Tensorflow 2.0 新手向- 壹之型
Tensorflow 2.0 剛發佈的時候,其實就很興奮,像是 eager execution,還有一些 API 的改動,對於初學者來講也比較友善,而對習慣寫 python 的開發者也會覺得更 pythonic。
從以前研究所到職場,其實會發現,資料科學所需要能力非常多, 從ETL至Model驗證等都必須都要有概念。尤其是資料科學同好,一定有看過以下Data Science能力圖:
這邊寫下之前讀到的筆記,基本上資料來源是李弘毅老師的投影片 Structured Learning: Sequence Labeling
工作一段時間後,也慢慢體會到職場有許多難處,常常會思考目前公司的產品是否符合消費者的需求,還是只是一群工程師閉門造車的自High產物。
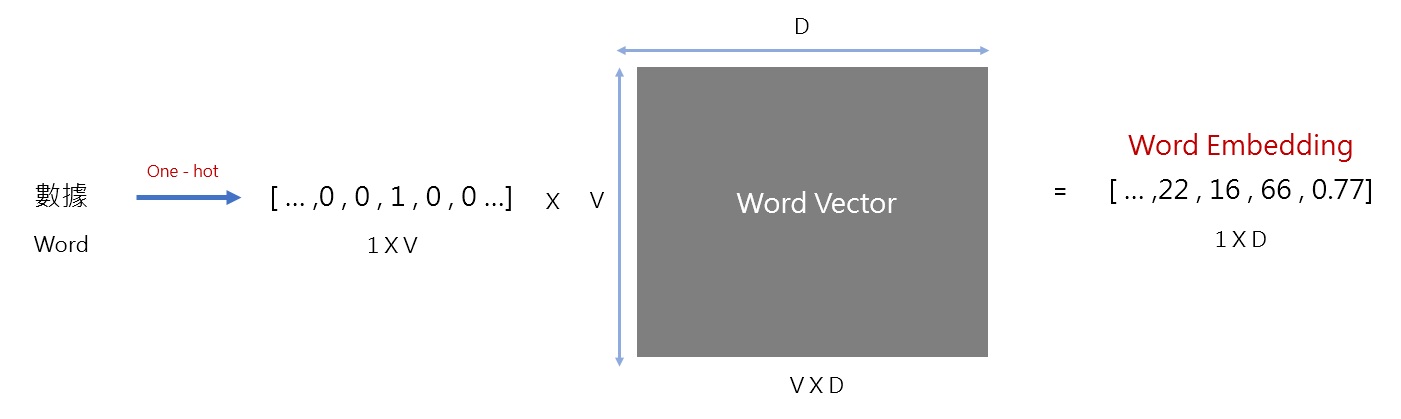
Word embedding (Word vector)是近年來文字探勘非常熱門的技術,主要是用來將文字轉換成向量,透過向量化可進行大量運算。
