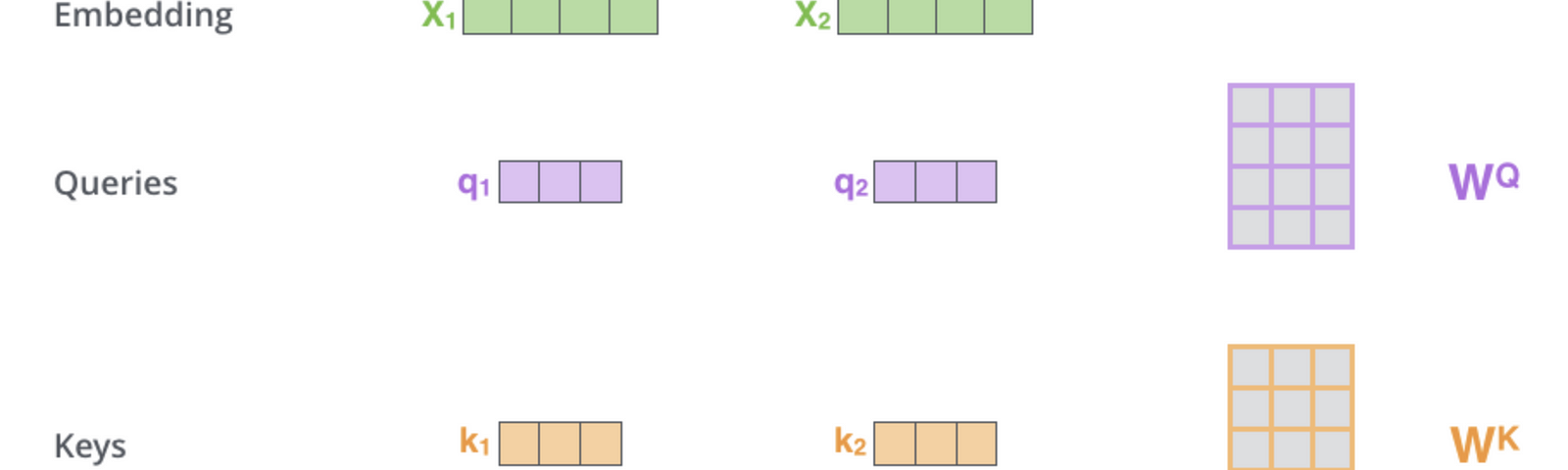
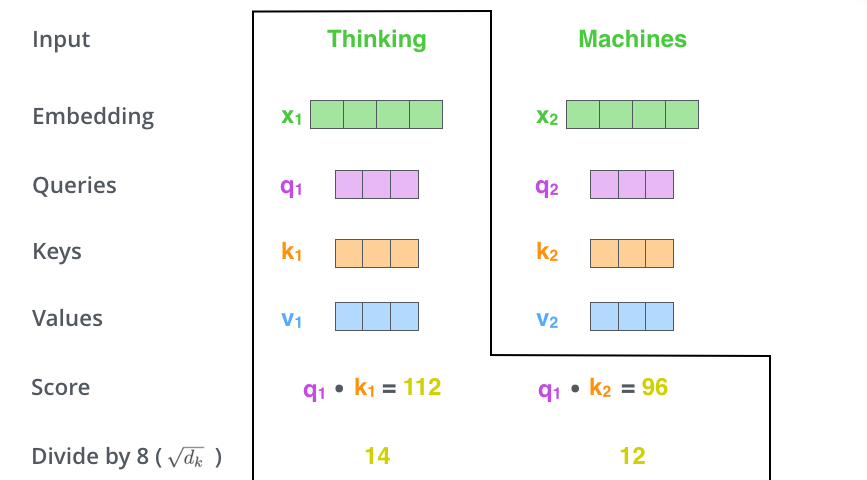
Transformer裡的Attention矩陣運算, 額外的mask操作可以看另外的兩篇文章
這篇會介紹用的 nn model, 主要思考方向是用 CNN 先處理過圖片, 再用CNN得到的feature 做後續處理, 