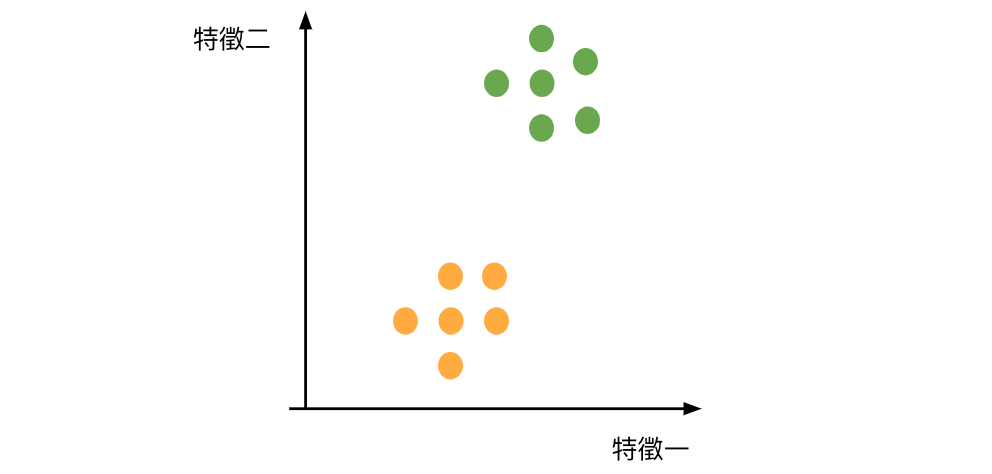
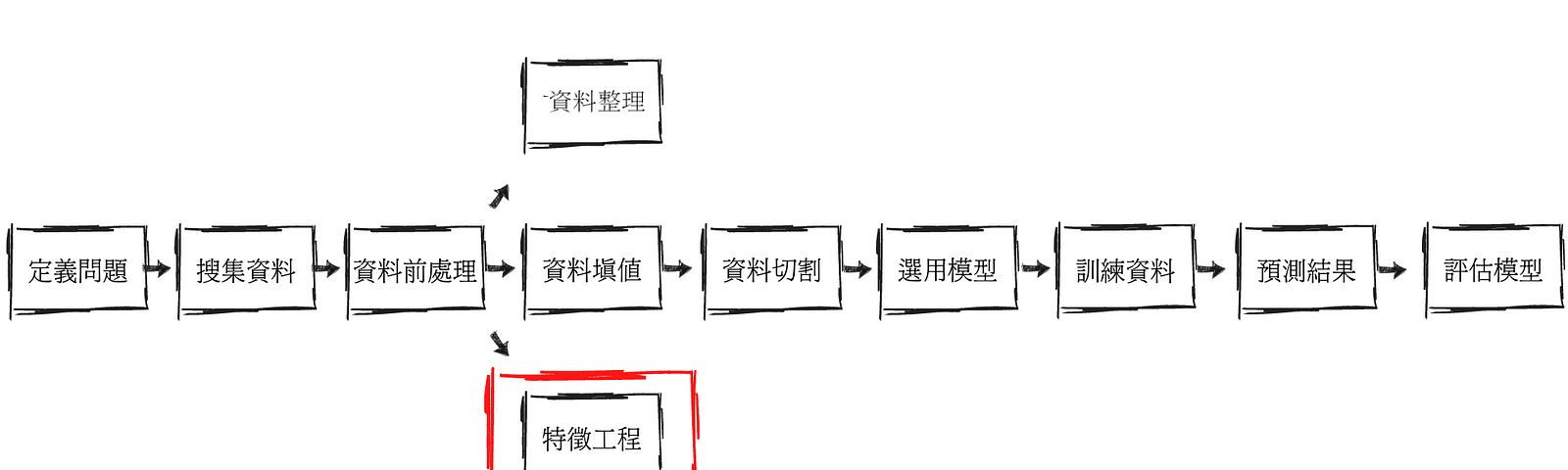
當資料欄位數過多時會導致模型效果不佳、運算耗時等問題,因此需要將資料進行降維,找出有代表性的特徵或是透過將多個欄位組合成一個特徵欄位的方式來達成。
☉前言☉歐式距離無法獲得的資訊?☉降維的種類☉流型學習☉t-SNA 演算法步驟☉困惑度 Perplexity☉總結☉實作☉參考資料
無論是要做資料分析或是機器學習,當我們取得資料時總會發現資料有缺失或不合常理的值出現,因此,在使用資料之前會需要對這些缺失值和異常值做處理才能使我們得到較好的結果,接下來就要為大家介紹缺失值和異常值的處理方法~
什麼是 EDA?EDA 流程實作 — FIFA World Cup 2022