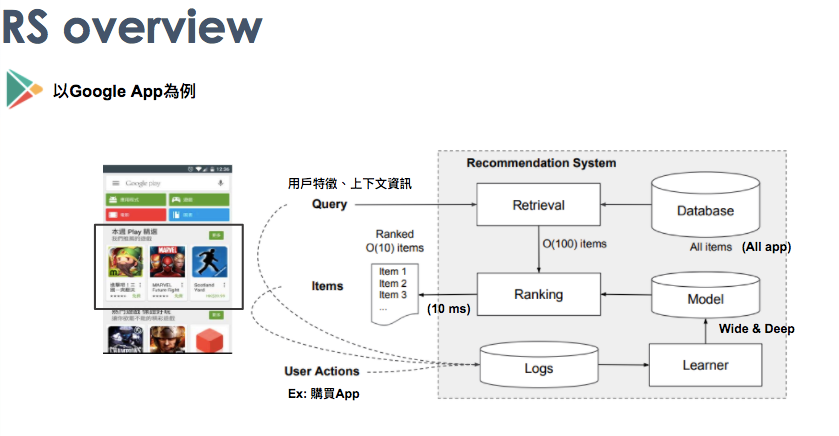
Wide&Deep for recommendation 這篇論文,主要是Google於2016年提出的推薦系統,並且當時應用於app推薦。
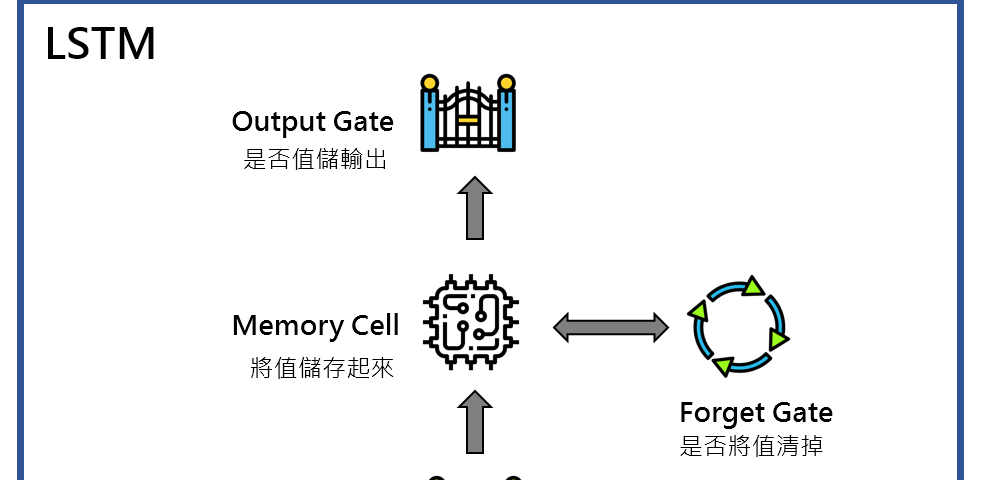
LSTM,是目前RNN(Recurrent Neural Network)中最常使用的模型。RNN主要是要解決時間序列的問題,一般的DNN,在inpute資料通常是沒有時間性的資料。而RNN透過將Hidden…
這是第二次參加KKTV舉辦的比賽,這次比賽主要是透過用戶觀測資料去預測用戶在未來的一週各個時段是否會觀劇?
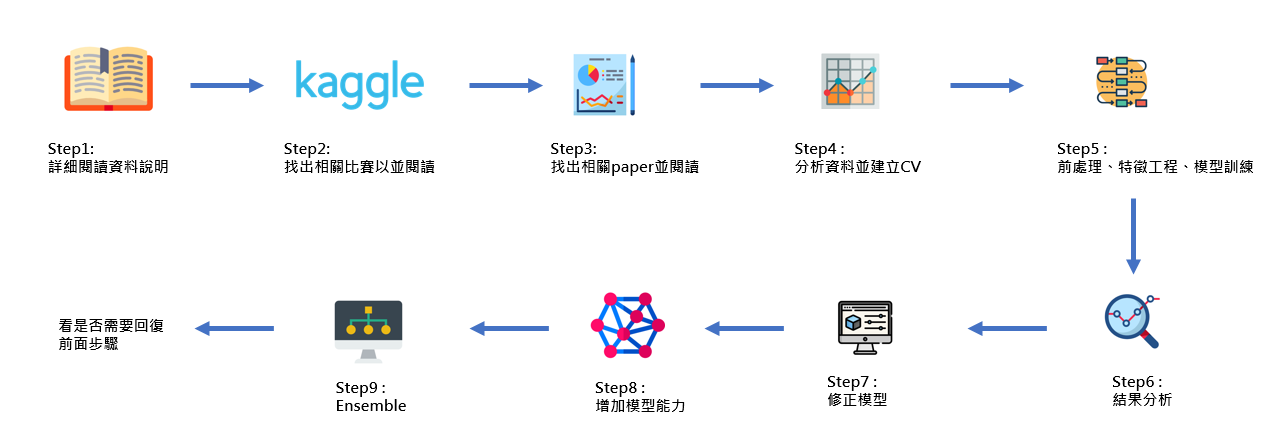
最近在Official kaggle blog所看到的一篇好文章,主要是訪問目前世界第一的kaggler,並將他比賽的心得分享給大家。下面會將訪問重點整理在下面,大家有興趣的可以看一下Top kaggler如何玩kaggle。