在這部分我用了三個不同的方法, 包含 Lstm 和Transformer, 最後使用 CTC 的方始訓練, 如果對 CTC 不了解的可以先去參考
這裏記錄下驗證碼辨識的實作過程, 這裏先簡單敘述一下目標任務
此任務會輸入一張固定大小的彩色圖片, 圖片大小為(120,60), 裡面有1~3碼, 每碼都是小寫英文字, 顏色和旋轉不固定, 並且有雜點, 以下為範例圖片
可以看到就算同樣都是u 也有不同的顏色和旋轉, 字母位置也不是那麼固定
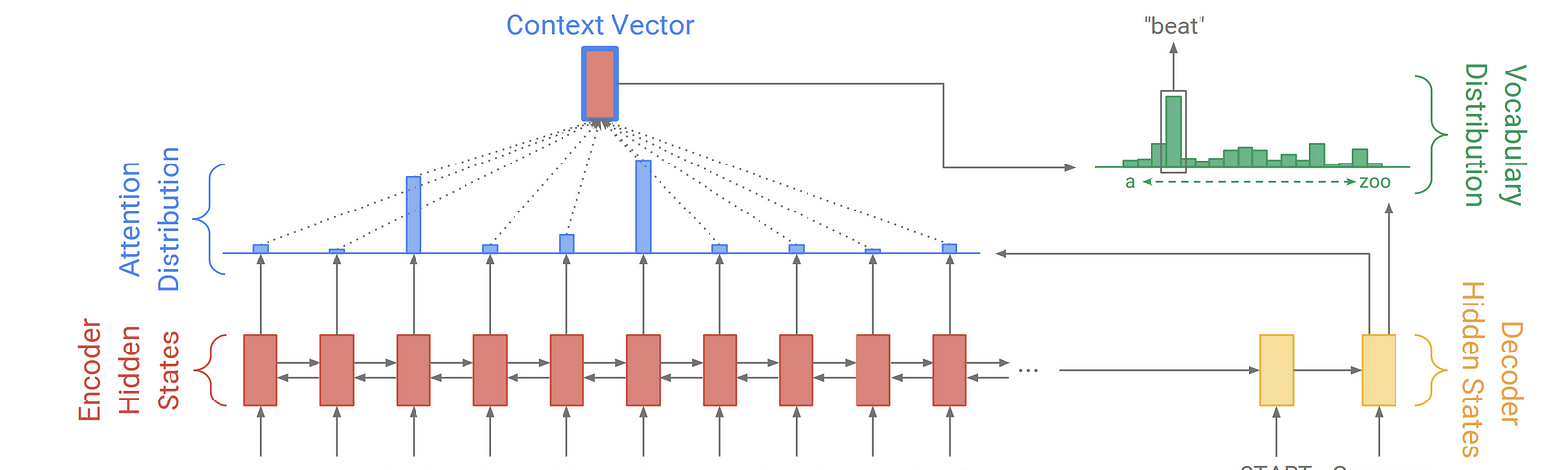
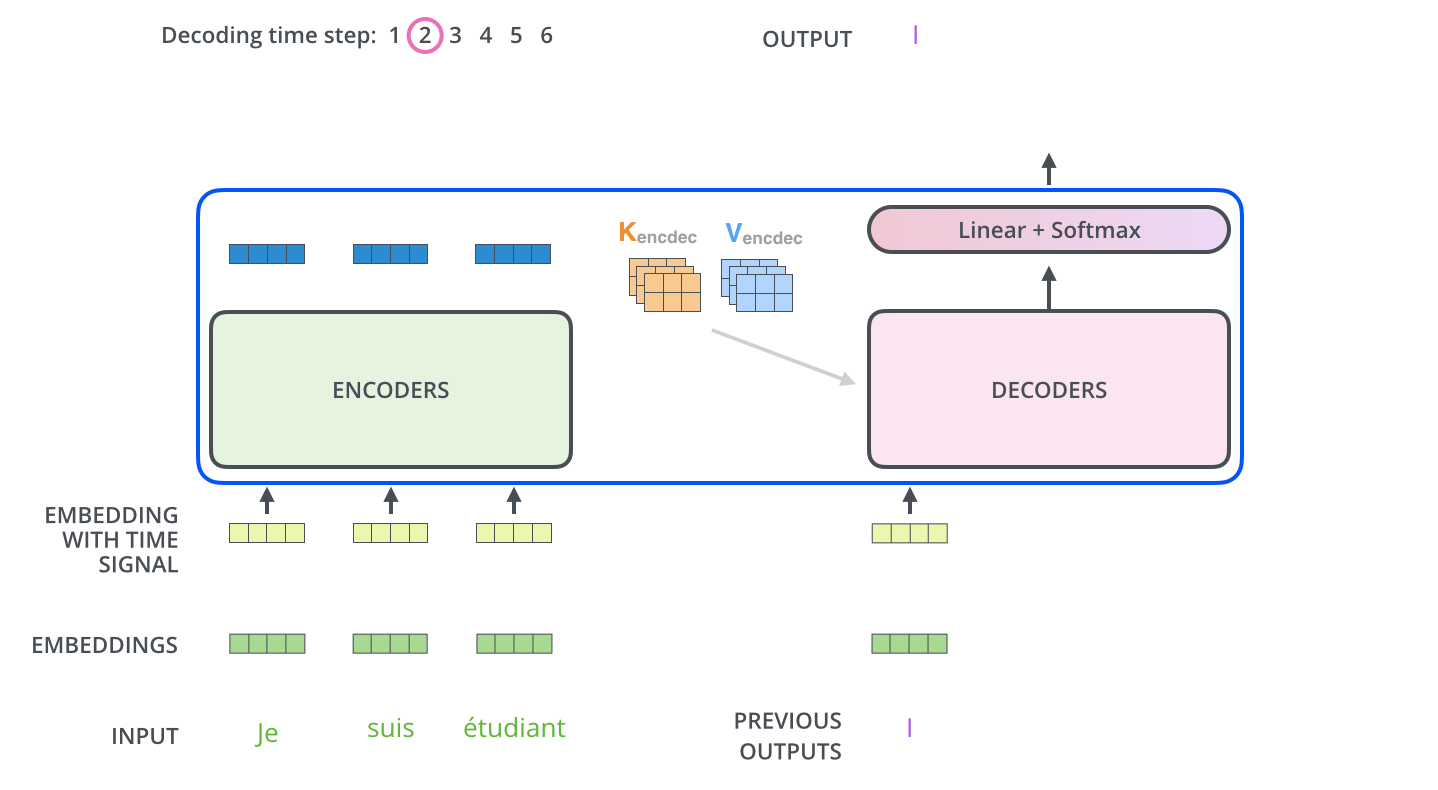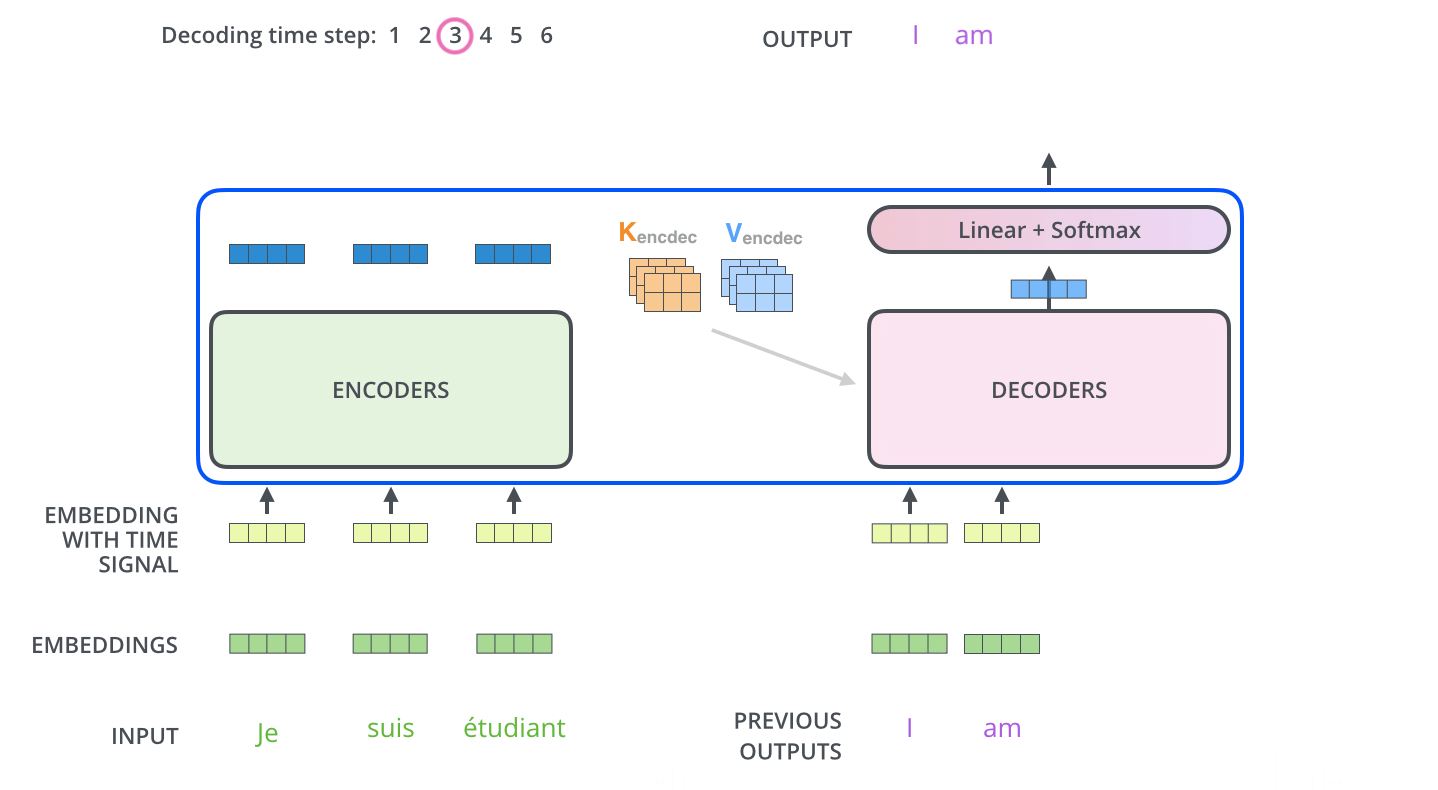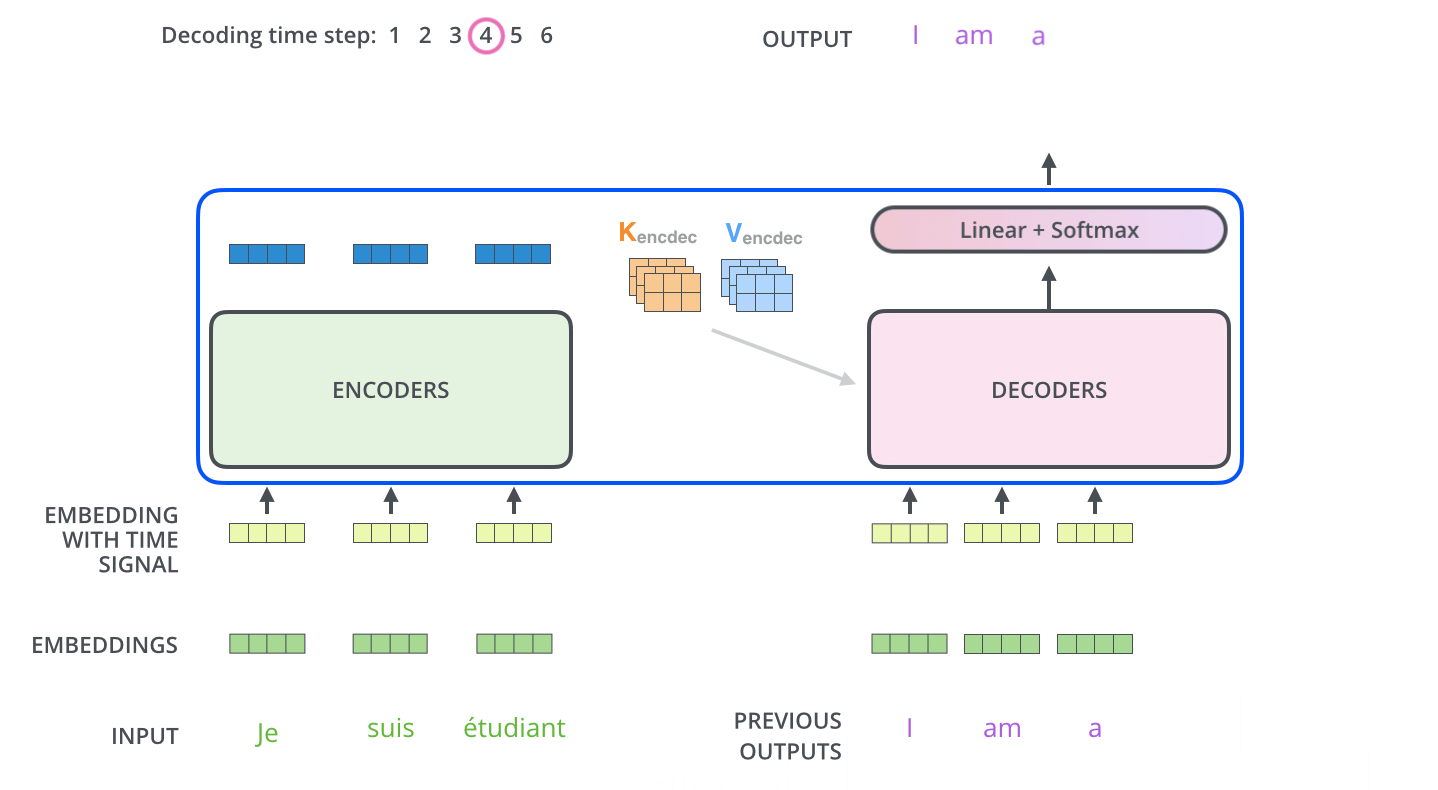