前言 — 本篇文章將介紹在特徵處理中針對單一特徵的規一化 & 標準化、偏態的介紹與以及如何在 python 中使用這些方法,它們是機器學習中必不可少的一個重點,千萬不要錯過哦~
文/鄭雅綿、吳啓榮 共同編寫;主編/鄭雅綿
◈ 前言◈ 語法說明◇前置作業◇圖表設計◇常用圖表◇實際操作◈ 總結
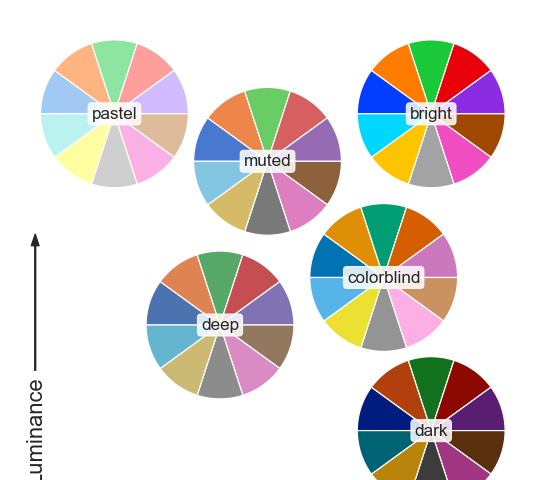
在科技不斷進步的時代下,數據量也逐漸龐大,資料呈現也成為數據分析不可或缺的一環,透過視覺化圖表的呈現可以有效傳遞數據分析想要表達的觀點和結果,本篇要介紹的是如何使用python視覺化函式庫Matplotlib來繪製視覺化圖表!
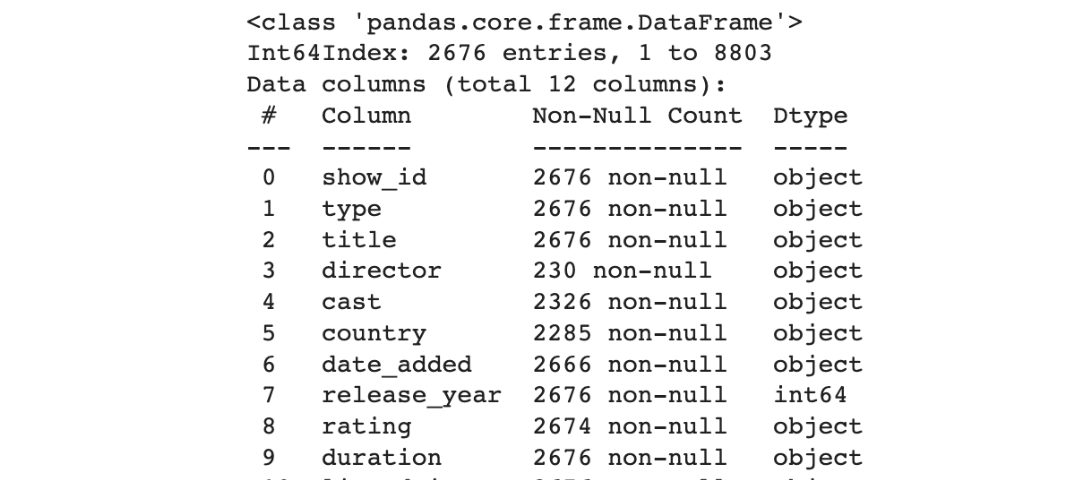
不論是資料分析或是建模,往往需要針對資料進行諸多處理,在 python 中最常使用的工具非 Pandas 莫屬。相較資料庫更方便,不需要處理完後再導入;跟 Excel…