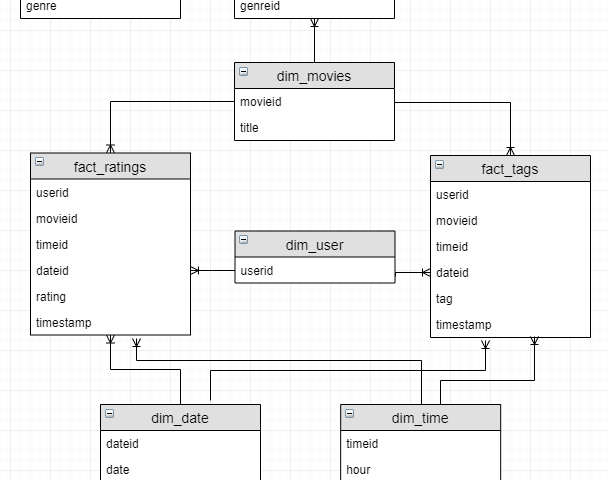
본 포스팅에서는 CloudHadoop(Spark)에서 제공하는 Apache Livy를 사용하여 Spark Job을 제출하는 방법을 설명합니다…
지난 글(Part.1)에서는 네이버 클라우드 플랫폼 Data Forest에서 Zeppelin 앱을 생성하여 Spark Job과 Hive 쿼리를 실행해…
네이버 클라우드 플랫폼 Data Forest는 빅데이터 처리를 위한 다양한 오픈소스 프레임워크를 제공합니다. 이번 페이지에서는 Data Forest에서…
오픈 데이터를 활용하여 Object Storage 데이터를 추출하고 변환하고 저장하는 작업을 이전 1부에서 수행하였습니다.
이번 시간에는 네이버 클라우드 플랫폼의 상품들을 활용하여 데이터를 저장하고, 저장된 데이터를 오픈소스 Apache Spark를 활용하여 ETL…