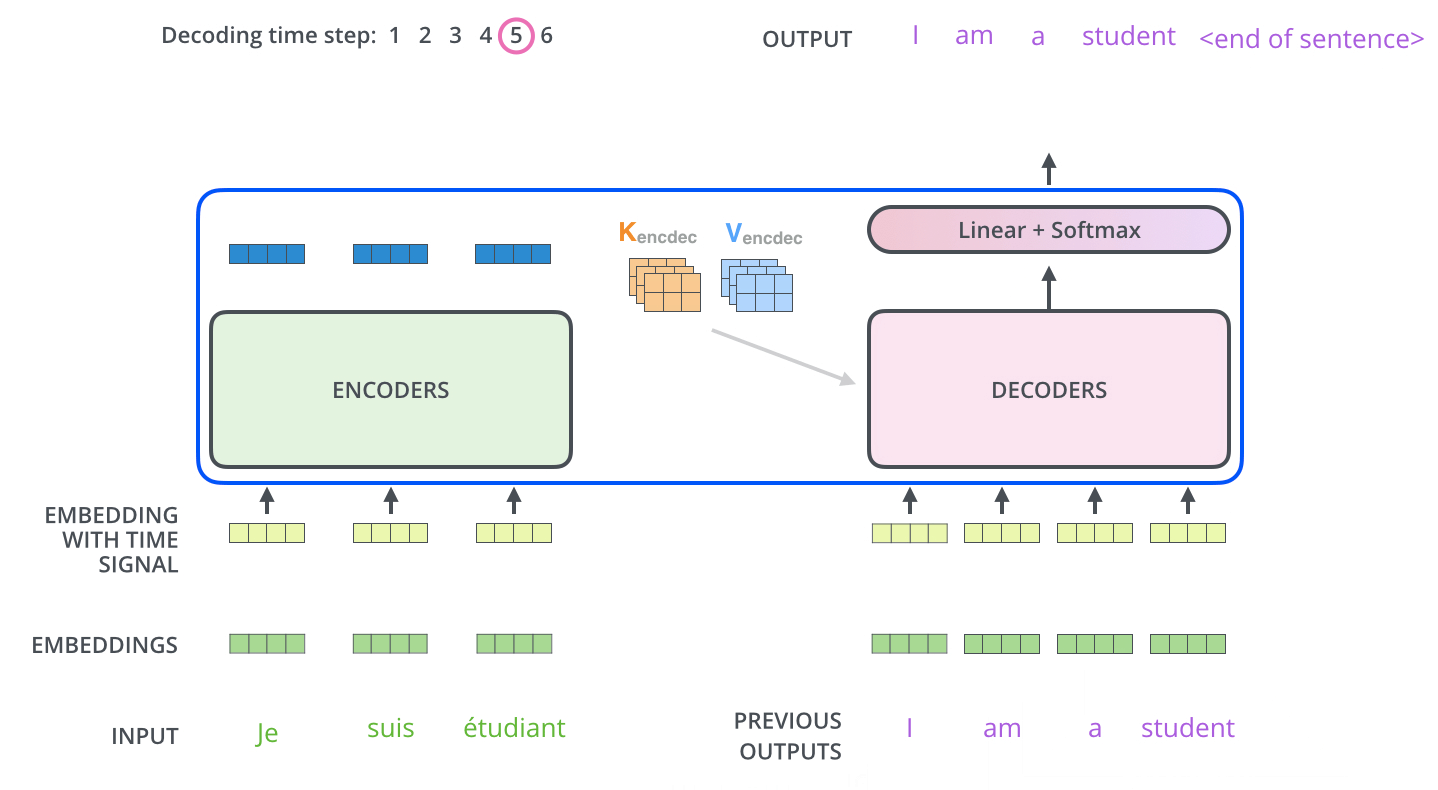
這裏記錄下很有意思的seq2se2的作法, 傳統的seq2seq會把Input seq 壓縮成某種訊息向量(Encoder), 在decoder時只會用之前產生的Outputs seq和Encoder 向量一起預測下一個字的機率
接續上篇的Transformer -encoder mask篇, 這裏繼續講解mask如何運作在Transformer -decoder中, 文章一開頭一樣會先對Transformer -decoder做個簡單介…
這篇會著重介紹實際使用Transformer Encoder時會遇到的序列長度問題, 也就是mask處理, 不過在文章的開頭還是會簡單介紹一下Transformer…
最早直接使用feed_dict的方式來輸入資料, 以前使用這個用法時都直接把所有資料儲存在記憶體, 大量的記憶體的使用量可能是最直觀的壞處,其他還有速度慢等等, 好處是方便和可以直接用print來debug
Tensorflow 2.0 新手向- 壹之型
Tensorflow 2.0 剛發佈的時候,其實就很興奮,像是 eager execution,還有一些 API 的改動,對於初學者來講也比較友善,而對習慣寫 python 的開發者也會覺得更 pythonic。