Resource: https://github.com/sdq/react-d3-dashboard
大数据时代一切皆可数据化,而人工智能的异军突起也在各个行业攻城略地。撇开纯理性的AlphaGo不谈,在感性的方面,DeepDream创作了大量的艺术作品,小冰发表了诗集,似乎在人工智能的攻势下,那些人类引以…
IPFS的全称是InterPlanetary File System星际文件系统,是一个点对点的网络超媒体协议。它的目标是成为更快、更安全、更开放的下一代互联网。
文本,尤其是中文文本,是一个高度抽象的对象,极为复杂且难以量化,这对大数据分析中发现文本中的关联性造成了阻碍,也是挖掘文本大数据中潜在价值所必须跨越的难题。而中文文本的可视化可以使普通人也能通过简单的交互体验从而发现文本中蕴藏的价值。本文结合互联网以及论文上相关知识,总结了一下中文文本可视化的一套可行方案与实施流程,共勉学习。
与英文文本不同,在进行文本处理的第一步时不得不面对的是中文文本分词技术,所谓分词是将完整的句子划分成若干独立的词汇。比如“我喜欢你“会被分词为“我”“喜欢”“你”。常采用的中文分词库为jieba,可以有效通过几种模式(最大概率法、隐式马尔…
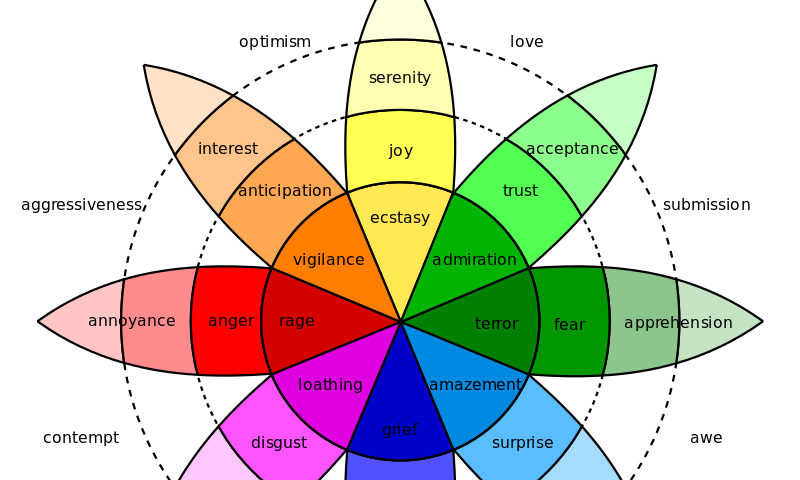
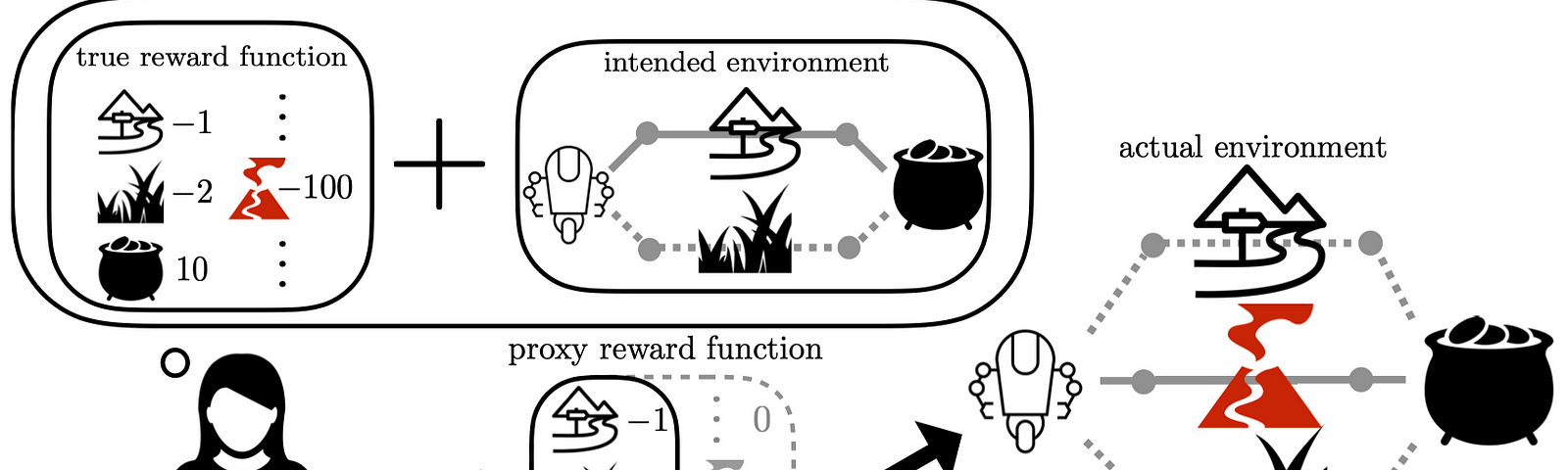
在强化学习的MDP模型中,对于Reward函数的设计一直是智能体能否完成目标任务的核心关键,同时也是一个非常复杂的课题。目前非常多的强化学习算法都应用在规则明确的游戏领域,正是因为在这些场…
抽时间写了一下swift上的向量与矩阵运算,使用的是原生的Accelerate框架,便于之后的开发。playground代码和更好的代码高亮可以我的github上找到。
import Foundationimport Acceleratetypealias Matrix = Array<[Double]>typealias Vector = [Double]
(翻译整理自Dieleman的博客)
针对不同用户推荐合适的音乐是每个音乐类软件都希望实现的目标。本文从传统的协同过滤方法的优缺点说起,引出一套基于音频信号的音乐推荐算法,并在最后对实现的深度神经网络进行可视化剖析,理解模型的运行原理。
协同过滤是音乐推荐的一种基础方法,基本原理是通过历史使用数据来判断用户的喜好。举个例子,如果有两个用户听了大量相同的歌曲,那他们的兴趣应该是基本类似的。从歌曲角度来讲,如果两首歌被同一组人群听过的话,那…
以太坊的使命是成为一个分布式的世界级计算机,取代传统的服务器集群。我们可以把它想象成一台全世界都可以使用的计算设备,并且是不能被停止与关闭的。这篇文章是以太坊路线图的初学者入门指南,解释在技术上如何工作的。
参考论文《On Approximately Searching for Similar Word Embeddings》原文链接 发表于ACL2016
相似性搜索的概念是在n维空间中通过比较数据之间的相似性,寻找与输入点最接近的目标点。该技术被广泛应用在数据库、信息检索、模式识别、数据分析等各个领域。
为什么要使用RxSwift?
我们所写的大量代码往往都围绕着外部的操作。当用户点击,我们需要通过IBAction来对其进行响应;当用户键盘位置发生变化,我们通过Notification来收取通知;当网络请求返回数据时,我们需要提供block来对该数据进行处理;属性发生变化时,我们使用KVO进行观察。所有的这一切都无意义地增加了代码的复杂程度。
是否会有一种具有一致性的系统,使我们的代码处理方式变得更好?RxSwift就是这样的一种系统。
These were the top 10 stories published by Explore, Think, Create; you can also dive into yearly archives: 2015, 2016, 2017, 2018, 2019, and 2020.