Ideas from this summary are taken from the Proximal Policy Optimization paper.
PPO offers two key improvements to policy gradient methods:
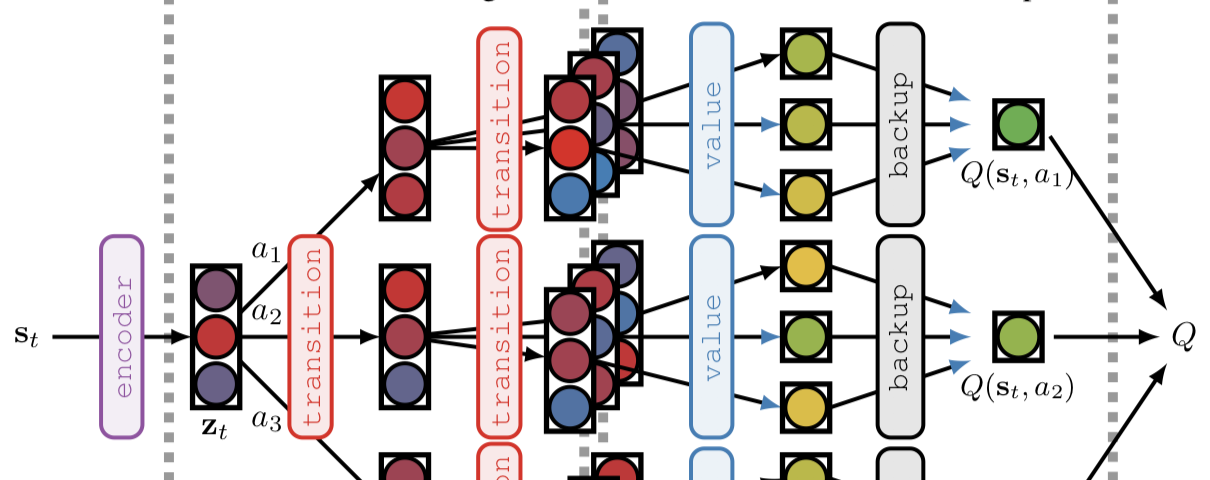
Ideas from this summary are taken from the TreeQN and ATreeC paper.
VPN is a deep reinforcement learning architecture that mixes ideas from both model free and model based methods. Generally model based methods learn environment dynamics so as to predict real observations, however, VPN attempts to learn a dynamics model that…