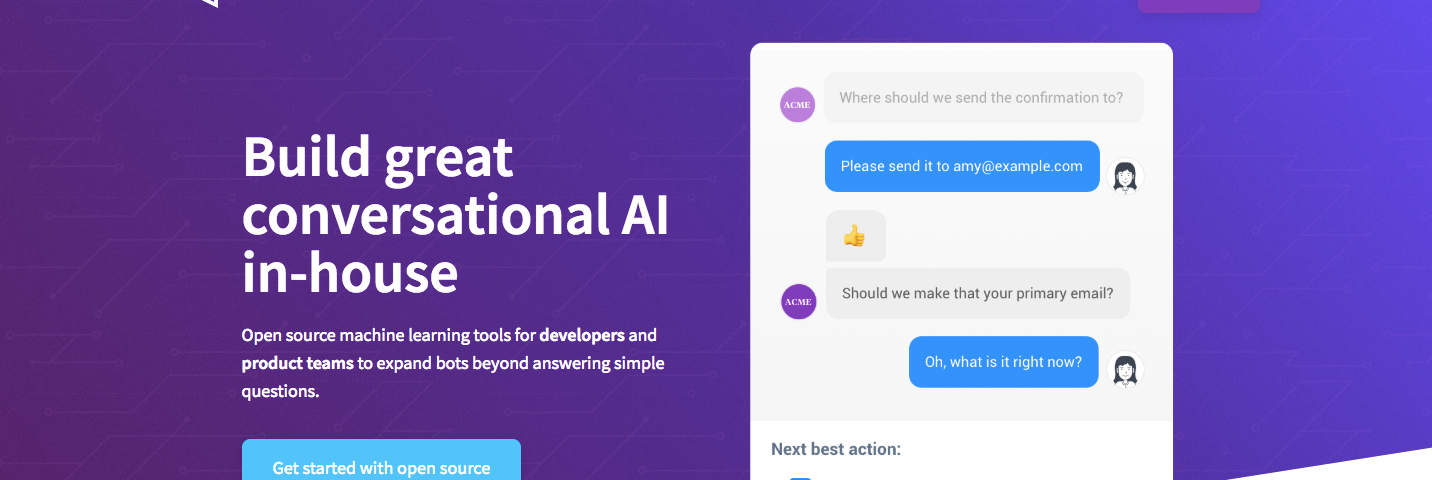
從以前研究所到職場,其實會發現,資料科學所需要能力非常多, 從ETL至Model驗證等都必須都要有概念。尤其是資料科學同好,一定有看過以下Data Science能力圖:
這邊寫下之前讀到的筆記,基本上資料來源是李弘毅老師的投影片 Structured Learning: Sequence Labeling
最近因為業務需求,開始研究一些 open source…
之前因緣際會了解了Google有出Data Engineer的證照,之後就邊上班邊準備GCP的Data Engineer證照,也很開心的最後有考上這個證照。在這邊就稍微分享一下準備的心得。
原本就想說如果考過的話,要發一篇心得文,可惜第一次考GG了…….所以拖到現在,今年五月決定要來考這張證照,和幾個朋友一起看coursera的課程一起討論,當初只是想說是google開課的,內容應該會涵蓋大部分的考試範圍,課程在練習的lab有時候會提供免