《Linux 執行時尋找 symbol 的流程以及 shared library 相關知識》著重在執行期 (Runtime) 的行為,這篇補充說明編譯和連結(Link) 的行為,以及用 gcc 產生 shared library 的相關指令。
網路傳輸時需要一些標頭檔決定封包如何傳送,所以封包帶的資料愈大愈划算。以 TCP 為例,TCP 和 IP 標頭檔都是 20 bytes,用 40 bytes 的標頭檔只傳 1 byte 就很不划算。TCP 設定封包所帶的資料上限稱為 maximum segment size (MSS),理論上我們希望它愈大愈好。
以下記錄和 MSS 相關的知識,懶得看的話只要記住一個結論: OS 都處理好了,沒事不要手癢亂改 MSS 的值。
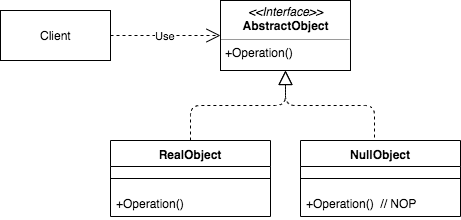
針對 Linux 和 ELF,這篇文章回答以下的問題:
使用 C/C++ 程式分成三個步驟: 編譯 (compile) → 連結 (link) → 執行 (載入 symbol)。了解每個階段的行為,才知道如何處理該階段的 undefined symbol。
-I
官網寫得簡潔又清楚,多數文件看官網即可。安裝 Redis 也很簡單,server 和 redis-cli 一包裝好,不需要用線上的 playground。推薦先看 FAQ,對 Redis 有個概念。
Redis 可以單機跑,也可以跑 cluster mode。本文若沒有特別提及,均是指兩者共同行為。
大學時讀過一遍,最近再讀一遍,發覺書中說的觀念仍然適用。工作經驗愈久,愈能認同書中所言。可能有些當時新穎的觀念,現在已被視為常識 (例如要用漸進式開發模型而不是瀑布模型)。也因為這樣,重看後其實沒學到什麼新東西,如同作者在《人月神話二十年後》自我調侃:
… 坐在我旁邊的那位陌生人正在看《人月神話》,而我一直在等,等看看他會不會有什麼反應,也許是一番話或某些表示。最後,飛機終於降落滑向了登機門,我不能再等了:
之前從軟體的角度寫過 memory barrier 的介紹。《Memory Barriers: a Hardware View for Software Hackers》則是從硬體的角度了解硬體設計者的需求,以及 read/write memory barrier 如何運作。我只有讀完前五章,後面用我理解的方式摘要這篇文章。本文的圖示都是從該篇文章取出來的。
記得剛接觸到設計模式 (Design Patterns) 時,有許多誤解,像是:
前一篇文章是以一個小例子從開發者的角度,從上層到下層說明 thread 之間何時會同步資料。這篇只從 C++ 的角度討論 C++11 訂的 API。
Architectures (e.g., x86, ARM) 為了提升效率,會作許多事,這裡借用《C++ and Beyond 2012: Herb Sutter — atomic<> Weapons》的圖:
strace 會列出程式執行的 system call,效率很好且不需要 debug symbol。我比較常用它找出影響程式行為設定檔的位置。
基本概念是開檔、讀取、寫入最後都會用到 system call,system call 數量不多,知道要用什麼 system call 作什麼事,就可以用 strace 觀察特定的 system call 得知很多資訊。比方說開檔一定要用 open,所以觀察 open 就能知道程式讀了那些檔案。
open
These were the top 10 stories published by fcamel的程式開發心得; you can also dive into yearly archives: 2016, 2017, 2018, 2019, 2020, 2021, and 2023.