費的帳號讓你可以實作,但越上到後面的課程,越覺得課程講的真的是很基本,如果已經有相關經驗其實可以不用看這系列課程,而且還有一大部分的時間在教你如何使用GCP的服務。
工作一段時間後,也慢慢體會到職場有許多難處,常常會思考目前公司的產品是否符合消費者的需求,還是只是一群工程師閉門造車的自High產物。
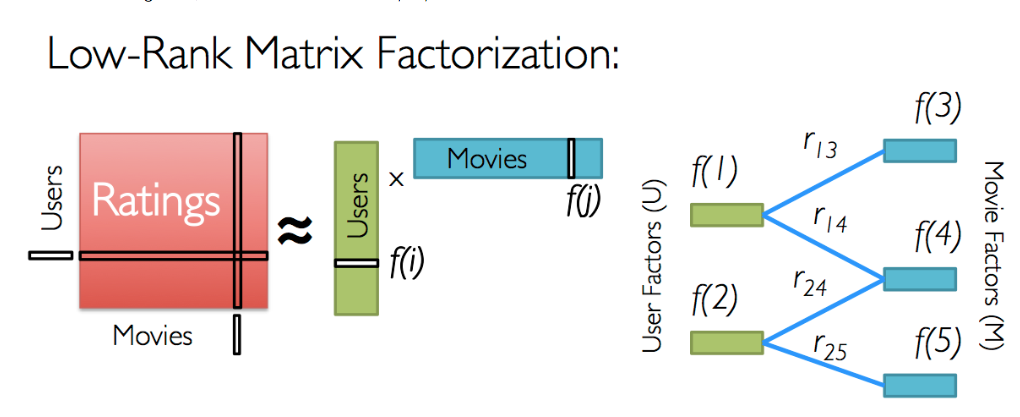
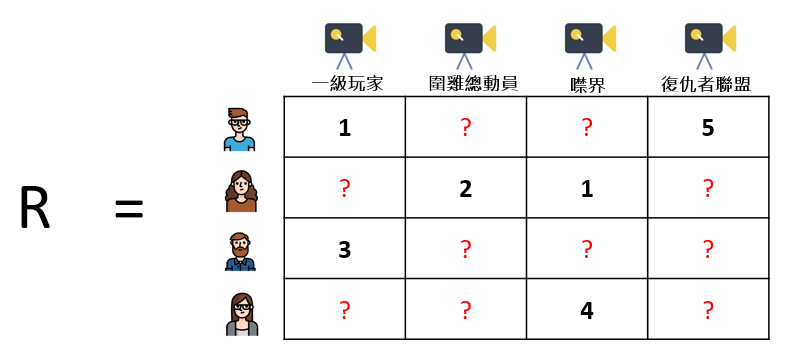
在Netflix大賽後,基於矩陣分解的推薦系統被大家所開始研究並優化,且此方法能補足過去近鄰推薦的一些問題。像是推薦系統中的item之間存在相關性,當item增加,訊息量不會隨著item增加而線性增加。
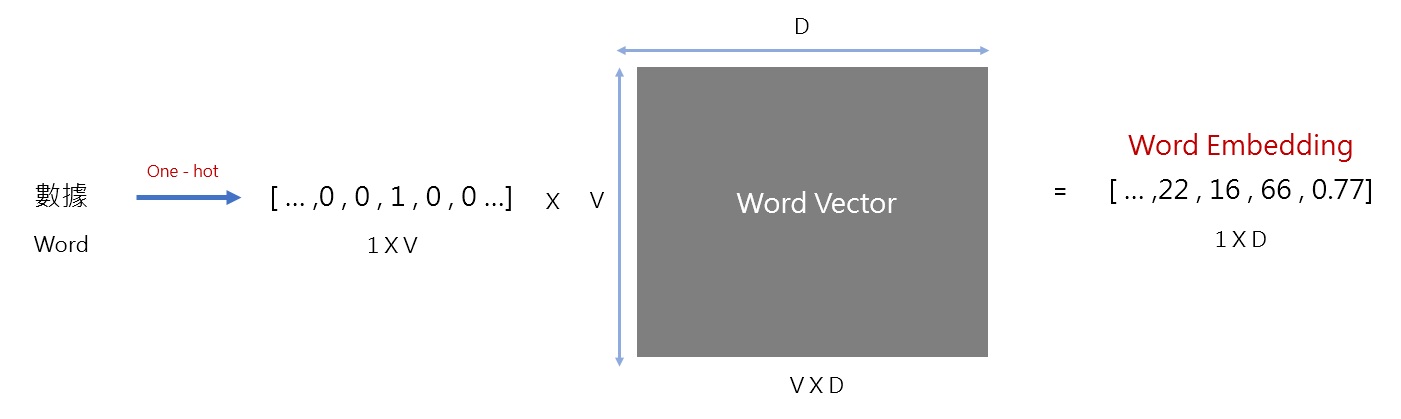
Word embedding (Word vector)是近年來文字探勘非常熱門的技術,主要是用來將文字轉換成向量,透過向量化可進行大量運算。